
Darwin-Gödel Machine: The First Self-Improving AI System Is Here
A deep dive into the novel architecture of the Darwin-Gödel Machine and what its impressive self-improvement capability means for the future of AI.


An AI system that can learn from its failures and improve itself is one that might lead us to AGI.
However, today’s AI systems are far away from this.
Yes, they can think step by step and reason to some extent, but their architectures and parameters are fixed, and they cannot continuously and autonomously improve themselves.
But what if I tell you that we are moving towards a future where this might be all possible?
Researchers at Sakana AI, a Tokyo-based AI research lab that previously released a fully automated AI Scientist, have just made this a reality.
They have proposed an architecture called the Darwin-Gödel Machine (DGM) that can iteratively modify its own codebase to improve itself while continuously checking its performance on different coding benchmarks.
This architecture is inspired by Darwinian evolutionary biology, in which multiple variants grow from a single starting point and the ones that perform the best “survive” most successfully.

When evaluated on SWE-bench (a benchmark for testing real-world software engineering issues from GitHub), DGM automatically improves its coding capabilities, producing a performance rise from 20.0% to 50.0%.
Similar results are seen on another software engineering benchmark called Polyglot, where it can autonomously increase its performance from 14.2% to 30.7%.
This is a story where we deep dive into Darwin-Gödel Machines and learn how they work to produce such impressive results, pushing state-of-the-art AI a step ahead.
Let’s begin!
Btw, my latest book called “LLMs In 100 Images” is now out. It is a collection of 100 visuals that describe the most important concepts you need to master LLMs today.
Grab your copy at a special early bird discount using this link.

But First, What Does ‘Darwin-Gödel Machine’ Really Mean?
A Gödel Machine is a system that can search for ways and implement them to improve itself.
Such a machine remains theoretical because, by definition, a Gödel Machine must provably improve itself.
Simply put, it must use formal proof to justify that a change will improve itself. Once a favourable proof for a given change is found, it can then be implemented.
This is a tough restriction for the real world, especially for an AI model, where formally justifying why it performed better on a task is almost impossible to pinpoint, let alone mathematically proving it.
A Darwin-Gödel Machine relaxes this criterion and improves based on empirical evidence from experiments rather than theoretical proofs.
And how about the ‘Darwin’ In ‘Darwin-Gödel Machine’?
Instead of first justifying a change and then moving towards it, DGM explores the space of all possible systems to create newer models (similar to Mutation in living beings).
Out of these models, the ones that can compile and retain the ability for further self-modification are kept in an archive (similar to a Population of generations), and all others are discarded (“Survival of the fittest” from Darwinian evolutionary theory).
These models are then evaluated in experiments on coding benchmarks.
Instead of building and improving with a single lineage from the best-performing model at each iteration, the other models kept in the archive are also used to build further models.
This is done to achieve open-ended exploration in model improvement, as many models that are not the best performers at the end of an iteration can still improve with time, leading to surprising breakthroughs in performance later on (similar to Darwinian evolution).

Now that we know why Darwin-Gödel Machines are called so, let’s move forward and learn how they work in detail.
Diving Deep Into The Architecture Of A Darwin-Gödel Machine
A Darwin-Gödel Machine is implemented as a coding agent powered by an LLM (with non-modifiable parameters) with access to its own code repository and two tools:
Bash tool: for executing Bash commands

2. Editing tool: To view and edit files and directories

A new coding agent is produced from a parent agent at each iteration.
A parent agent is chosen by a mechanism that balances the exploration and exploitation tradeoff.
The following are the details of it.
Given an archive of all agents at iteration t as follows:

The eligible set of parents (E(t)) to be sampled from consists of agents with an imperfect performance score (α(i) < 1):

For each agent a(i)(t) in this set, its performance score α(i) is:

And the number of functioning children that this agent has already produced (children that can still modify codebases) is:
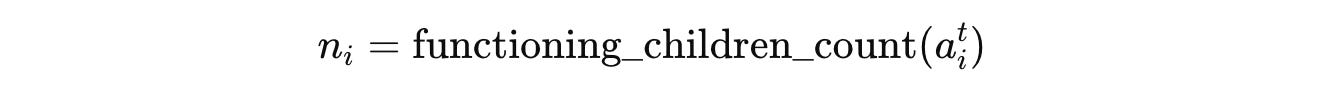
Each agent’s performance score is normalized using the Sigmoid function as follows:
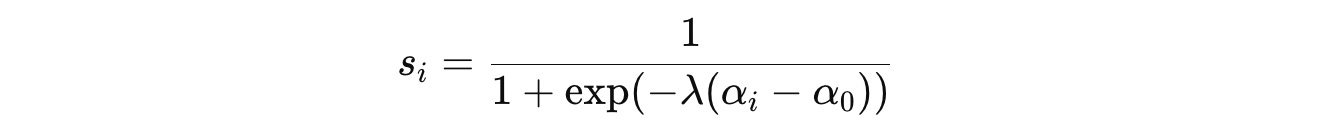
where λ controls the sharpness of the curve and α(0) is the midpoint of the curve.
Next, based on the number of functioning children n(i) that an agent has, a novelty bonus h(i) is calculated as follows, where a lower number n(i) results in a smaller bonus:

The novelty bonus h(i) is then combined with the sigmoid-normalized performance score s(i) into a weight w(i):
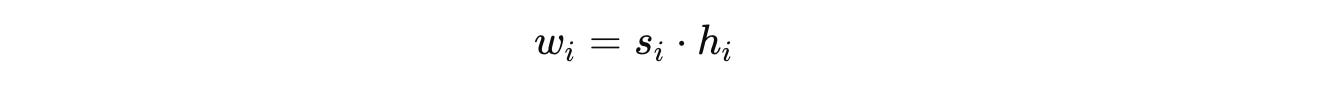
Finally, the probability of selecting a parent agent is calculated by normalizing its weight w(i) over all eligible agents as follows:

And k parent agents are sampled from the eligible set using these probabilities.
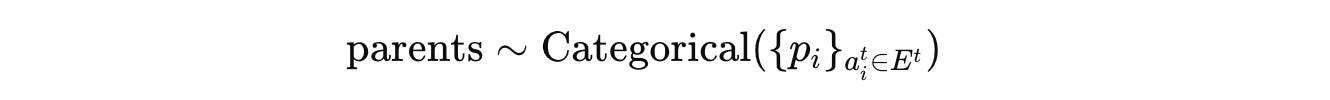
If these equations confused you, the takeaway is that this parent-selection mechanism favours high-performing agents (‘exploitation’) while still giving underexplored agents with fewer children a chance to build from (‘exploration’) by giving them a novelty bonus.
The mechanism ensures that all agents in the archive have a non-zero probability of being selected as parents.
In other words, it makes any path to improvement possible and not just the ones where agents have the highest performance score at a given iteration.
Once selected, the parent analyses its own benchmark evaluation logs and proposes a new feature that would improve its performance.
This feature is implemented in its own codebase, generating a new child agent.
Each child agent is then evaluated on a coding benchmark (SWE-bench or Polyglot).
Any child agent that compiles successfully and retains the ability to edit code is kept in an archive, while the others are discarded.
This cycle of parent selection, self-modification and evaluation goes on, increasing the number of agents in the DGM archive to build on.
The pseudocode of the complete algorithm is as follows:

But Can A DGM Really Self-Improve?
For experiments, a DGM (initialized as a coding agent backed by an LLM) is given a single input prompt as follows:

Its algorithm is then run for 80 iterations, producing one agent per iteration.
The DGM uses Claude 3.5 Sonnet on SWE-bench or OpenAI’s o3-mini on Polyglot for evaluation.
OpenAI’s o1 is used to study benchmark logs and propose changes for self-improvement, and Claude 3.5 Sonnet is again used to implement these self-modifications.
For those new to these benchmarks, SWE-bench is a benchmark based on software bugs in popular open-source Python repositories on GitHub.
The above experiments use the ‘Verified’ subset released by OpenAI that filters out the unsolvable problems from the original SWE-bench benchmark.
The Polyglot benchmark, on the other hand, contains tasks in multiple programming languages, including C++, Rust, Python, and more.
This benchmark is more niche and less likely to be found in the pre-training dataset of most LLMs compared to SWE-bench.
To test out the importance of each part of the DGM, researchers create two versions of it and compare them to the complete DGM model:
DGM without Self-Improvement (that uses the initial agent to generate child agents in all further steps)
DGM without Open-ended exploration (that keeps and builds on the latest working agent, discarding the archive of all past agents)
Here is what the results tell.
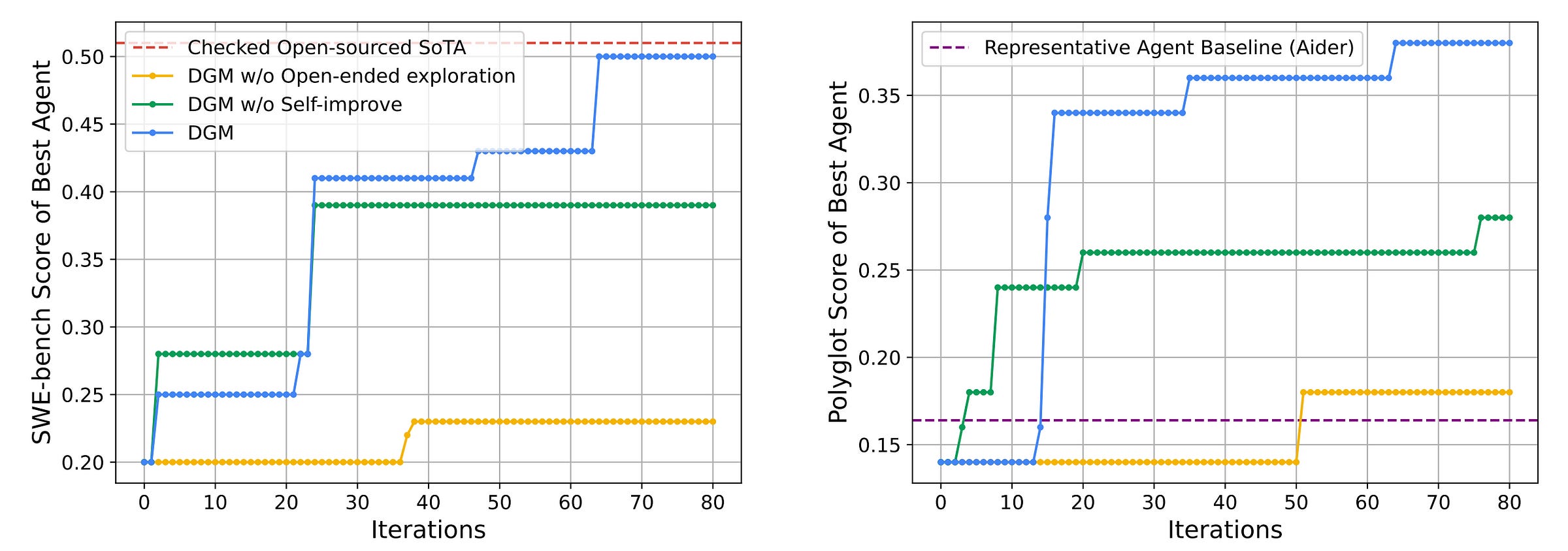
After 80 iterations, the performance of the coding agents increases from 20% to 50% on SWE-bench, and from 14.2% to 30.7% on Polyglot.
This tells us that DGM can automatically create a better version of itself by learning to use its tools better, improving its prompting, and improving how different LLMs are integrated into its workflow, as the algorithm progresses.
The improvements are so impressive that the best DGM-discovered agent is comparable to the best open-source human-made agent on the SWE-bench.
For Polyglot, it surpasses the performance of Aider, the coding agent built by the team that created the benchmark itself.
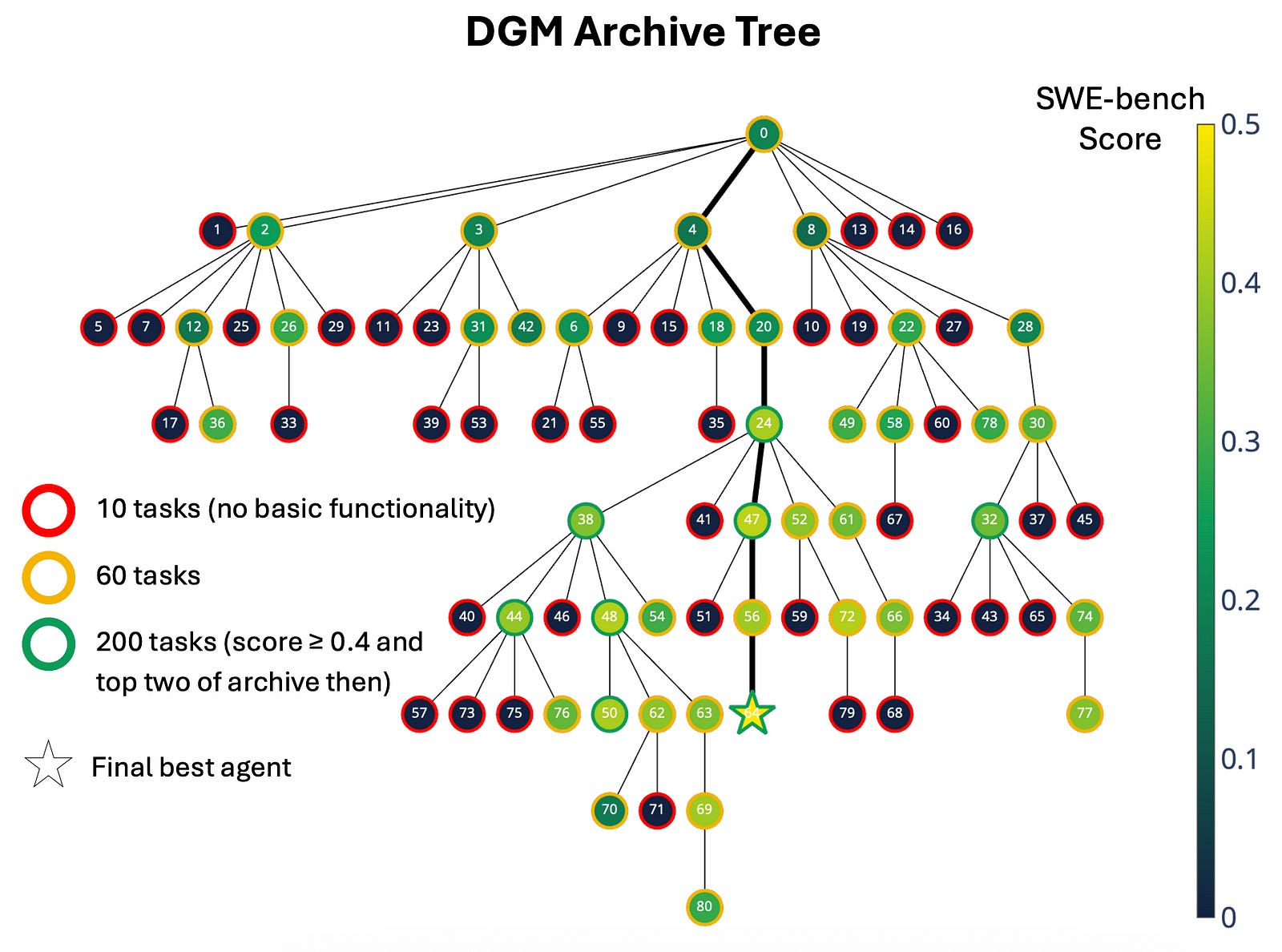
Thanks to open-ended exploration, many agents that perform sub-optimally during evaluation lead to paths creating a child that outperforms all other agents later on.
This can be seen in the DGM archive tree, where the performance falls at iteration 4 (darker colour means lower SWE-bench score) but then improves towards iteration 56, creating the final best agent.
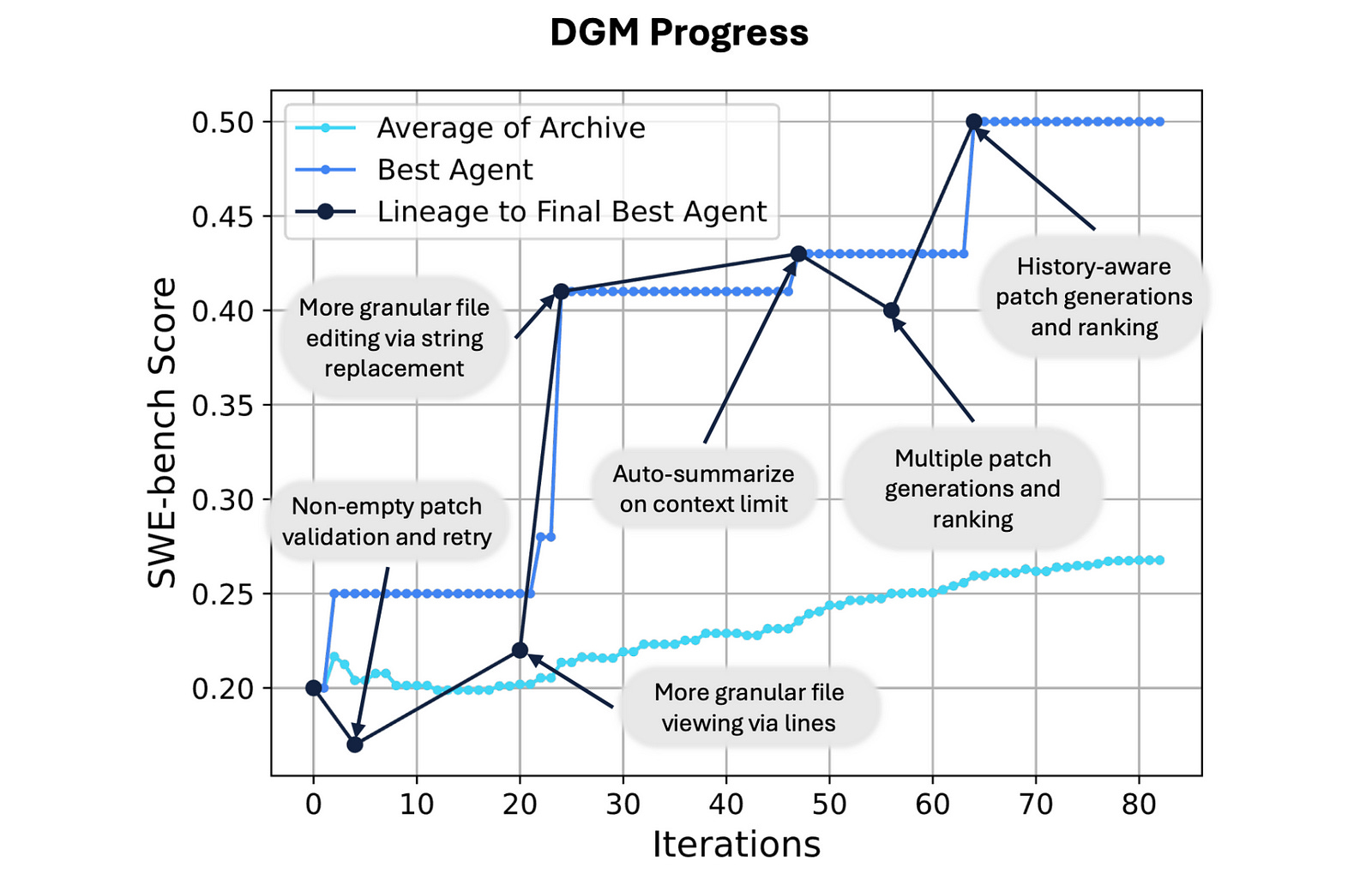
The following image shows the different methods discovered by the agents to improve themselves.
As shown with the dark line, even when the agents experience two dips in performance, open-ended search and not just sticking with the immediate best agent, helps reach the final best agent.
It is seen that DGM without self-improvement improves at first but stagnates later on.
A similar performance drop is seen with DGM without open-ended exploration, which struggles to improve over time because it discards older agents, which means that a bad update can block all progress.
Thankfully, these improvements are not because of some model-specific tricks.
Even when the base LLM used for running or evaluating an agent is swapped with another, the DGM-discovered best agent still performs better than its initial one.

The performance of the DGM-discovered agent is also transferable to other programming languages.
Even when trained only on Python tasks, the agent performs almost as well on other programming languages as the one trained on tasks in all programming languages, and it still beats the initial agent and Aider.

Are DGMs All That We Need To Reach AGI?
DGMs currently do not rewrite the code of or retrain the LLMs powering them, and they do not work with tasks other than coding.
Running a DGM is also very expensive and time-consuming, given that the estimated cost of completing a single run on SWE-bench is around $22,000 and takes about 2 weeks.

Also, while a DGM-discovered best agent beats the open-source state-of-the-art agents on the coding benchmarks, it cannot do the same with the closed-source baselines.
This could be because these baselines use specialised techniques (such as reasoning) or because of the limited computational resources available to the researchers when training a DGM.
Despite these limitations, DGM is the first self-improving system to explore the ‘betterment’ search space in an open-ended manner and impressively increase its performance on real-world tasks.
However, we are still far away from a system that appears close to AGI.
Further Reading
Code associated with the original research paper on Darwin Gödel Machines, open-sourced on GitHub
Research paper titled ‘A Self-Improving Coding Agent’ published in ArXiv
Source Of Images
All images used in the article are created by the author or obtained from the original research paper unless stated otherwise.

This is quietly a philosophical shift.
I am calling AI “depth machine” not a speed one, and this feels like a new embodiment of that idea. A system that doesn’t just output, but asks better questions of itself over time.
Feels like a mirror: this is the work of any evolving human system, too.
Not optimization. Not perfection. But recursive pattern-breaking, with memory.
Curious to watch how this line of thinking shapes not just future agents, but how we define growth itself.
This is best