

DeepSeek-R1 Beats OpenAI's o1, Revealing All Its Training Secrets Out In The Open
A deep dive into how DeepSeek-R1 was trained from scratch and how this open-source research will accelerate AI progress like never before.


It’s incredible to see how far AI has progressed in the last decade.
Most of this progress came after Google released their groundbreaking paper called “Attention Is All You Need” in 2017.
It is then that other companies worked on the ideas discussed in this paper (the Transformer architecture) to build powerful LLMs.
One of these companies, OpenAI, before the release of transformers, was heavily focused on reinforcement learning (RL) and moved its trajectory towards LLMs, benefiting exponentially from Google’s open-sourced research.
Although OpenAI started as an organisation to democratise AI, it ended up making its research and products proprietary.
The last open-source model released by OpenAI was GPT-2, which was made publicly available in November 2019.
Since then, all their model advancements have been kept a secret.
With OpenAI releasing ‘o1’ a few months ago, they have really discovered something phenomenal and trained their newer LLMs to spend more time thinking (with long Chain-of-Thought and Reinforcement learning) when solving complex problems.
What are the exact “hows” of this process? — No one knows about them.
This changes now.
DeepSeek, a company based in China, has just released ‘DeepSeek-R1’, their latest model that is capable of reasoning in complex domains just like OpenAI’s o1.
This LLM is so good that it outperforms o1 on multiple mathematical and coding benchmarks.
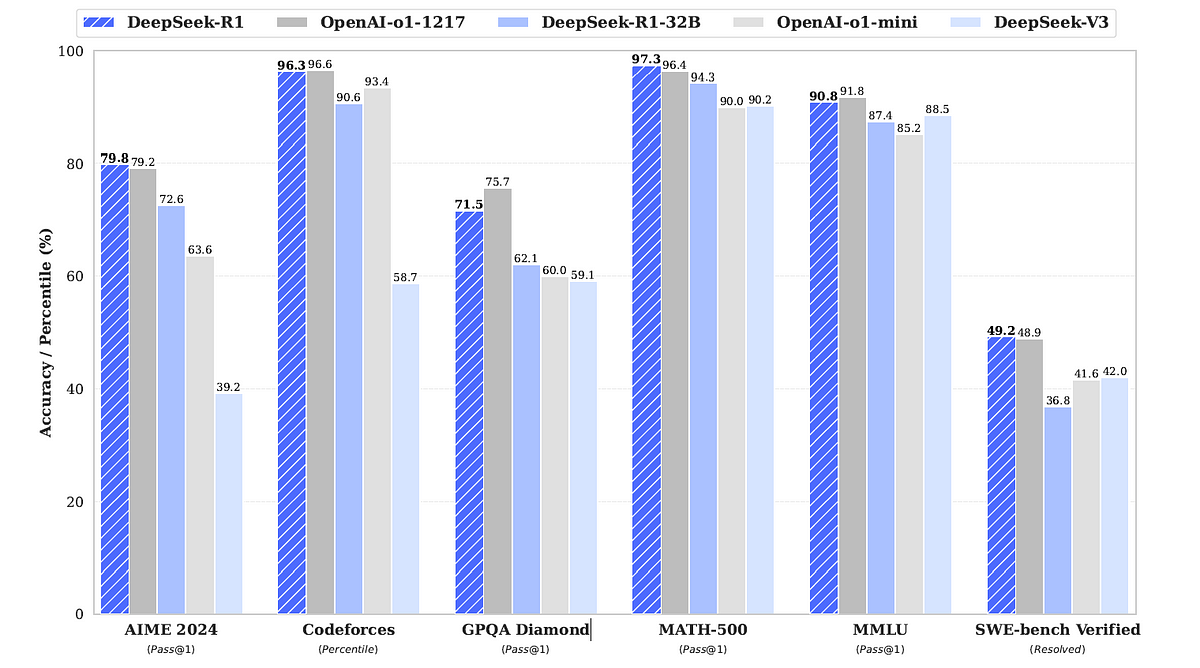
Even smaller LLMs distilled out of DeepSeek-R1 outperform models like OpenAI’s o1-mini and GPT-4o, and Anthropic’s Claude 3.5 Sonnet.
Here is a story in which we deep-dive into how DeepSeek-R1 was trained and how these findings will accelerate AI progress like never before.
Let’s begin!
But First, How Are LLMs Usually Trained?
LLM training starts with gathering a large amount of text data.
This data comes from publicly available sources on the web or, at times, from proprietary sources.
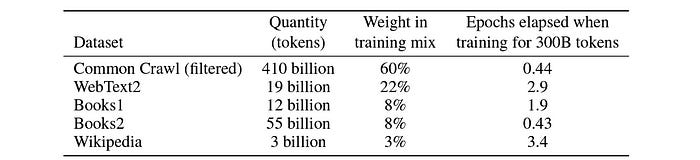
This data is cleaned, formatted, tokenized, and converted into text embeddings.
Next, an LLM is trained on this unlabeled data through self-supervised learning using powerful GPUs/ TPUs.
This step is termed Pre-training and helps to teach the LLM the structures of a language (grammar, semantics, and contextual relationships).
A pretrained LLM is then Supervised Fine-tuned (SFT) using relevant datasets to increase its performance on a specific task/domain (mathematical reasoning, coding, machine translation, and more).
The supervised fine-tuned LLM is then aligned to human preferences to prevent harmful response generation popularly using:
Reinforcement learning (RL) has also been used to improve Chain-of-thought reasoning in LLMs, as per an OpenAI blog describing o1.
And it is the secret sauce behind all the good that DeepSeek-R1 brings.
Let’s learn how.
Eliminating SFT With Reinforcement Learning
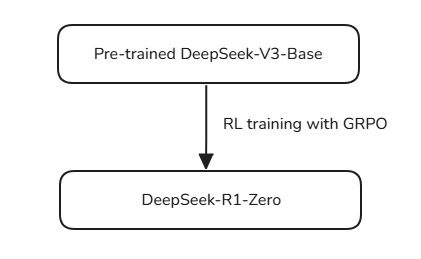
The experiments of the DeepSeek team start with DeepSeek-V3-Base as their pre-trained base model.
Next, instead of using SFT, they directly train it with RL to improve its reasoning performance.
This allows the model to develop its reasoning capabilities without any supervised data, self-evolving in the process.
Instead of the popular policy optimization algorithm called Proximal Policy Optimization (PPO) developed at OpenAI, they use an algorithm developed in-house called Group Relative Policy Optimization (GRPO).
The following section describes how they differ.
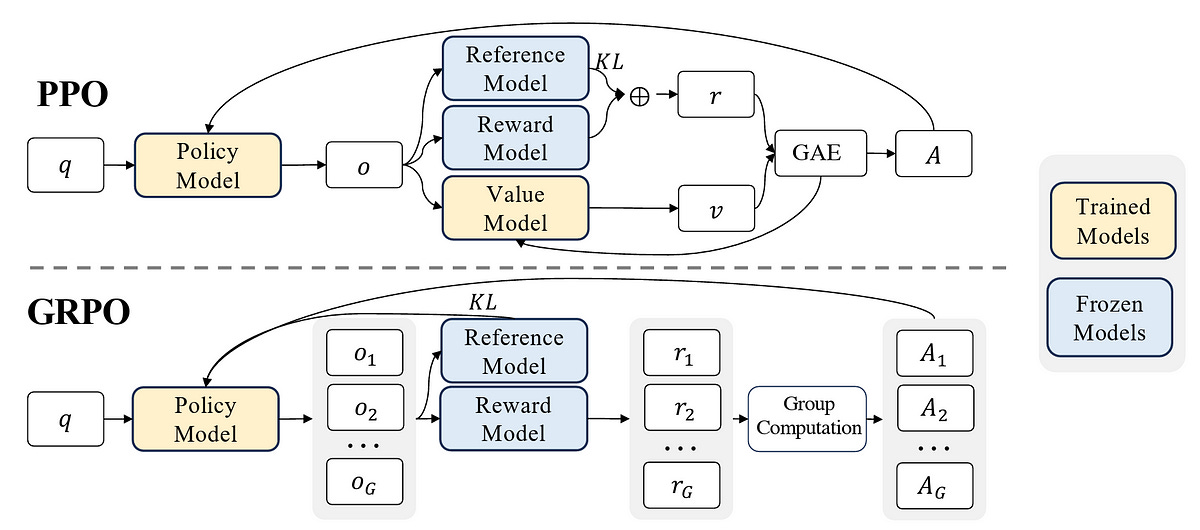
PPO vs. GRPO
In PPO, a policy model works alongside a critic/ value model to compute advantages A, using Generalized Advantage Estimation (GAE).
GRPO removes the critic/value model and computes advantages based on the relative rewards of a group of sampled outputs.
This reduces the computational complexity and training costs involved with RL.
Check out their equations, where GRPO directly integrates KL-divergence from the reference policy into the loss, while PPO penalizes it indirectly during reward calculation.
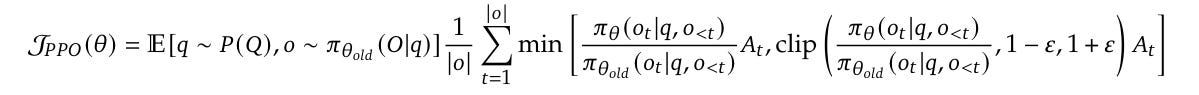
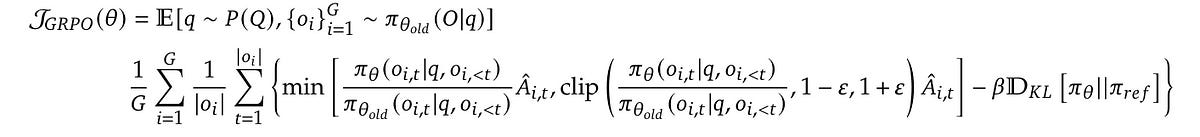
The differences are demonstrated further in the image shown below.
More Details On The RL Training
The reward given to a model determines the direction it will take to optimize itself.
Researchers use a rule-based reward system instead of an outcome/process neural reward model in this case of model training.
(This is because, with the neural reward model, the evaluation process is more ambiguous, can lead to Reward hacking, and requires significant computational costs for retraining it.)
Two types of rewards are combined to guide the RL process:
Accuracy reward: Given by an accuracy reward model based on whether the model’s (being trained) response is correct based on a rule-based verification.
Format reward: Given by a format reward model if the model in training follows a specific format in its responses (e.g. putting its thinking process between
<think>and</think>tags).
A template guides the base model (DeepSeek-V3-Base) to adhere to instructions while training.
The template makes sure that the model first outputs its reasoning process (within <think> and </think> tags), followed by the answer (within <answer> and </answer> tags).
This template is intentionally kept simple so that the model explores and evolves based on what it finds best (instead of prompting the model to follow a specific reasoning strategy).

Training the base model this way leads to DeepSeek-R1-Zero.
The following flowchart summarises the training process.
How Good Is DeepSeek-R1-Zero?
As the RL training progresses, DeepSeek-R1-Zero’s first-pass (pass@1) average accuracy on the AIME (2024) increases from 15.6% to 71%.
This is close to that of OpenAI o1's.
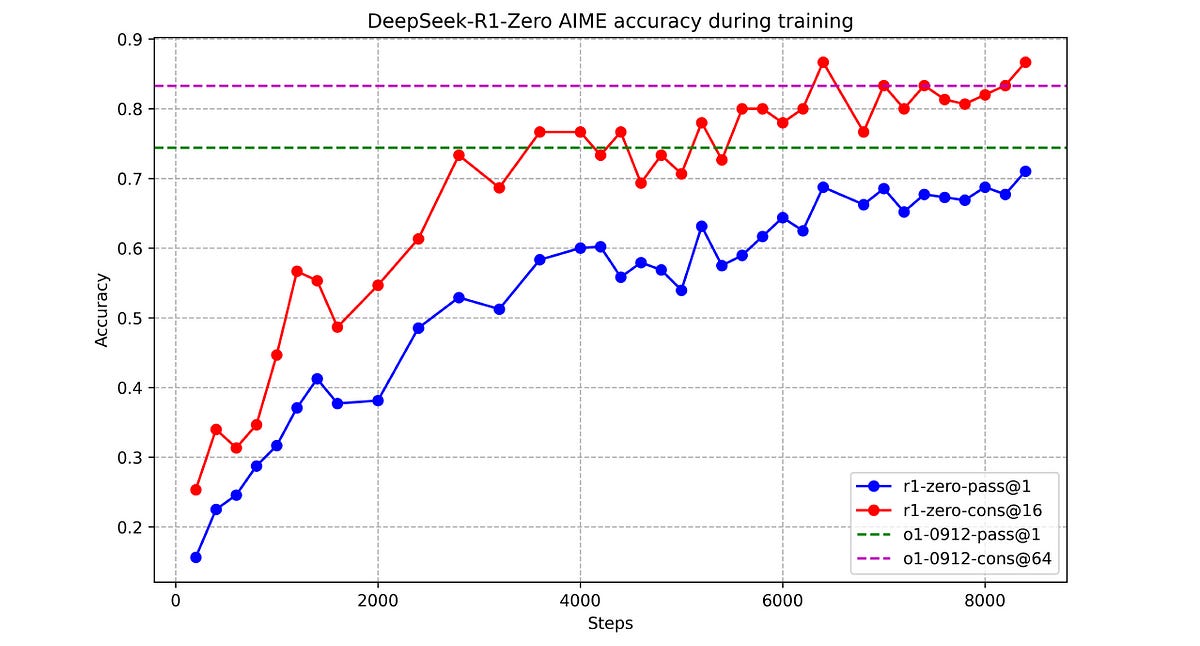
Two metrics compare the accuracy of these two models.
pass@1: This is the probability that the model’s first output for a given query is correct.const@n: This metric involves generatingnresponses for a given query and then using majority voting to determine the final answer.
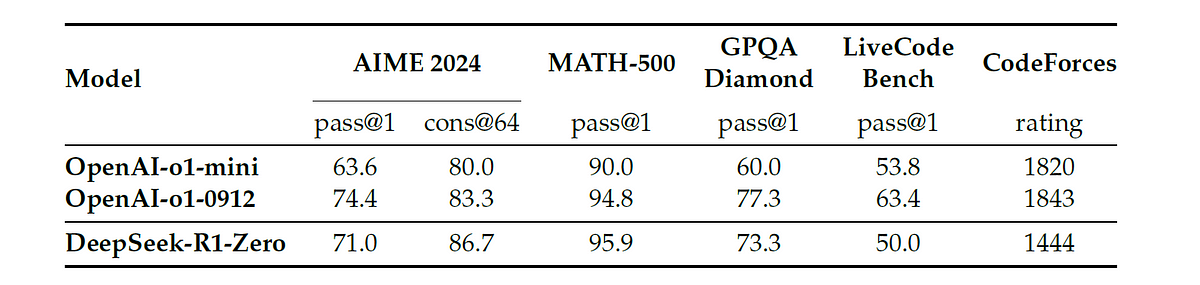
The results show that DeepSeek-R1-Zero beats OpenAI o1 on the cons@64 metric on AIME 2024 (83.3% vs 86.7% accuracy)!
Some Interesting Insights Noted During RL Training
With more and more RL training, the researchers observe that the model learns to solve increasingly complex problems by increasing test-time computation and generating thousands of reasoning tokens to think through in depth.
Behaviours like Self-reflection (where the model revisits and re-evaluates its previous steps), backtracking, and exploration of alternatives, naturally emerge as the model interacts with the RL environment.
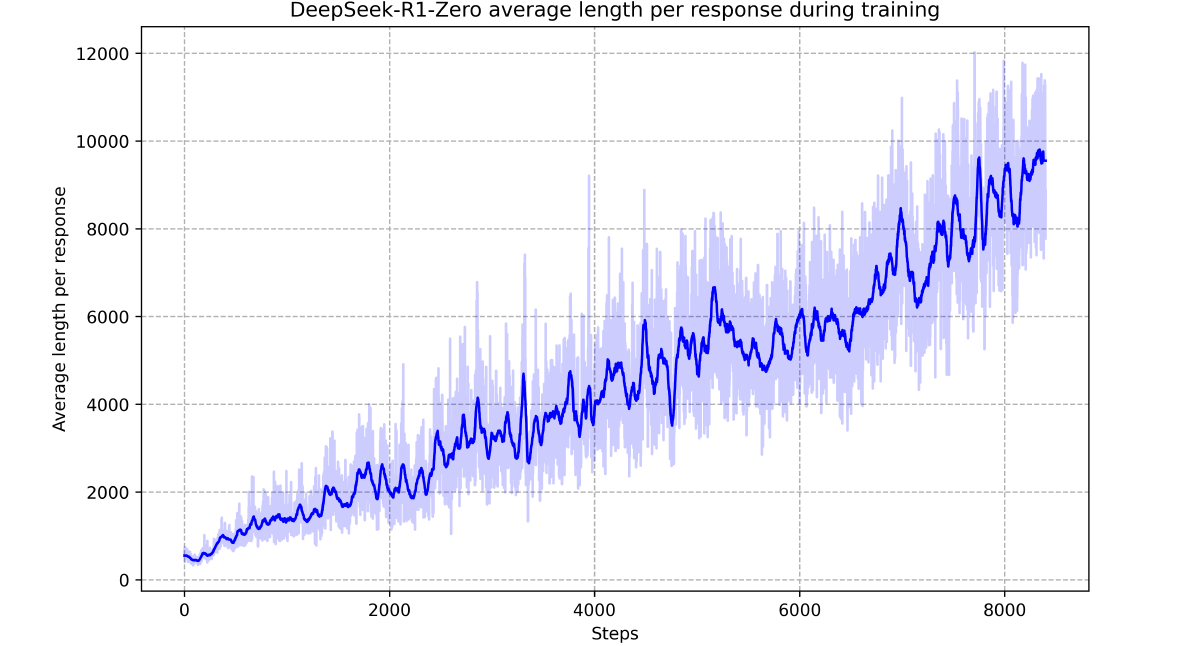
An interesting moment occurs when an intermediate version of the model decides to take more time to think and reevaluate its initial approach while solving a complex mathematical problem.
It looks like the model suddenly realises that it can think better and flags an “aha moment”!

But DeepSeek-R1-Zero Is Not Perfect
Although pure RL training is very powerful for the emergence of reasoning approaches in the model, avoiding SFT altogether leads to a few issues.
DeepSeek-R1-Zero mixes different languages and lacks appropriate formatting, leading to poor readability of its reasoning processes.
To ensure that the generated responses are clear and coherent, researchers further experiment by training the base model with SFT before the RL.
Will SFT Before RL Build A Better Model?
To test out this approach, researchers first collect a small amount of long Chain-of-Thought (CoT) data. (They call it “Cold-start data”.)
This data comes from various sources:
By few-shot prompting different LLMs for producing long CoT examples
By prompting different LLMs to generate detailed answers to queries with reflection and verification
By gathering well-readable outputs from DeepSeek-R1-Zero
Next, all this reasoning data is filtered out and refined with the help of human annotators.
This refined long CoT data has a pre-defined output format as follows:
|special_token| <reasoning_process> |special_token| <summary>where:
<reasoning process>is the CoT for the query<summary>is the summary of the reasoning results at the end of each response
The DeepSeek-V3-Base model is finally supervised fine-tuned on this long CoT data.
Further RL To Improve Reasoning In The SFT Model
After SFT, the model undergoes the same RL training process as previously used to train DeepSeek-R1-Zero.
However, this time, a new language consistency reward is introduced to the overall model reward to avoid the language mixing problem.
This reward is based on the proportion of words in the CoT that belong to the target language, with the model receiving a higher reward for using more words in the target language in its response.
The overall RL training reward is obtained by directly summating this reward to the rewards discussed while training DeepSeek-R1-Zero.
The aim here is to improve model reasoning while still keeping the response language clear and coherent.
This part of the RL training is termed Reasoning-oriented Reinforcement Learning.
(The ablation experiments tell that making the results more human-readable leads to slightly degrading the model’s performance, which is a very interesting point to note.)
SFT For Further Iterative Self-Improvement
Once this step is completed, the resulting model serves as a checkpoint to obtain more data for further supervised fine-tuning itself.
This data is in the form of:
Reasoning data: 600k reasoning-related (in math, code, and logic) training samples are obtained with Rejection sampling by prompting the above model checkpoint to generate multiple reasoning trajectories (long CoTs) and rejecting the inappropriate ones using either predefined rules or a generative model (DeepSeek-V3)
Non-reasoning data: 200k training samples are obtained by prompting DeepSeek-V3 or from the SFT data used when training DeepSeek-V3.
These are not related to reasoning but to tasks such as writing, factual question-answering, self-cognition and language translation.
These 800k samples in total are further used to supervised fine-tune the model.
Aligning The Model With Human Preferences
Note that while the above steps focus on reasoning and non-reasoning tasks, the model still needs to be aligned with human preferences for it to become harmless and helpful.
This is done with a secondary reinforcement learning (RL) phase.
To align its reasoning responses to human preferences, rule-based rewards are used, similar to what we previously discussed while training DeepSeek-R1-Zero.
For non-reasoning responses, a human-preferences-aligned reward model built on DeepSeek-V3 is used for its RLHF training.
This completes the training of DeepSeek-R1.
The following flowchart describes the complete process.
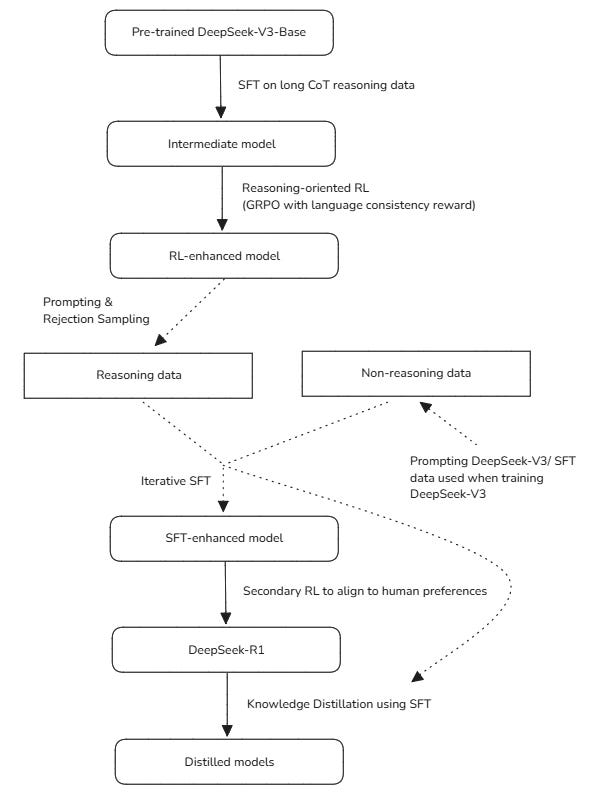
Distilling DeepSeek-R1 To Smaller Models
If you’re new to Knowledge Distillation, it is a technique in which a large and complex model (Teacher model) is used to train a smaller, simpler, and more memory-efficient model (Student model).
The aim of the process is to transfer the knowledge of the Teacher model to the Student model so that it can be deployed in a resource-constrained environment while still functioning at par with the performance of the Teacher model.
Remember the 800k training samples obtained from the DeepSeek-R1 model checkpoint previously?
These are used to distil multiple Qwen and Llama models using supervised fine-tuning.
The following base models are distilled in the process (with the resulting model shown in brackets):
Qwen2.5-Math-1.5B (resulting in DeepSeek-R1-Distill-Qwen-1.5B)
Qwen2.5-Math-7B (resulting in DeepSeek-R1-Distill-Qwen-7B)
Qwen2.5-14B (resulting in DeepSeek-R1-Distill-Qwen-14B)
Qwen2.5–32B (resulting in DeepSeek-R1-Distill-Qwen-32B)
Llama-3.1–8B (resulting in DeepSeek-R1-Distill-Llama-8B)
Llama-3.3–70B-Instruct (resulting in DeepSeek-R1-Distill-Llama-70B)
Note that no RL training takes place for distilled models.
How Good Is DeepSeek-R1?
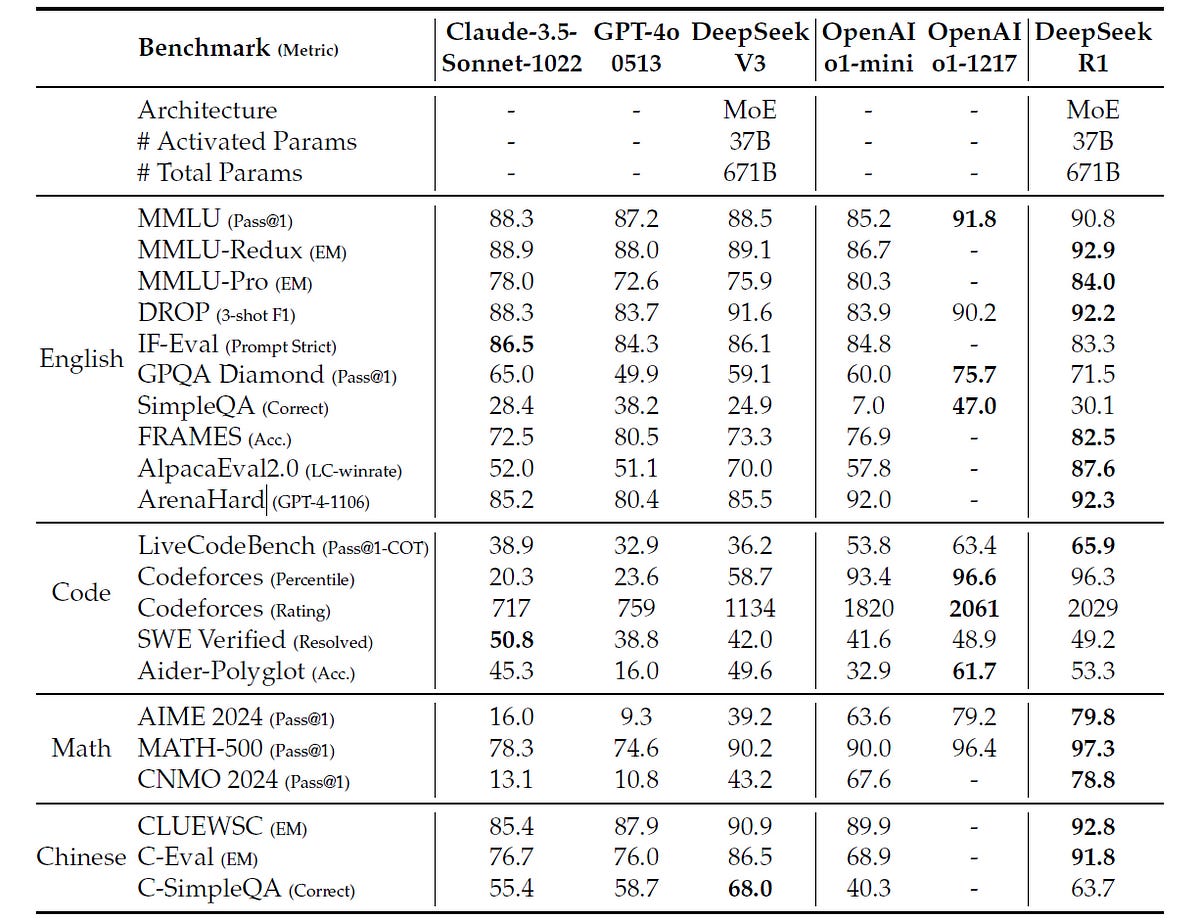
DeepSeek-R1 outperforms DeepSeek-V3 on:
Education-oriented knowledge benchmarks (MMLU, MMLU-Pro, GPQA Diamond)
Long-context-dependent question-answering benchmark (FRAMES)
Factual benchmark (SimpleQA)
Writing tasks and open-domain question answering (evaluated with AlpacaEval2.0 and ArenaHard) where it generates comparatively concise results
It is also excellent at following format instructions, as shown by its impressive performance on the IF-Eval benchmark.
Its performance is on par with (or superior to) OpenAI o1 on:
Coding benchmarks (LiveCodeBench, SWE Verified and Codeforces)
These results are such a big win for open-source models!
How Well Do The Smaller Distilled Models Perform?
Different Qwen and Llama models distilled with the outputs of DeepSeek-R1 also produce astonishing results compared to other popular LLMs of similar capabilities.
DeepSeek-R1-Distill-Llama-70B significantly exceeds OpenAI o1-mini (and other competing LLMs) on most benchmarks.
Similarly, DeepSeek-R1-Distill-Qwen-32B outperforms others, and specifically, OpenAI o1-mini on the AIME (2024) benchmark is the first pass accuracy (pass@1).
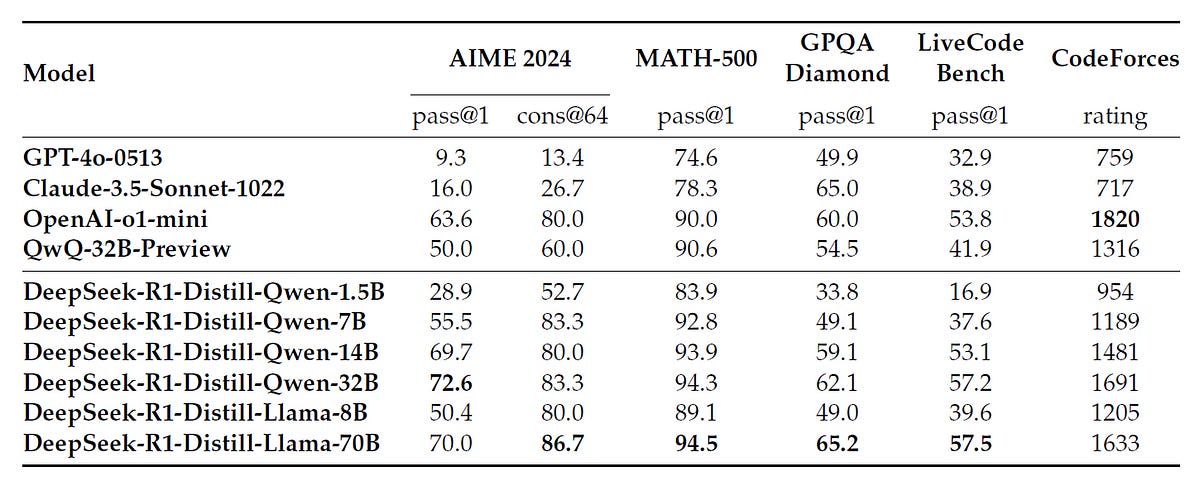
The surprising point to note is that these results are just after SFT, which shows how powerful DeepSeek-R1 is in imparting its knowledge.
You must be wondering what happens when we train these smaller models with the RL process used with DeepSeek-R1-Zero instead of just distilling them.
The researchers had this in mind as well.
To answer this, they RL trained the Qwen-32B model using math, code, and STEM data to create DeepSeek-R1-Zero-Qwen-32B.
This model was powerful enough to perform at par with QwQ-32B-Preview, the advanced reasoning model from the Qwen series.
However, DeepSeek-R1-Distill-Qwen-32B, which is distilled from DeepSeek-R1, performs significantly better than it and QwQ-32B-Preview across all benchmarks!
This shows how powerful this process of knowledge distillation from large and more intelligent models is!

How Much Did It Cost To Train DeepSeek-R1?
DeepSeek-R1 has 671 billion parameters and is based on a Mixture-of-Experts (MoE) architecture (just like its base model, DeepSeek V3, upon which it is built).
Although the original research paper does not describe the cost of training it, I’m quoting the estimates from a Nature published news article as such:
“Experts estimate that it cost around $6 million to rent the hardware needed to train the model (V3), compared with upwards of $60 million for Meta’s Llama 3.1 405B, which used 11 times the computing resources.”
The cost of training GPT-4 was likely $100 million, and the o1 training costs remain undisclosed (Maybe 10–20x more? Idk).
Compared to these, the training cost for DeepSeek-R1 feels like spending pennies, even if it costed 10 times more than DeepSeek-V3.
For end users, it costs $60 / 1M output tokens to use o1.
For DeepSeek-R1, this price is a mere $2.19 / 1M output tokens.
In other words, using OpenAI’s o1 is 27 times more expensive than DeepSeek-R1.
But DeepSeek-R1 Isn’t Perfect. Is It?
No, the model is not the best in each and every task out there.
It falls short of DeepSeek-V3 in the following tasks:
Function calling
Multi-turn dialogues
Complex role-playing
JSON output generation
It also isn’t much better than DeepSeek-V3 on software engineering benchmarks.
The reason is that it has not been trained with large-scale RL in these tasks.
The model is also optimized for Chinese and English and might still use these languages for reasoning and responses, even if the query is in another language.
It is also seen that few-shot prompting degrades the model performance.
Therefore, for the best results, it is recommended that one directly describe the problem and specify the output format using a zero-shot prompt.
DeepSeek Changes The AI Building Game Forever
This research on DeepSeek-R1 completely changes how LLMs are trained and is inspiring multiple AI researchers worldwide.
Hugging Face has already released its open-source reproduction called Open-R1.
Soon, multiple projects will sprout from it and grow big, highlighting the true power of open source over proprietary AI.
I’m excited for what’s coming ahead.

Further Reading
Source Of Images
All images are obtained from the original research paper unless stated in the captions.
