

A Human Brain Inspired RAG Approach Has Reached The New State-of-the-Art
A deep dive into 'HippoRAG' — a faster, cheaper, and better-performing framework inspired by long-term human memory that outperforms the current state-of-the-art RAG methods


Human brains store immense amounts of knowledge to thrive in their environment.
New experiences continuously update this knowledge without losing track of the previous.
LLMs, despite being remarkably intelligent, lack such continuously updating long-term memory.
Researchers have developed many methods to update LLM memory, such as Fine-tuning, Knowledge Editing and currently popular Retrieval augmented generation (RAG), but these are far from perfect.
One could argue that the human brain reached this point through millions of years of evolution. Conversely, training a high-performing LLM takes only a few months.
But we don’t have a million years to wait for this magic to happen.
How about we borrow and apply these biological insights to our current LLMs?
A recent research pre-print in ArXiv does exactly this.
These researchers developed a new framework called ‘HippoRAG’ by drawing inspiration from how the human brain’s two regions — the Neocortex and Hippocampus, process ever-updating long-term memory.
When tested on Multi-hop question-answering tasks, HippoRAG outperforms the current state-of-the-art RAG methods by up to 20%.
It performs Multi-hop reasoning in a single retrieval step better than the iterative state-of-the-art IRCoT (Interleaving Retrieval with Chain-of-Thought Reasoning) approach while being 10–30 times cheaper and 6–13 times faster.
Here is a story in which we deep-dive into how this biologically inspired framework works and how it surpasses the current RAG approaches to emerge as the new state-of-the-art.
Let’s begin!
Let’s Talk A Bit About RAG
RAG, or Retrieval Augmented Generation (RAG), is an information retrieval technique that allows an LLM to produce more accurate and up-to-date responses using private datasets specific to the use case.
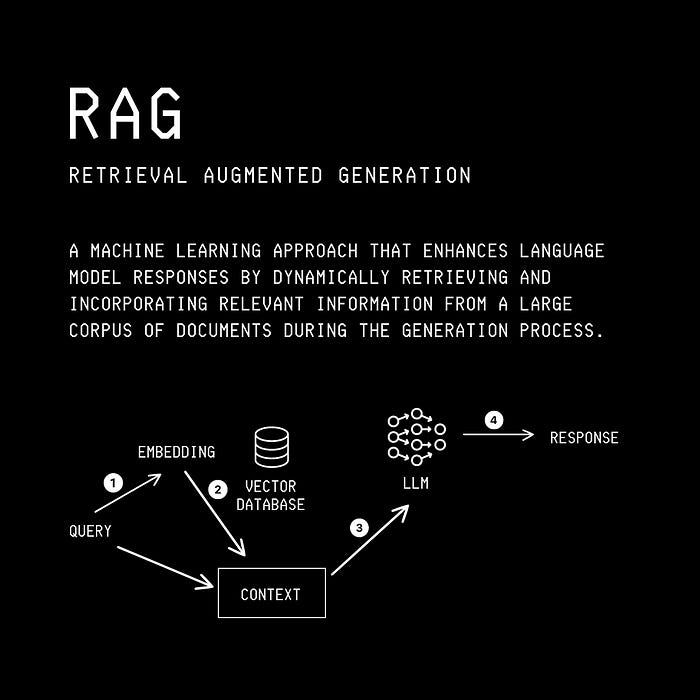
RAG works by chunking a dataset and then indexing these chunks in a vector database for efficient retrieval during the generation process.
Conventional RAG performance greatly suffers on important real-world tasks in Law, Medicine, and Science and on Multi-hop question-answering tasks.
This is because these tasks involve integrating knowledge across different chunks.
Previous research (including Self-Ask and IR-CoT) addresses this problem by using multiple retrievals and LLM generation steps iteratively to join the knowledge of different chunks.
However, these approaches are still not sufficient for tasks involving Path-finding multi-hop questions, where information is scattered across chunks without obvious direct connections.
(This is unlike conventional Path-following multi-hop question-answering tasks where information is present in sequential chunks.)
Let’s take an example.
We want to find a Stanford professor who does Alzheimer’s research from a pool of potentially thousands of Stanford professors and Alzheimer’s researchers.
We call him Professor Thomas.
