
Cache-Augmented Generation (CAG) Is Here To Replace RAG
A deep dive into how a novel technique called Cache-Augmented Generation (CAG) works and reduces/ eliminates the need for Retrieval-augmented generation (RAG).


LLMs respond to user queries based on their training data.
But this data could get outdated pretty soon.
To make sure that LLMs can answer a query using up-to-date information, the following techniques are popularly used:
Fine-tuning the entire model
Fine-tuning a model using Low-Rank Adaptation (LoRA)
In a recent ArXiv pre-print, researchers just introduced a new technique called Cache-Augmented Generation (CAG) that could reduce the need for RAG (and, therefore, all its drawbacks).
CAG works by pre-loading all relevant knowledge into the extended context of an LLM instead of retrieving it from a knowledge store and using this to answer queries at inference time.
Surprisingly, when used with long-context LLMs, the results show that this technique either outperforms or complements RAG across multiple benchmarks.
Here is a story in which we dive deep to understand how Cache-Augmented Generation (CAG) works and how it performs compared to RAG.
Let’s begin!
But First, What Is RAG?
Various techniques exist to ensure that LLMs can respond to user queries using up-to-date information.
This includes techniques like LLM fine-tuning and Low-Rank Adaptation (LoRA) that rely on embedding knowledge directly into model parameters.
Unfortunately, these are time-consuming and expensive to implement and must be performed frequently, making these techniques not preferable.
RAG, or Retrieval-Augmented Generation, was developed to solve this issue.
It is a knowledge integration and information retrieval technique that allows an LLM to produce more accurate and up-to-date responses using private datasets specific to the use case.
The terms in RAG mean the following:
Retrieval: the process of retrieving relevant information/ documents from a knowledge base/ specific private datasets.
Augmentation: the process where the retrieved information is added to the input context.
Generation: the process of the LLM generating a response based on the original query and the augmented context.
A typical RAG pipeline looks like the following.
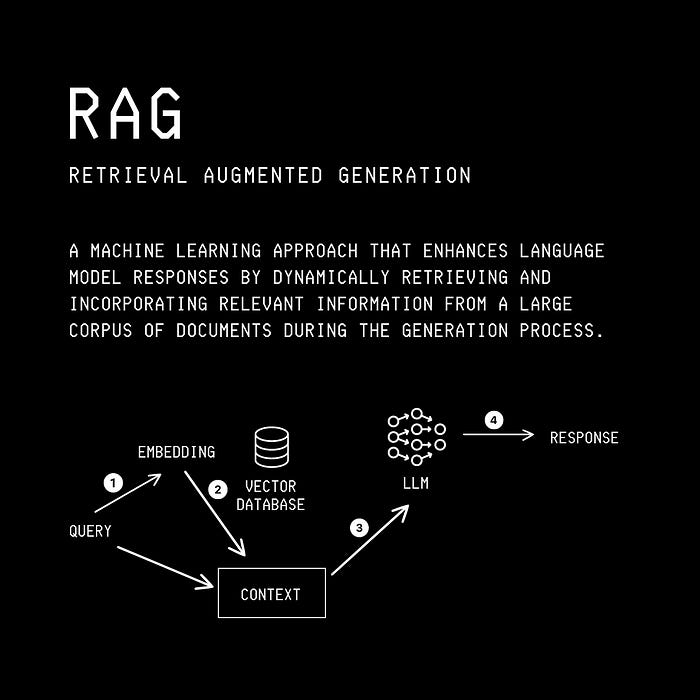
But RAG is not a perfect technique.
Here are some of its drawbacks.
Retrieval latency: Fetching information from an external knowledge base during inference takes time.
Retrieval Errors: Inaccurate or irrelevant responses can occur due to irrelevant and incomplete documents being picked during retrieval.
Knowledge Fragmentation: Improper chunking and incorrect ranking can cause the retrieved documents to be disjointed and lack coherence.
Increased Complexity: Building an RAG pipeline requires additional complex infrastructure and involves a lot of maintenance and update overhead.
Here Comes Cache-Augmented Generation (CAG)
Modern-day LLMs have enormous context lengths, with some popular LLMs and their context length as follows:
GPT-3.5: 4k tokens
Mixtral and DBRX: 32k tokens
Llama 3.1: 128k tokens
GPT-4-turbo and GPT-4o: 128k token
Claude 2: 200k tokens
Gemini 1.5 pro: 2 million tokens
Researchers leverage this capability of these LLMs to ensure retrieval-free knowledge integration.
Their technique, called CAG or Cache-Augmented Generation, works in a three-step process as follows:
Preloading External Knowledge
All of the required relevant documents are first preprocessed and transformed into a precomputed key-value (KV) cache.
This KV cache is stored on the disk or in memory for future use.
This saves on computational costs as the processing of documents occurs just once, regardless of the number of user queries.
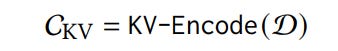
This also allows the LLM to have a more holistic and coherent understanding of the documents, which results in improved response quality.
2. Inference
During inference, the precomputed KV cache is loaded next to the user’s query, and the LLM uses this to generate responses.
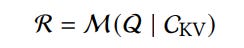
This step eliminates retrieval latency and reduces retrieval errors, as the LLM understands the preloaded knowledge and query within its context.
3. Cache Reset
The KV cache grows sequentially during inference, with the new tokens appended to the previous ones.
To maintain system performance during extended or repeated inference sessions, it is easy to reset the system by simply truncating these new tokens.
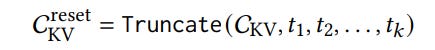
This enables fast reinitialization since the complete cache doesn't need to be reloaded from disk.
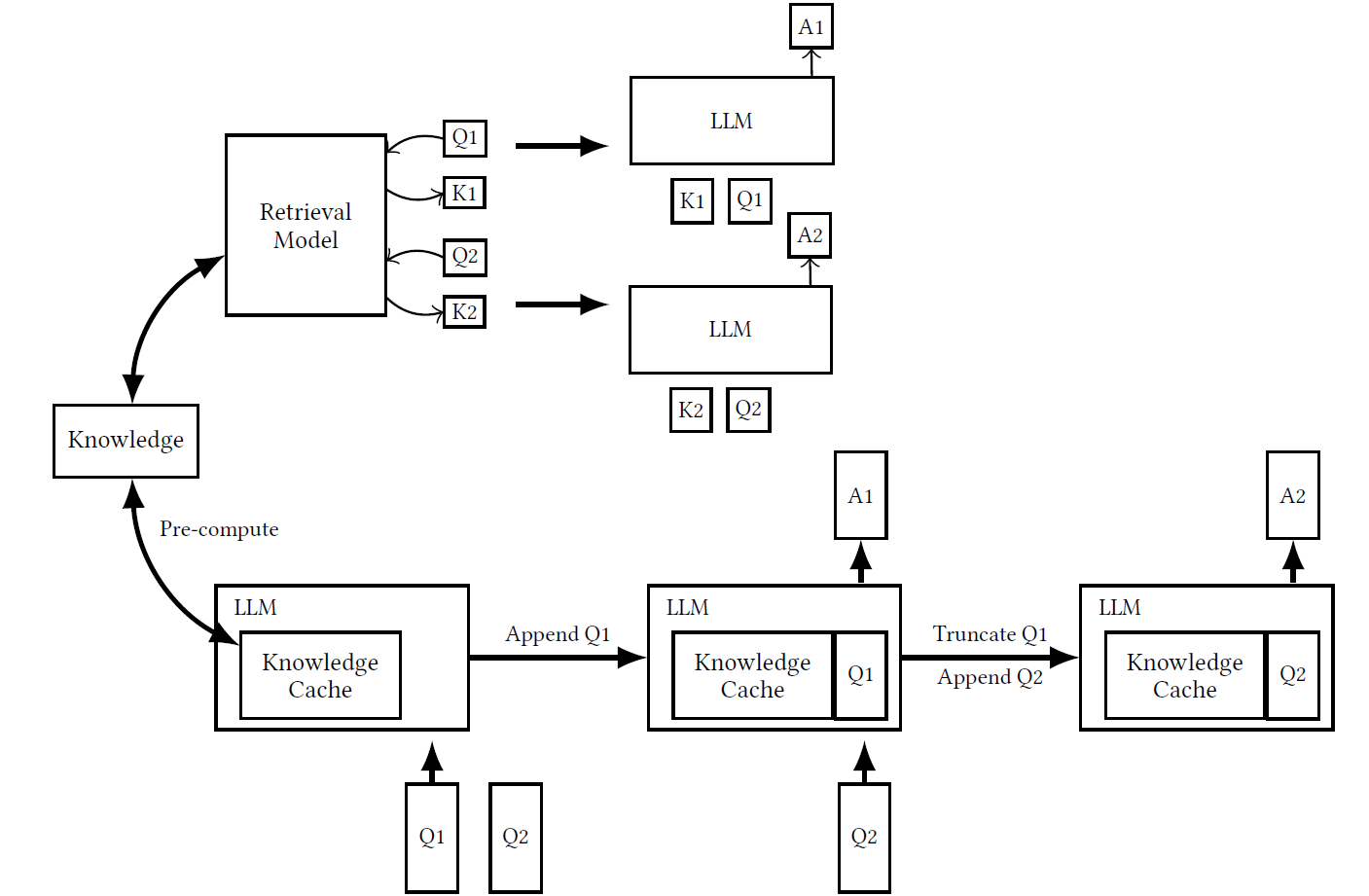
The following diagram shows the differences between the workflows of RAG (top) and CAG (bottom).
In RAG, the knowledge (K1, K2) is retrieved dynamically for each query (Q1, Q2) from a knowledge base.
It is then combined with the query and used by the LLM to generate answers (A1, A2).
In CAG (bottom), all relevant knowledge is preloaded into a Knowledge Cache.
Queries (Q1, Q2) are appended to, and responses (A1, A2) are generated based on this cache.
But How Good Is CAG?
Two question-answering benchmarks are considered for evaluating the performance of CAG.
These are:
Stanford Question Answering Dataset (SQuAD) 1.0:
Consists of 100,000+ questions posed by crowdworkers on a set of Wikipedia articles. The answer to each question is a text segment from the corresponding reading passage.HotPotQA: Consists of 113,000 Wikipedia-based question-answer pairs that require multi-hop reasoning across multiple documents.
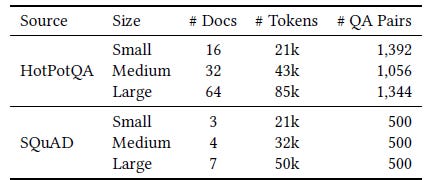
Three test sets are created from each dataset with different sizes of reference text, as increasing the length of the reference text makes retrieval more challenging.
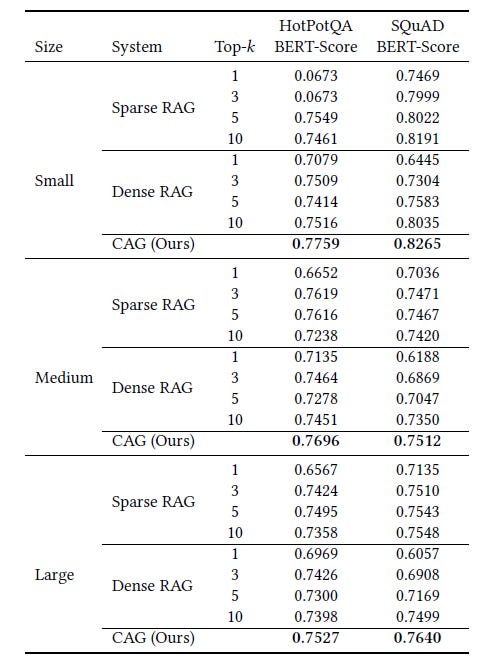
Reserachers use the Llama 3.1 8-B Instruction model (with a context length of 128k tokens) to test RAG and CAG.
The goal for each method is to generate accurate and contextually relevant answers for these benchmark questions.
BERT-Score is used to evaluate the performance of these methods based on how similar they are to the ground-truth answers.
RAG is implemented with LlamaIndex using two retrieval strategies.
Given a query, these retrieve the top-k passages from the document collection and pass them to the LLM to generate answers.
Sparse Retrieval with BM25
BM25 is a sparse retrieval method that ranks and returns documents based on a combination of Term frequency-inverse document frequency (TF-IDF) and document length normalization.
Dense Retrieval with OpenAI Indexes
Dense Embeddings are created using OpenAI’s models, which represent the query and documents in a shared semantic space and return the most semantically aligned passages with the query.
Coming back to our question: Is CAG really good enough?
Surprisingly, the results show that CAG outperforms both sparse (BM25) and dense (OpenAI Indexes) RAG systems, getting the highest BERT-Score in most evaluations.
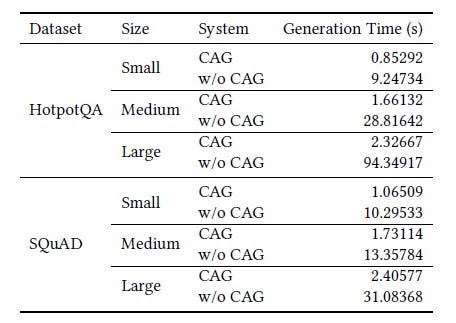
Moreover, CAG dramatically reduces generation time, particularly as the reference text length increases.
For the largest HotpotQA test dataset, CAG is about 40.5 times faster than RAG. This is such a big boost!
CAG sounds like a very promising approach for ensuring up-to-date retrieval from LLMs (on its own or when complemented with RAG) as their context lengths increase further in the future.
Would you plan on replacing your RAG pipelines with it? Let me know in the comments below.
Further Reading

but using CAG also means hosting LLM locally, correct?🤔