

A Hands-On Guide To Federated Machine Learning With 'Flower'
A deep dive into Federated Learning and training an ML model to detect eye diseases using the Flower framework.


We are running out of data to train AI models on.
There is an estimated range of 40 to 90 trillion high-quality training tokens available publicly, with the popular FineWeb dataset consisting of 15 trillion tokens, for the English language.
For reference, the recently announced Llama 4 was pre-trained on more than 30 trillion tokens from text, image, and video datasets, which is more than double the number for Llama 3.
This gives us an idea that we are just a few years away from our training data hitting a limit.
But is that really the real limit? What about private datasets?
These datasets could be 10 to 20 times (or more) larger than the publicly available ones, with around 650 trillion tokens in all stored messages, and about 1200 trillion in emails.
Surprisingly, much of the data collected privately is never even analysed by companies, and therefore termed Dark data.
Now, think about all the data stored by government organisations, hospitals, law firms, financial institutions, on user devices, and others.
I agree that this data is sensitive, and strong data protection laws exist on how it should be handled.
Much of this data could be too risky to train ML models on, but a huge chunk can definitely benefit humans and organisations.
What if there is a way to train ML models using sensitive compliance-protected data from multiple organisations without sharing the data itself?
This is where Federated Machine Learning comes in!
This is a lesson where we deep-dive into what it is and how it works, and then code up a Federated learning pipeline to train an ML model that can detect eye diseases using data from multiple healthcare organisations, securely.
Let’s begin!
But First, What Really Is Federated Learning?
To understand what Federated learning is, let’s first consider the conventional ML model training approach.
As an example, we want to train an ML model that can detect cancer from CT scan images.
The first step in the process would to collect CT scan images of normal and cancer patients from multiple hospitals based in different geographical locations.

The reason for selecting diverse data sources is to:
Increase our sample size, and
Reduce bias that can arise due to different factors, including demographic, specialist, and institutional factors
This makes our model generalisable even to under-represented groups in the training dataset.
Once this data is available on a central, powerful server, we will use it to train our model on the data and evaluate it.

Can you identify issues with this approach which make executing it almost impossible?
Firstly, sensitive healthcare data is highly regulated by laws (such as GDPR / HIPAA), making transferring this data to a centralised server tough.
Next, the compute and storage resources available on the centralised server must be sufficient enough to handle this data and training, which makes this approach quite expensive.
What if we could take a reverse approach and instead of moving the data to the training, we could move the training to the data?
This is what Federated learning does.
Federated learning is a machine learning technique in which multiple organisations can collaborate in a decentralised manner to train an ML model without sharing their datasets.
Here are the steps that we take when using this approach:
A base/ global model is initialized on a central server.

2. This model’s parameters are sent to servers in participating organisations (called Clients/ Nodes) containing local data.

3. Each client trains the model on its local data for a short time (not until model convergence, but for a few steps/ one or a few epochs)
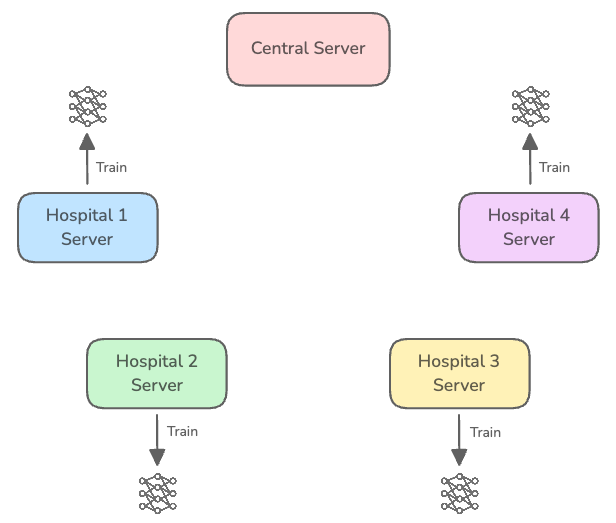
4. After training locally, each client sends their model parameters or the accumulated gradients back to the central server.

5. Since each client’s parameters are different from others due to their model being trained on different local datasets, these are combined using a process called Aggregation. The results after Aggregation are then used to update the base/ global model’s parameters.
Multiple techniques can be used for Aggregation, and one of the popular ones is called Federated Averaging.
This is where the updates from different clients are averaged, weighted by the number of examples/ data points each client had for training.

6. The updated base model’s parameters are sent back to the clients, and this training process is repeated over and over again until a fully trained model is obtained.

Did you notice the advantages that Federated learning brings in?
Firstly, the data remains where it was generated and is never transferred to a central location, which makes this approach decentralised.
