

A Practical Guide To Fast Fine-Tuning Your LLMs With Unsloth
Learn to Fine-tune Llama 3 in minutes for medical question-answering with Unsloth using QLoRA


LLMs come with limited internal knowledge.
When using them in production, you want them to be:
updated with and grounded in specific data
responding in a certain way
helpful while never being harmful
not hallucinating information
sticking to their task objective
This is where Fine-tuning comes in, which involves training the LLM further on specific datasets to internalise information about the domain, tone, or intended task objective.
Many would argue that RAG (Retrieval-Augmented Generation) could be an alternative to fine-tuning your models, but this is far from the truth.
Some reasons for this are:
RAG cannot always effectively ground a model in the context
RAG cannot change the specific style, tone, or output format that you intend from your LLM
RAG also comes with increased response latency due to its retrieval step
But How To Fine-Tune Efficiently?
Fine-tuning has always been computationally intensive and time-consuming because it conventionally involves updating all the model weights by retraining the model on specific datasets.
For large LLMs with billions of parameters, conventional fine-tuning involves using huge and expensive GPUs and hours to even days of training to achieve favourable results.
A 2021 research paper from Microsoft completely changed this notion by introducing a parameter-efficient way of fine-tuning LLMs.
Their method, LoRA (Low-Rank Adaptation), reduced the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times, compared with conventional fine-tuning a GPT-3 with 175B parameters!
It does so by freezing the pre-trained model weights and injecting trainable rank decomposition matrices into each layer of the Transformer architecture.
So, instead of updating billions of parameters, with LoRA, we would just adjust a few million parameters, achieving a near-similar accuracy to conventional fine-tuning.
Tell Me The Math
Mathematically, standard fine-tuning involves updating a larger weight matrix W , with dimensions d x k, where d is the input dimension and k is the output dimension of the model, as shown below:
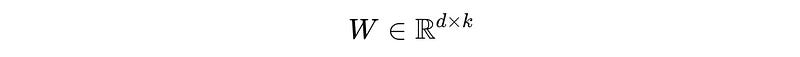
LoRA, on the other hand, decomposes a change to this matrix into the product of two much smaller matrices (lower rank) as follows:

These matrices A and B are known as the rank decomposition matrices and have the following dimensions, where r is the rank of the matrix:
