
Chain-of-Draft (CoD) Is The New King Of Prompting Techniques
A deep dive into the novel Chain-of-Draft (CoD) Prompting that outperforms Chain-of-Thought (CoT) Prompting while reducing LLM inference cost and latency like never before.


Reasoning LLMs are a hot topic in AI research today.
We started all the way from GPT-1 to arrive at advanced reasoners like Grok-3.
This journey has been remarkable, with some really important reasoning approaches discovered along the way.
One of them has been Chain-of-Thought (CoT) Prompting (Few-shot and Zero-shot), leading to much of the LLM reasoning revolution that we see today.
Excitingly, there’s now an even better technique published by researchers from Zoom Communications.
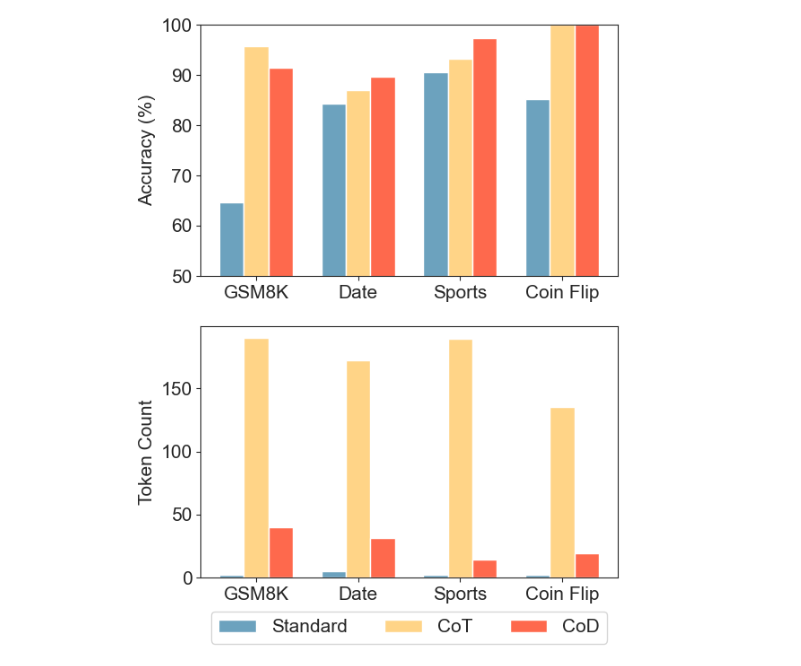
This technique, called Chain-of-Draft (CoD) Prompting, outperforms CoT Prompting in accuracy, using as little as 7.6% of all reasoning tokens when answering a query.
This is a big win for reasoning LLMs that are currently very verbose, require lots of computational time, and come with high latency, a bottleneck in many real-world time-critical applications.
Here is a story where we deep dive into how Chain-of-Draft (CoD) Prompting works and how you can use it to make your LLMs more accurate and token-efficient than ever.
But First, Let’s Talk Prompting
Researchers have constantly discovered new behaviours in LLMs.
Transformers led us to Generative Pre-trained Transformers or GPT, and we soon discovered that scaling it to GPT-2 (1.5 billion parameters) led it to act as an unsupervised multi-task learner (performing multiple tasks without supervised learning/ fine-tuning on task-specific datasets).
With further scaling to GPT-3 (175 billion parameters), it was found that the model could quickly adapt and perform well on new tasks with only a few examples provided in the input prompt (Few-shot Prompting).
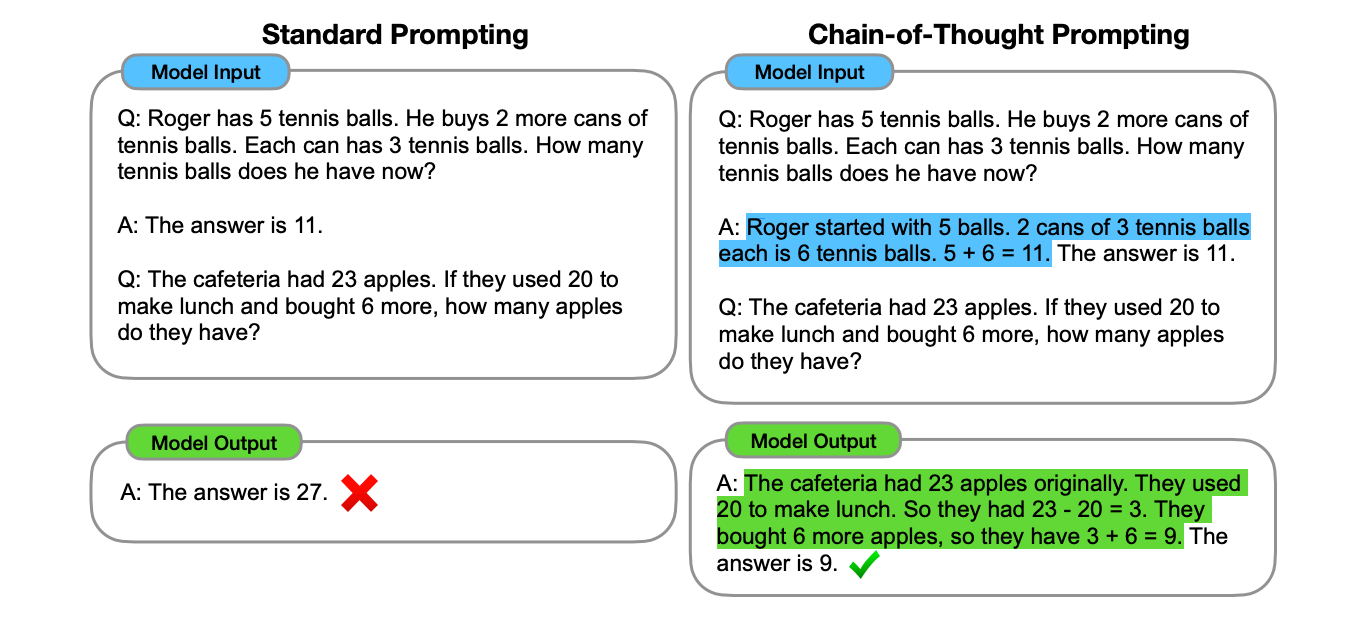
It was then discovered that breaking down problem-solving into intermediate reasoning steps and prompting a large language model (LLM) to generate these steps led to achieving state-of-the-art performance in arithmetic, commonsense, and symbolic reasoning tasks.
This approach is called Chain-of-Thought (CoT) Prompting.
Following CoT, it was soon found that LLMs were Zero-shot reasoners.
As in the original CoT prompting approach, they need not be prompted with few-shot reasoning examples for better performance.
Simply adding the phrase “Let’s think step by step” to a prompt could make them reason step-by-step while solving a problem.
This approach is called Zero-shot Chain of Thought Prompting.

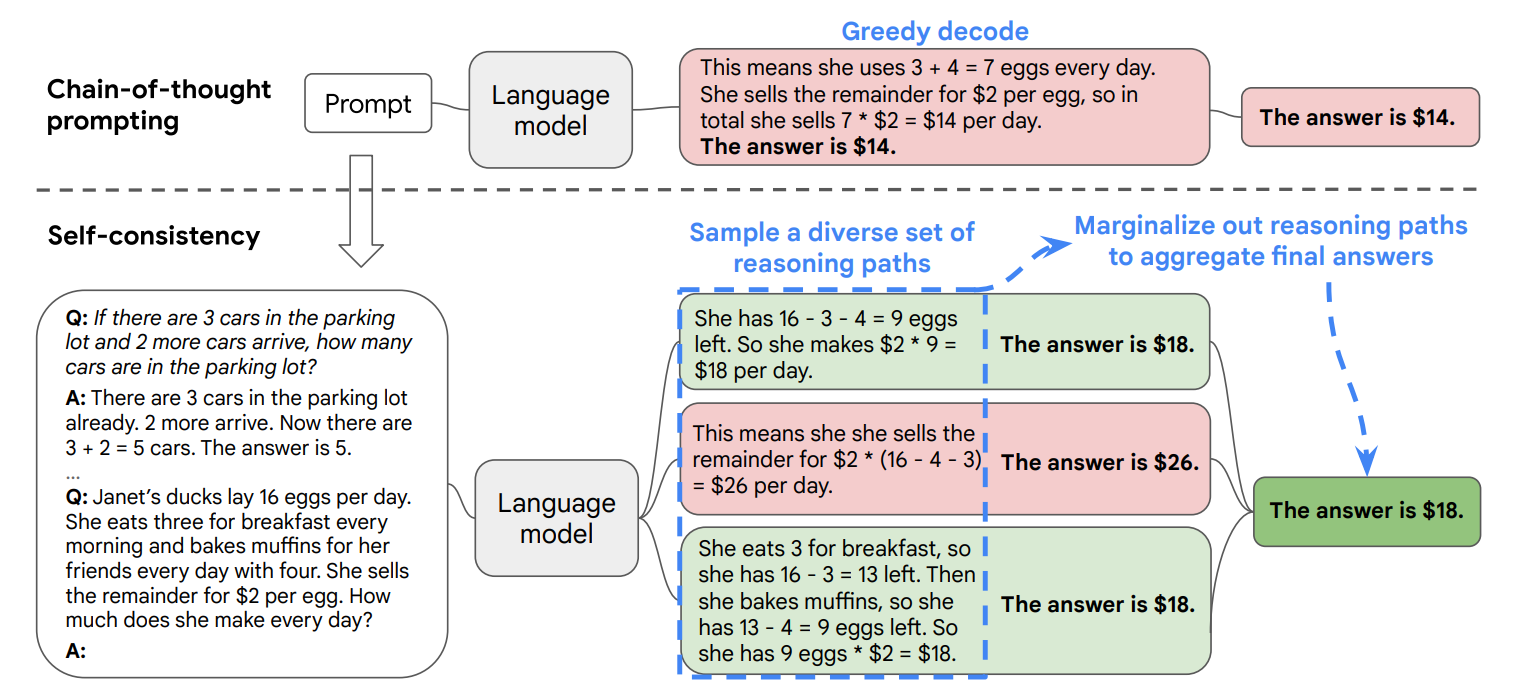
Researchers then realised that reasoning in a chain and greedy decoding towards the answer was not enough.
Complex reasoning tasks could have multiple reasoning paths that reach a correct answer, and if multiple paths lead to the same answer, we can be confident that the final answer is correct.
This led to a new decoding strategy called Self-Consistency, which samples the model to generate multiple reasoning paths and chooses the most consistent answer out of them.
Prompting Architectures Make Their Way
Following this approach of considering multiple reasoning paths in problem-solving, the Tree-of-Thoughts (ToT) framework was introduced, which explores the solution space using a tree-like thought process.
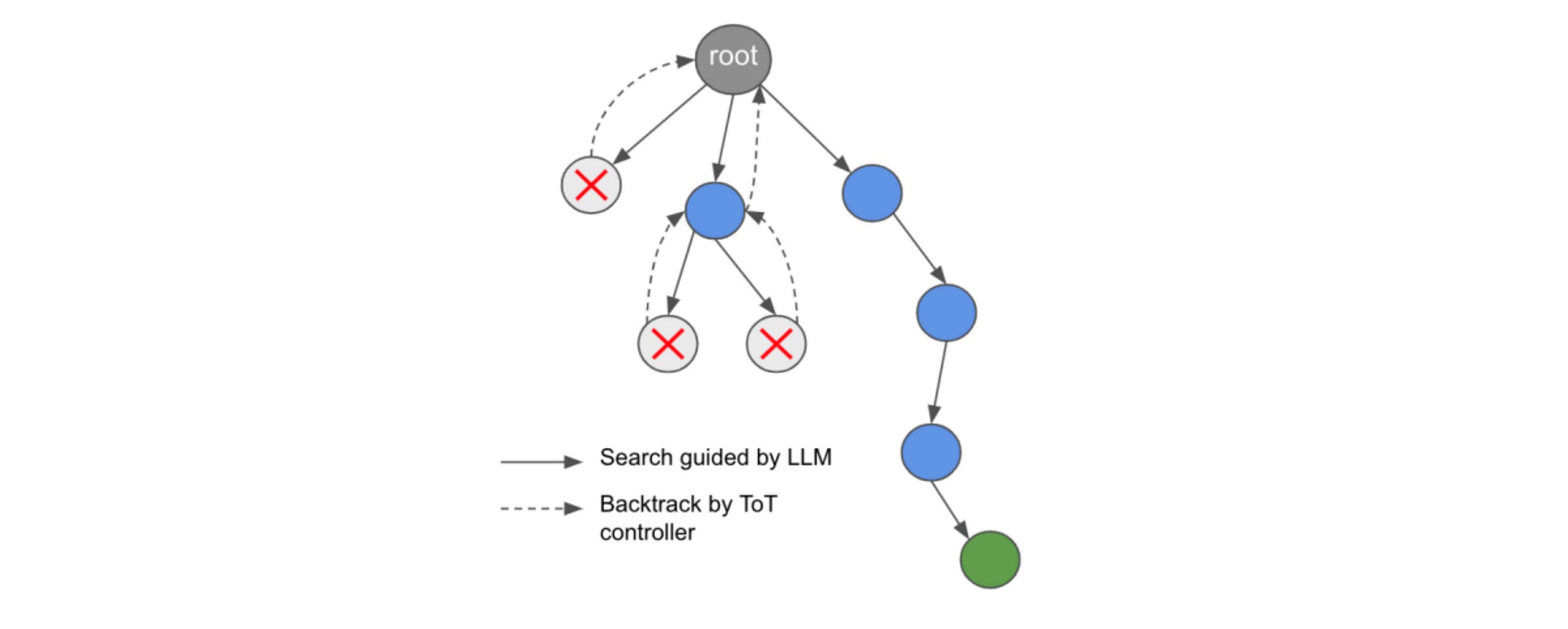
It uses language sequences called “Thoughts” as intermediate steps when solving a problem. These are evaluated and explored using search algorithms with lookahead and backtracking when needed.
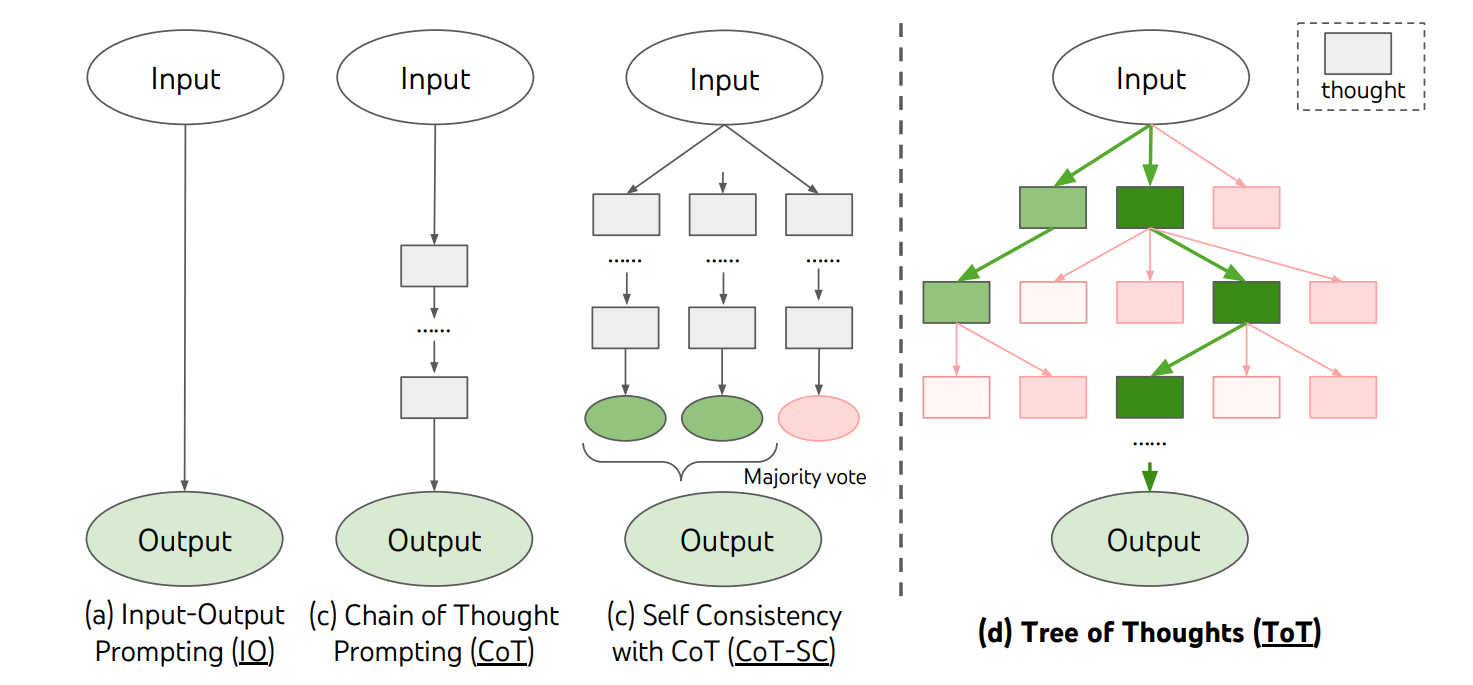
The Tree architecture was replaced by a Graph, leading to the Graph-of-Thoughts framework to better model the solution space.
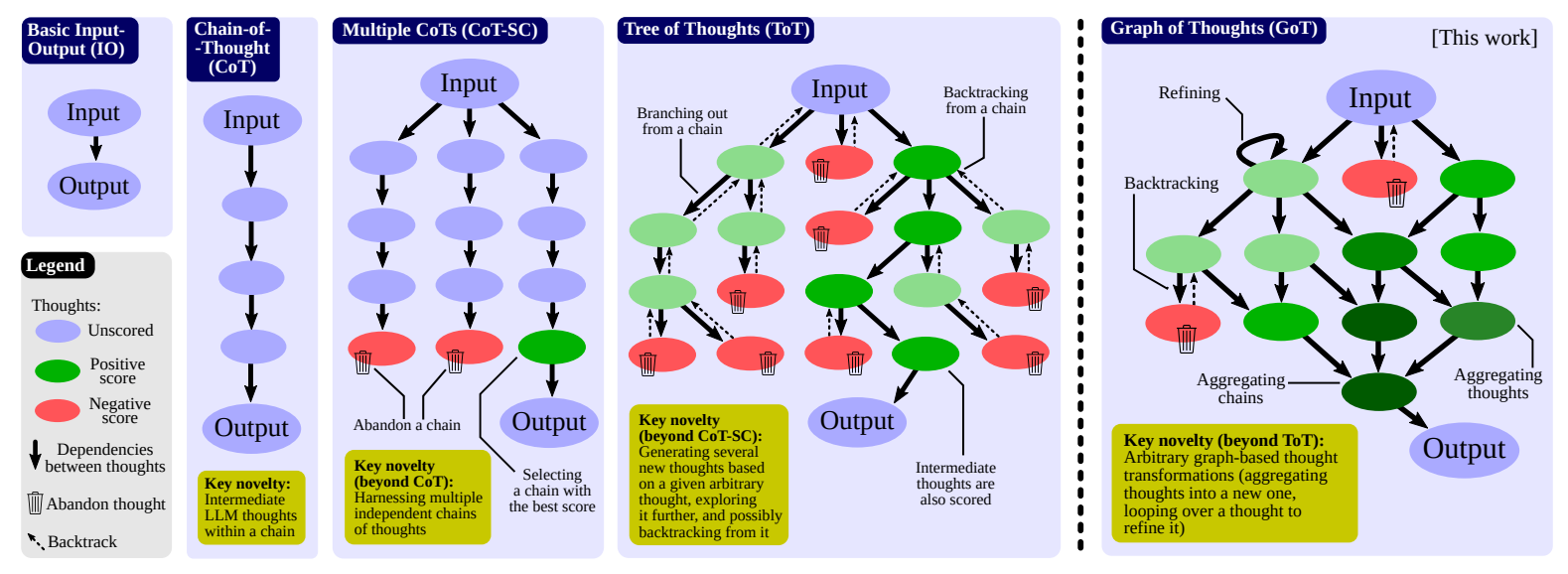
But this is not all!
Prompting is not the only way to help LLMs reason better, and there are so many other techniques, a brief overview of which can be found here.
But What About Latency?
Exploring the reasoning space is a computationally expensive task that increases response latency.
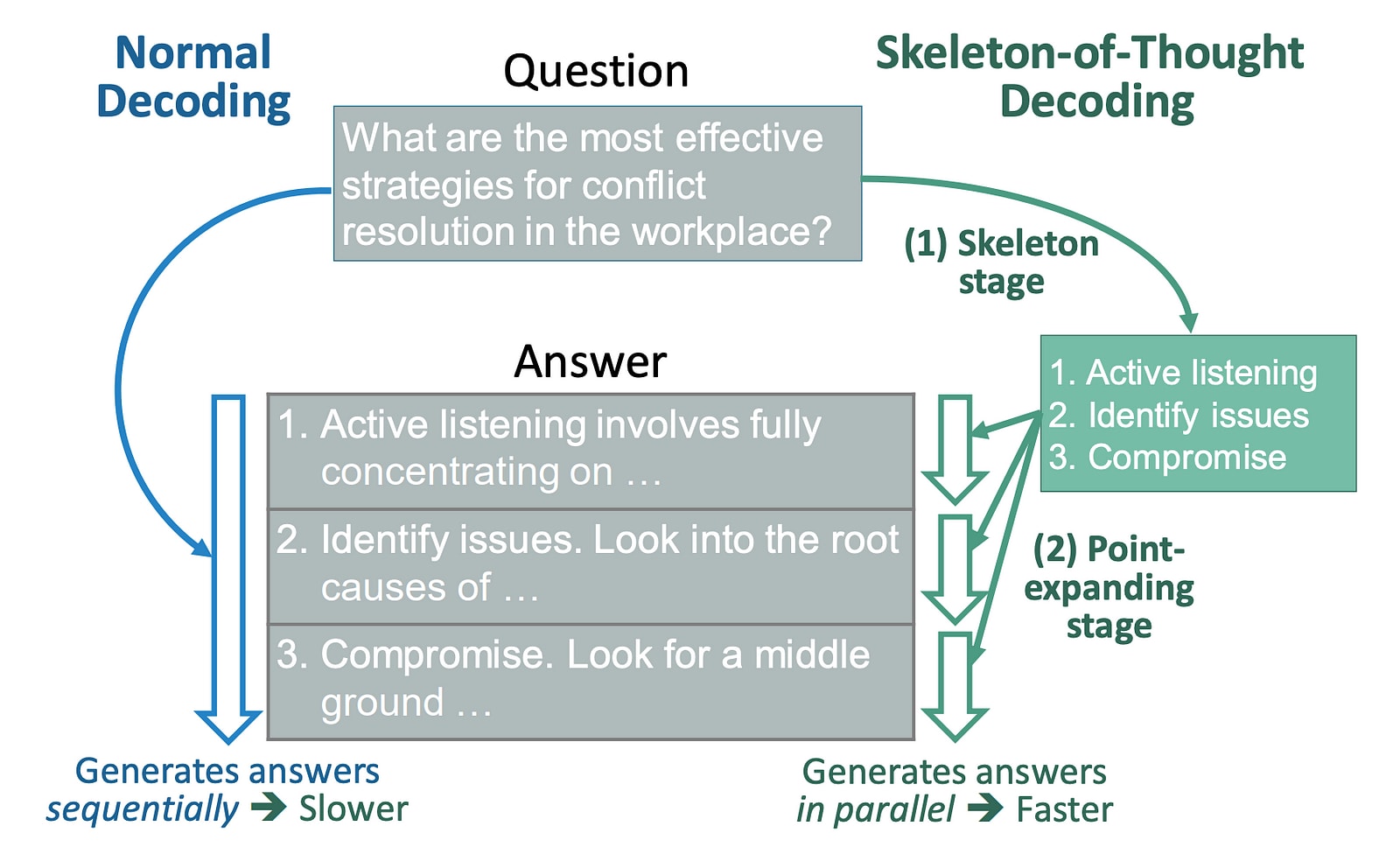
A workaround to reduce latency called Skeleton-of-Thought (SoT) was introduced, which first guides LLMs to generate the skeleton/ outline of the answer.
It then conducts parallel API calls/ batched decoding to complete the contents of each skeleton point in parallel.
Reasoning models can also overthink simple problems, generating unnecessary reasoning tokens, leading to high query-to-response time.
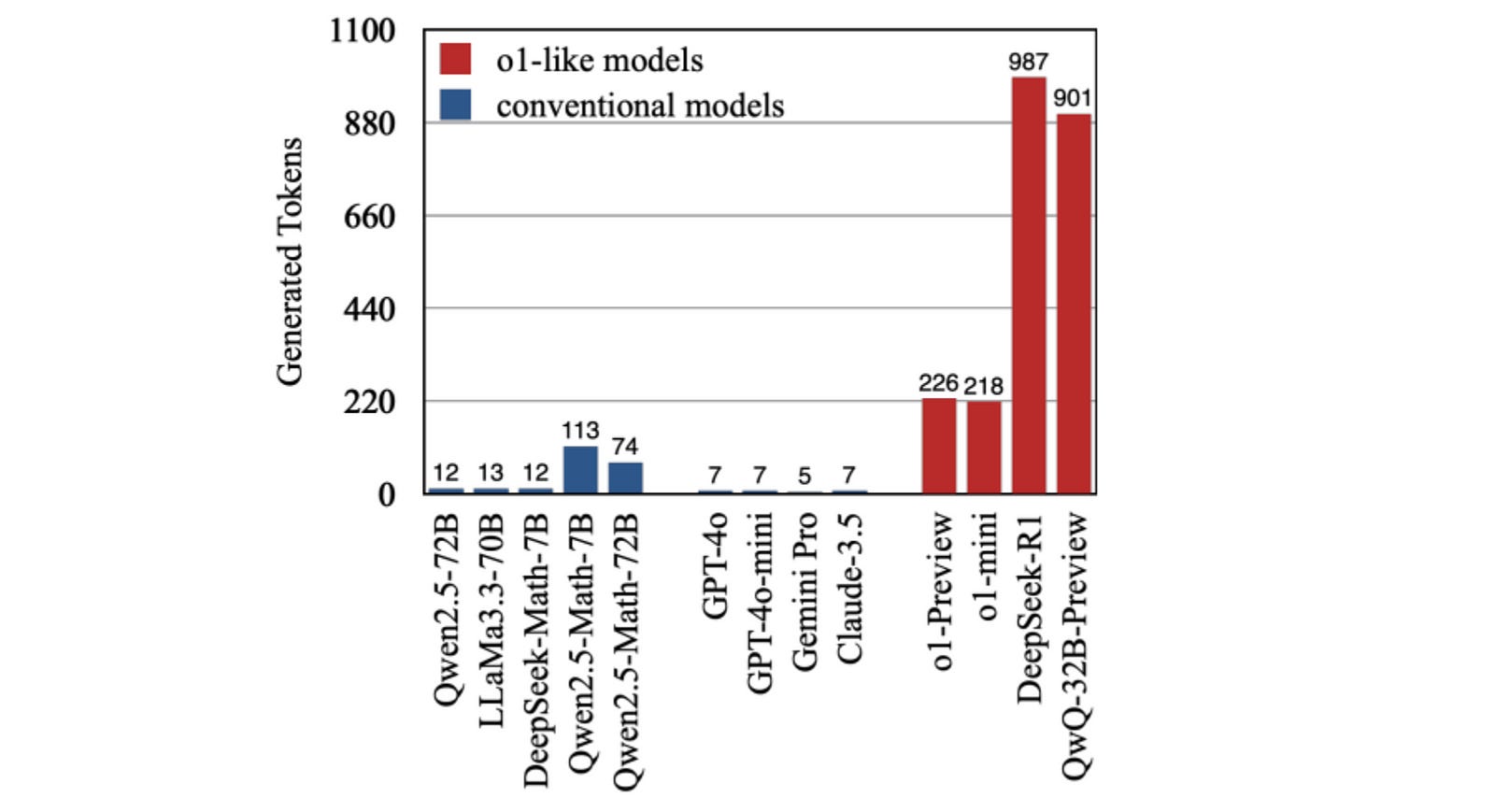
Isn’t it crazy how the QwQ-32-B-Preview model reasons to solve this simple problem of adding 2 and 3?

Reserachers have tried to address this issue by limiting the reasoning token budget, but often, LLMs fail to adhere to this.
An additional LLM has also been used to dynamically estimate the token budget for different problems based on their complexity before answering them, but this further increases response latency.
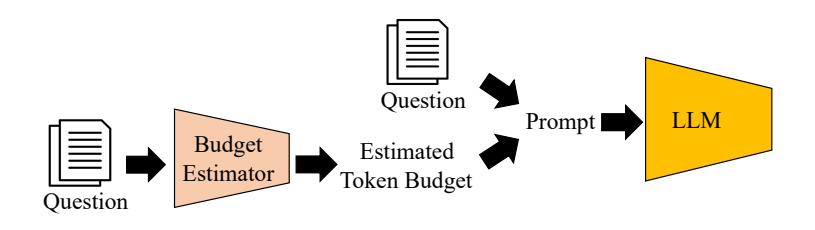
Could we combine all of these insights and somehow simplify them to reach a single approach?
Here Comes “Chain-of-Draft” Prompting
Going back to the basics, Chain-of-Thought (CoT) is a really amazing prompting approach for better LLM reasoning.
However, it is verbose, with an LLM producing thousands of reasoning tokens before reaching an answer.
This is very different from how humans think and reason.
Instead of reasoning in extensively verbose language, we usually jot down the most essential intermediate points (drafts) when thinking.
This is what Chain-of-Draft (CoD) Prompting is inspired by.
It simply asks the model to think step-by-step and to limit each reasoning step to five words at most.
To ensure the model understands this, Few-shot examples of such Chain-of-Drafts are written manually by the researchers and given in the prompt.
It is surprising to know that such a limitation is not enforced in any way, and the model is just prompted by this as a general guideline.
This contrasts standard few-shot prompting, where query-response pairs are given in the prompt, and the model is asked to directly return the final answer without any reasoning or explanation.
This is also different from Chain-of-Thought prompting, where intermediate reasoning steps are given in the query-response pairs in the prompt, and the model is asked to answer the question.
The difference between these approaches is better appreciated in the images below, where an LLM is asked to solve a simple arithmetic problem.



How Well Does CoD Prompting Perform?
To evaluate CoD prompting, GPT-4o and Claude 3.5 Sonnet are prompted using the above three approaches.
The system prompt given to these models for each prompting approach is shown in the image below.

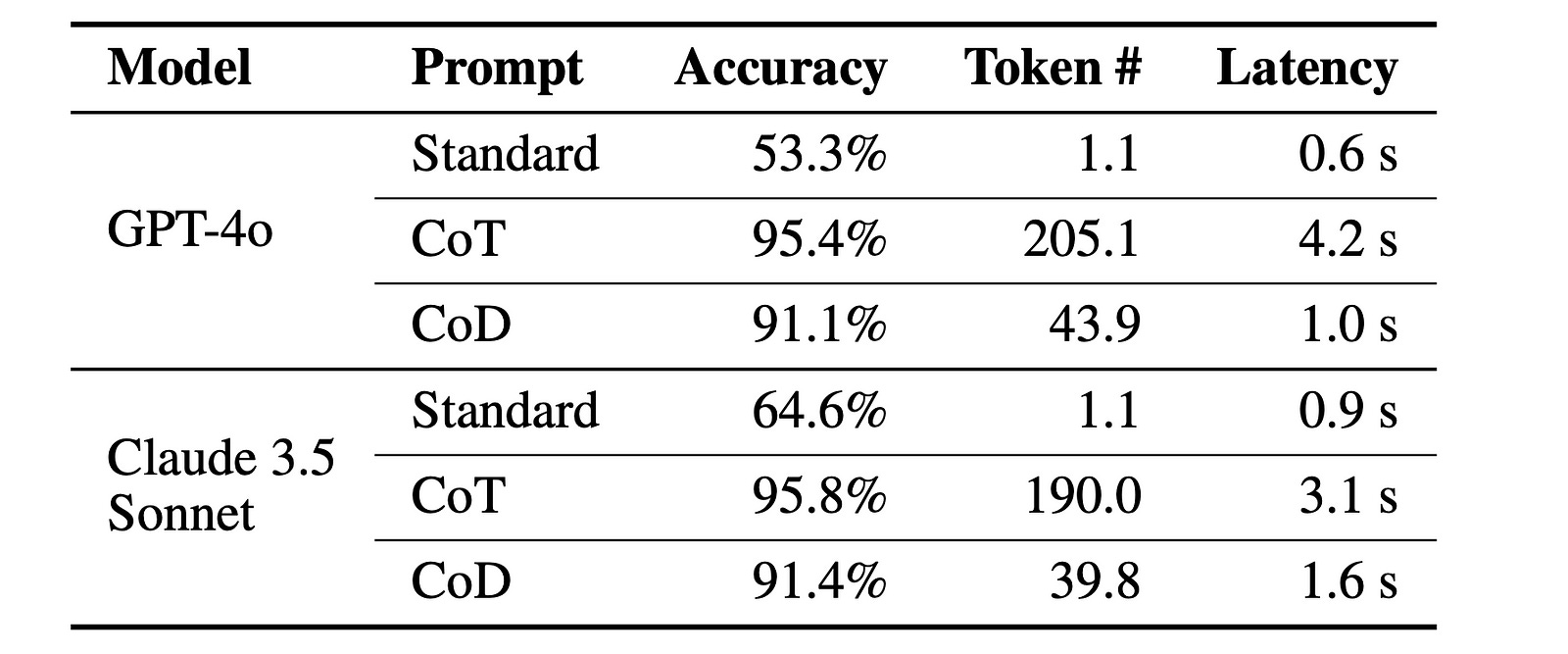
CoD achieves 91% accuracy on arithmetic reasoning GSM8K dataset while using 80% fewer tokens than CoT, reducing latency without any major accuracy loss (91.1% for CoD vs. 95.4% for CoT in the case of GPT-4o).
On Commonsense reasoning tested on BIG-bench tasks of Date & Sports Understanding, CoD significantly reduces latency and token usage while having the same/ improved accuracy over CoT.
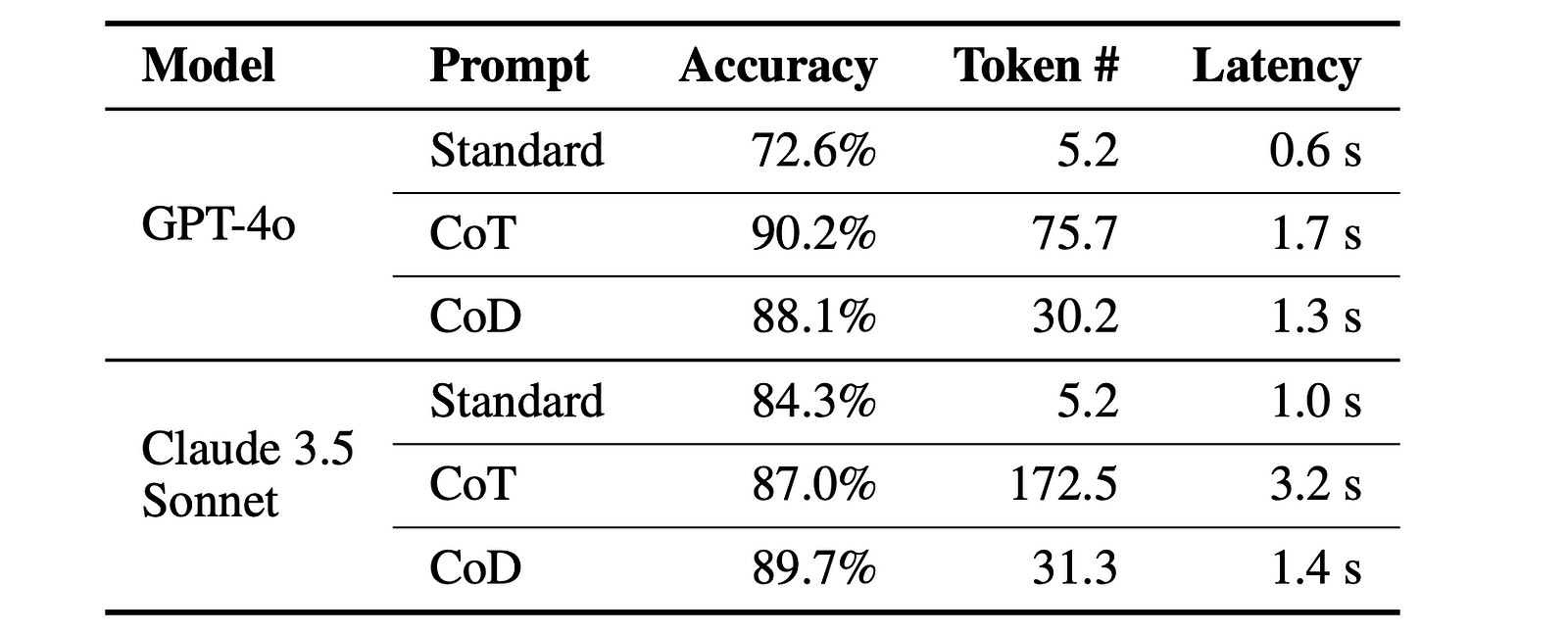
Note how CoD impressively reduces the average output tokens for CoT prompting from 189.4 to 14.3 (a 92.4% reduction) when used with Claude 3.5 Sonnet for the Sports Understanding task!
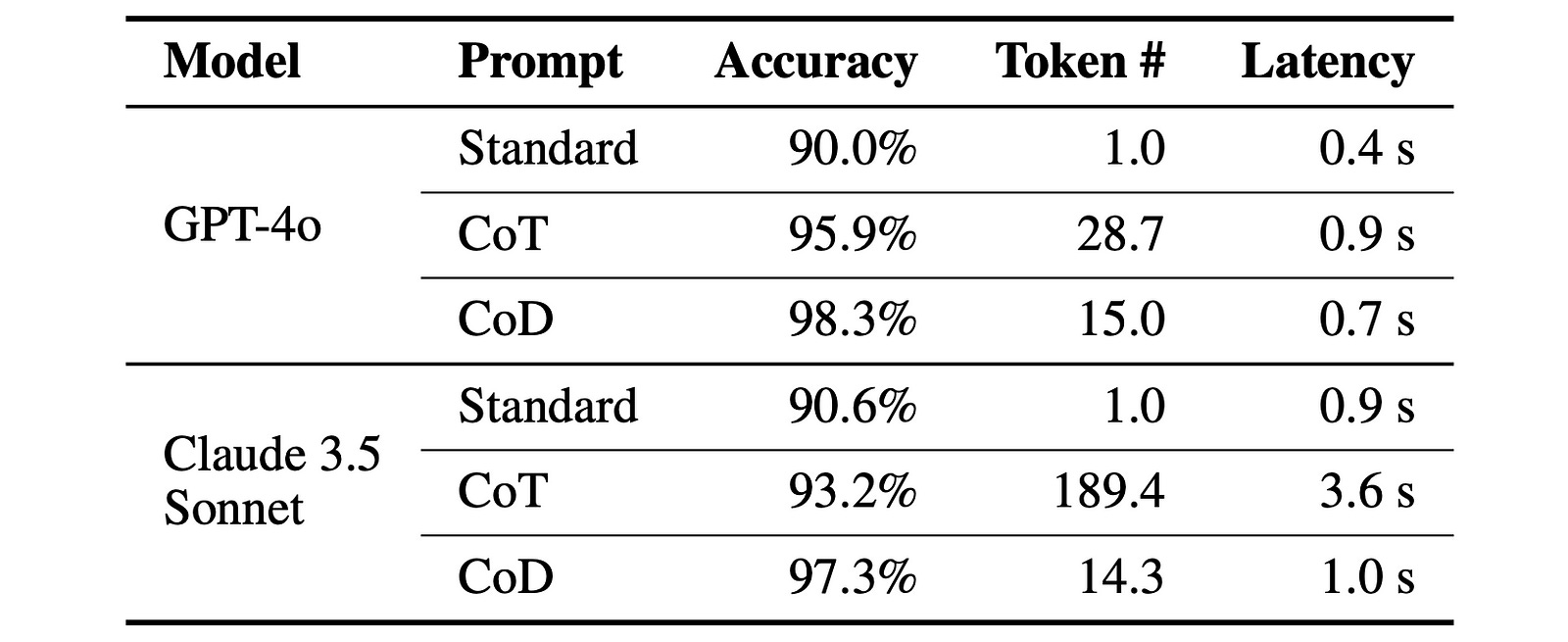
Finally, when evaluated on the Symbolic reasoning task of Coin-flipping (predicting the final coin state after a sequence of flips), CoD results in a 100% accuracy with significantly fewer tokens than the other approaches.

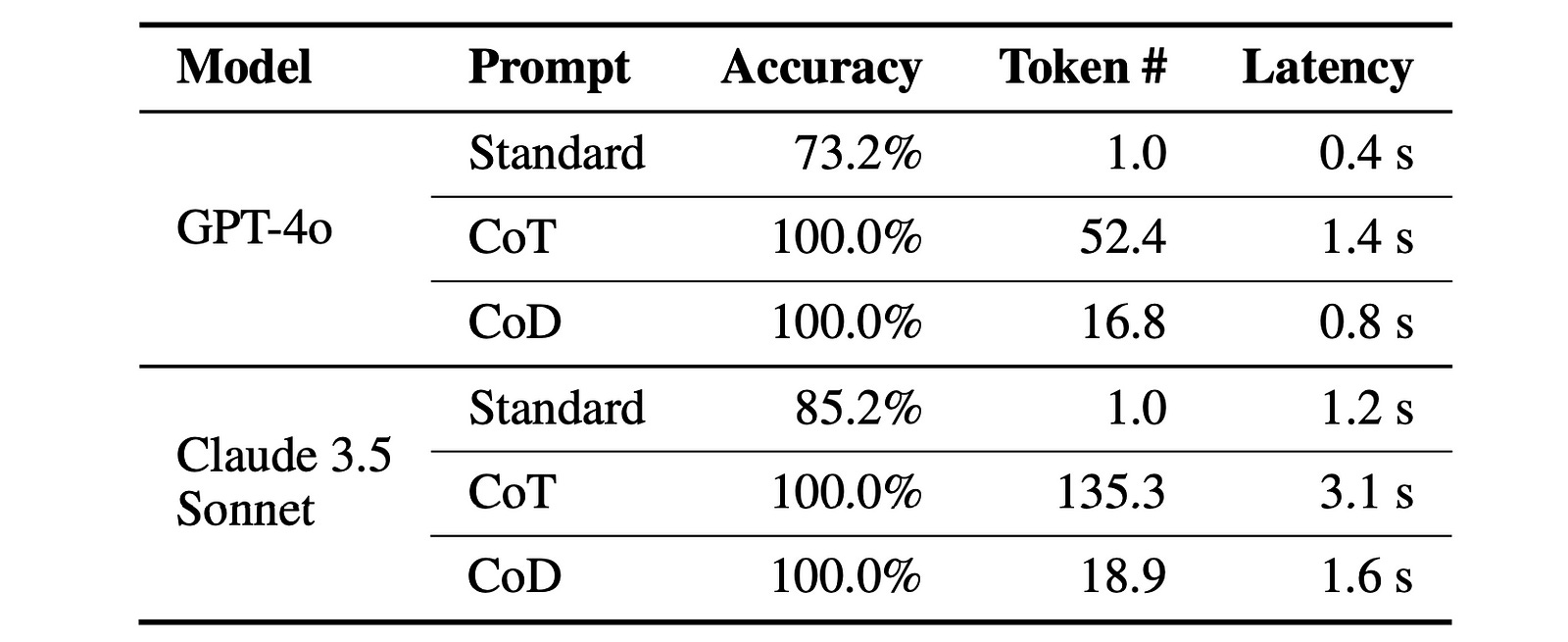
These results are absolutely phenomenal!
CoD prompting leads to amazingly high accuracy with minimal latency, reducing the response time and benefiting time/ compute-critical applications.
Such CoD data could also be used to train LLMs to reason better (based on the DeepSeek-R1 reinforcement learning training approach), making them faster, cheaper, more efficient, and more scalable.
I’m pretty excited about it all!
Have you used Chain of Draft prompting yet? Let me know in the comments below.
Further Reading
Source Of Images
All images are obtained from the original research paper unless stated otherwise.

Wow! That's amazing! 🤯