
Here Is Google DeepMind’s New Research To Build Massive LLMs With A Mixture Of Million Experts
A deep dive into the development of the Mixture-of-a-Million-Experts (MoME) architecture, which outperforms traditional LLMs in performance and computational efficiency like never before


There is an LLM war happening around us.
It might not be immediately obvious, but all big tech companies are in a rush to develop better LLMs that outperform existing ones.
Increase the model size, the dataset size, and the amount of compute, and voila, you have a better model than before.
Given this Scaling law, researchers at Google DeepMind found that tweaking the model architecture a certain way also significantly improves its performance and training efficiency.
Their insight arose from the fact that the Transformers architecture, at the core of an LLM, stores most of its factual knowledge in the dense Feed Forward (FFW) layers.
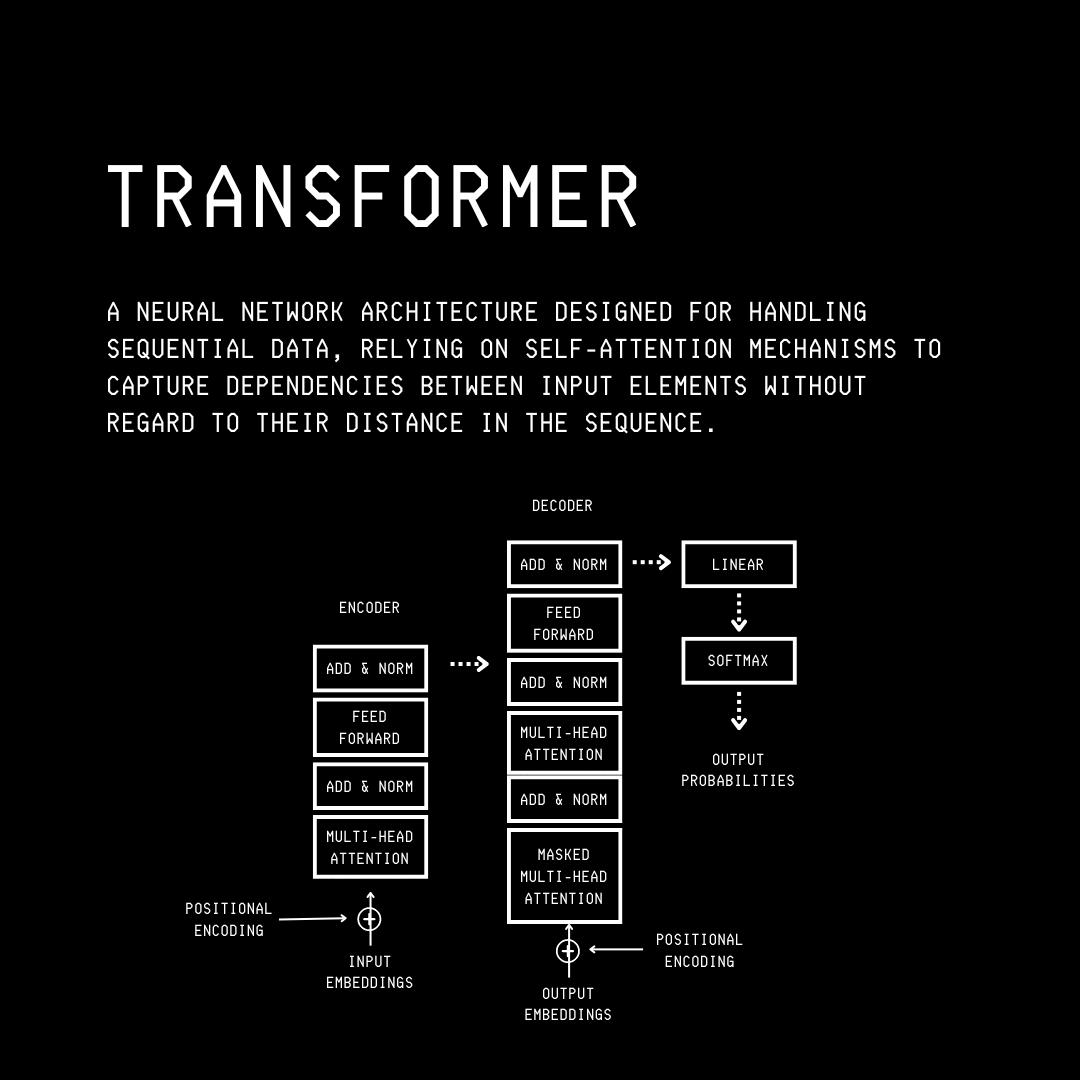
These layers account for 2/3rd of all parameters in a Transformer.
And that’s a problem.
It increases the conventional transformer's computational footprint by a huge amount, as it is linearly proportional to the number of parameters it contains.
Working to solve this and taking inspiration from the Mixture-of-Experts architecture (MoE), the researchers developed PEER (Parameter Efficient Expert Retrieval), a novel layer that can fit into the existing Transformer architecture and improve it like never before.
This layer can then be used with a Mixture-of-Experts LLM consisting of over a million tiny Experts!
Their publication in ArXiv demonstrated how this Mixture-of-a-Million Experts (MoME) architecture outperforms the traditional LLMs and the previous MoE models (with fewer but larger Experts) while being computationally efficient at the same time!
Here’s a story that deep-dives into how this novel architecture works, how it was developed, and how it performs compared to the previous LLM architectures.
Let’s Begin With The Mixture-of-Experts Model
The quest to decouple computational cost from the number of model parameters is not new.
It was in 2017 when the Mixture-of-Experts (MoE) model was introduced and popularised.
This model combined multiple neural networks called Experts that specialised in different skill sets.
A Gating network was responsible for selectively activating these Experts according to the given query and combining their weighted outputs to produce the result.
Thanks to this research, it was found that using sparsely activated Expert modules instead of dense feed-forward networks (FFWs) is more efficient.
Then, earlier in 2024, the Scaling laws for these MoE models were introduced.
They are mathematically described as follows —
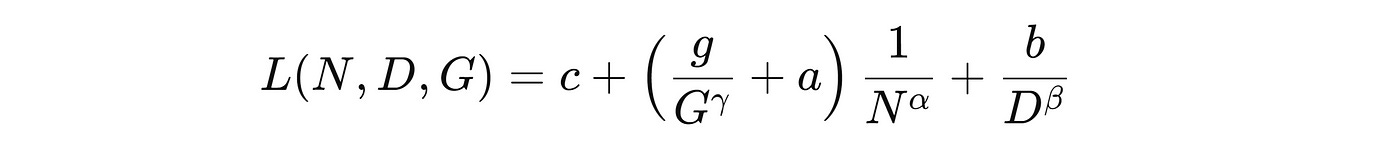
where:
L(N,D,G)is the final test loss of the MoE modelNis the total number of non-embedding parametersDis the number of training tokensGis the Granularity or the number of active Expertsa,b,g,γ,α,βare constants
According to these laws, increasing model size, more training tokens, and higher Granularity (the number of active Experts) influence the MoE model, leading to lower Loss and making it more efficient.
This unlocked an important insight —
We needed to use many tiny Experts to scale up the MoE architecture, rather than using a small number of large Experts as previously done.
How about millions?
But Routing To Millions Of Experts Is Hard
Routing an input query to a million Experts is a challenging task.
The process of routing or selecting the relevant Experts out of N total Experts for a given query goes like this.
First, the inner product between the input query vector and each Expert’s key vector is calculated.
These scores determine how relevant that Expert is to a given input query.
These scores are then sorted, and the top k scores are picked for routing.
This process is computationally expensive, and its complexity scales as the total number of Experts (N) and the dimensionality of the key and query vectors (d) grow.
This problem was solved by researchers, who introduced a new routing layer architecture.
Let’s talk about it next.
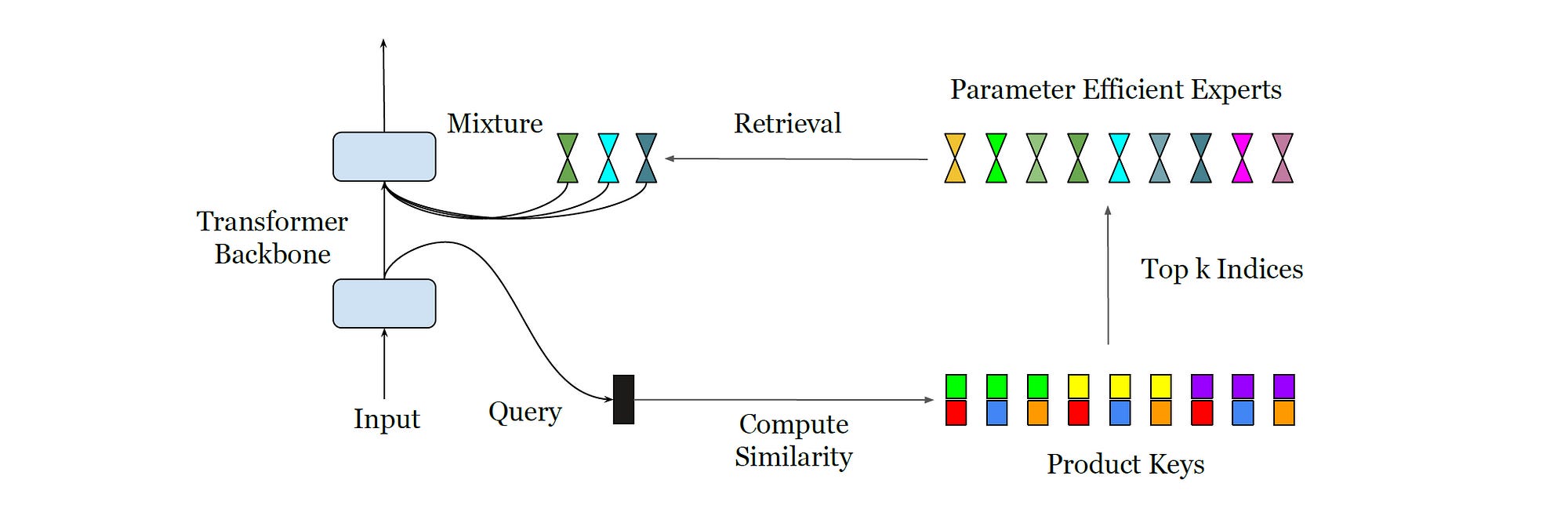
Here Comes The Parameter Efficient Expert Retrieval (PEER) Layer
Researchers at Google DeepMind solved the issue of inefficient routing by building a new layer architecture called Parameter Efficient Expert Retrieval (PEER).
A PEER layer can either be inserted amidst a Transformer backbone or used to replace its Feed-Forward layers.
This layer that is foundational to the Mixture-of-a-Million-Experts (MoME) architecture has three components:
A Pool of Experts
A set of Product keys (one corresponding to each Expert), where each key determines the relevance of each Expert for a given input query
A Query network that functions to map an input vector to a query vector (that is used to compare against the product keys to select the most relevant Experts)
Given an input vectorx, this is how the PEER layer operates.
The input vector
xis passed to a query network that produces a query vectorq(x)The inner products of this query vector with product keys (both with dimensions
d) are calculatedThe top
kExperts with the highest inner products are selected
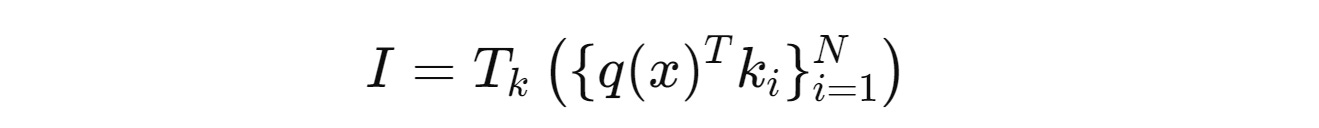
4. A non-linear activation function (Softmax or Sigmoid) is applied to the inner products of these top k Experts. This generates the Router scores that determine the importance of each selected Expert in the final output.
5. Each Expert’s output is multiplied by its corresponding Router score acting as a weight, and these values are linearly combined to produce the PEER layer’s final output.
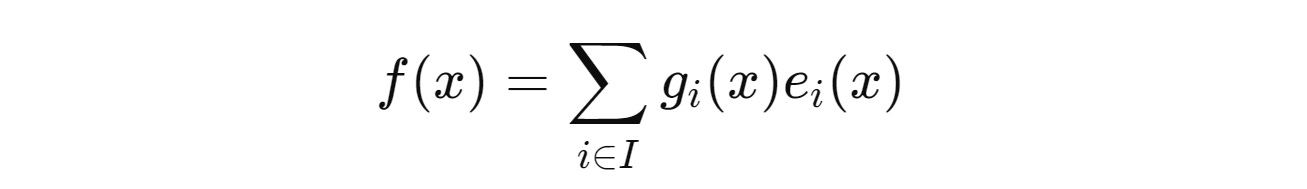
Now, look at the Step 3 equation, where we calculate the top-k indices.
This is where all of the inefficiency lies.
The complexity of this approach is O(Nd), where d is the dimensionality of the vectors and N is the total number of Experts.
This problem was solved in a 2019 published ArXiv research titled ‘Large Memory Layers with Product Keys’, where the researchers designed a structured memory that could fit into a transformer-based architecture to increase its performance and reduce its inference time.
The research introduced techniques for efficient product key retrieval, which were borrowed to construct the PEER layer.
This is how it works.
Instead of calculating N different d-dimensional key vectors, these keys are created by concatenating vectors from two sets of sub-keys.
These two sets of sub-keys are denoted using C and C’and each of them is d/2 dimensional and contains √N sub-keys.
This leads to a Cartesian product structure of the set of product keys K.
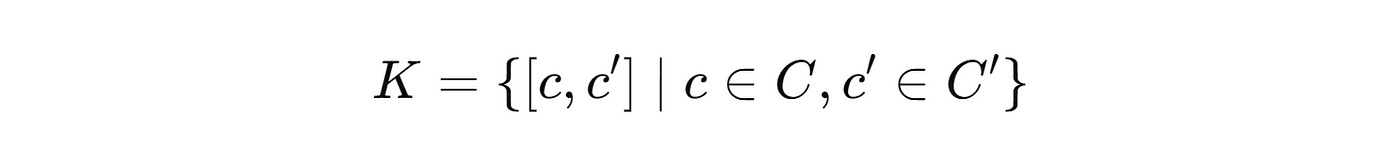
Similarly, the query vector q(x) is split into two sub-query vectors q(1) and q(2), each with d/2 dimensionality.
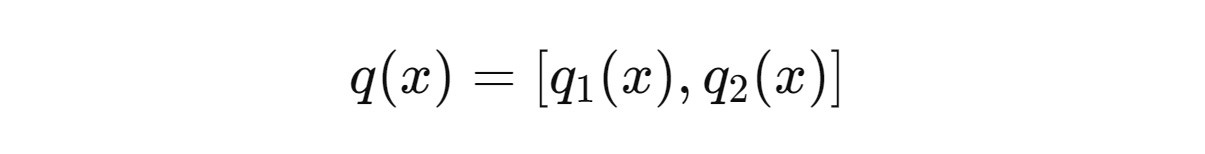
Next, the top-k Expert’s selection is made by calculating the inner products between these sub-key and sub-query vectors.
This results in two sets of top-k sub-keys: I(C) and I(C’).
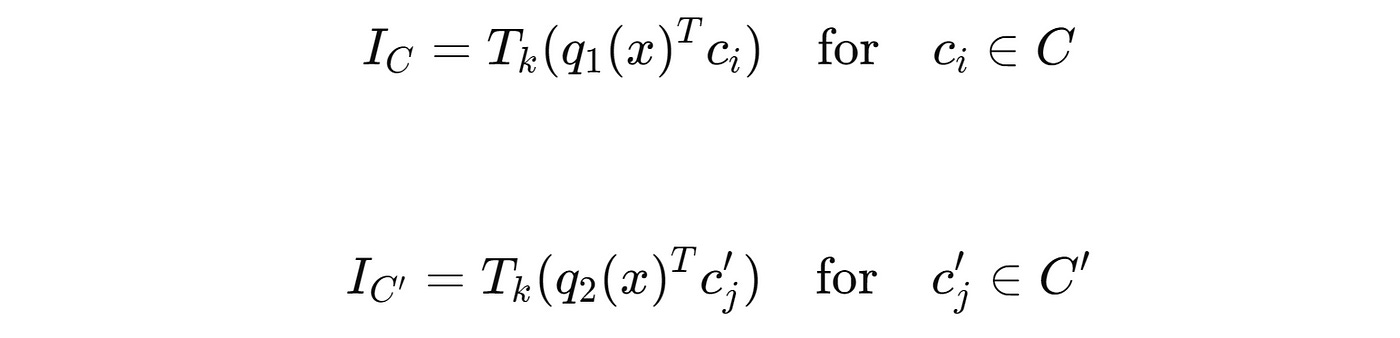
Then, the top-k sub-keys from these sets are combined to obtain k² candidate keys and this mathematically guarantees that the top k most similar keys to the query vectorq(x) are a part of this candidate set.
Moreover, the inner product between the candidate key and the query vector q(x) is simply the sum of inner products between the sub-keys and sub-queries.
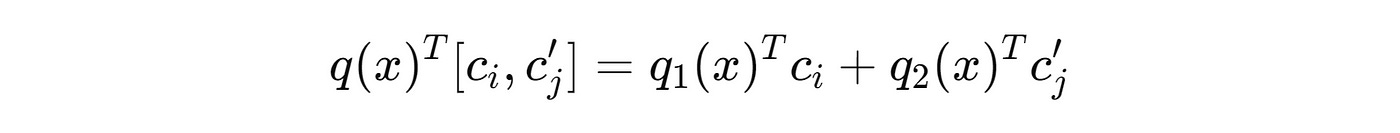
Consequently, the top-k operator can be applied again to these inner products to obtain the top-k matching keys from the original set of product keys (K).
Overall, in this approach, we use the Cartesian product, whereN keys are efficiently generated from √N sub-keys.
Since now we only need to compare with √N sub-keys instead of N full keys, this significantly reduces the complexity of the top-k selection process to O((√N+ k²)d) from O(Nd) as in the previous approach.
Scaling PEER Layer To Multiple Heads
In traditional MoEs, each Expert’s hidden layer was the same size as other Feed-Forward layers.
The Mixture-of-a-Million-Experts (MoME) architecture does it differently.
Here, each Expert is a singleton MLP, which means that it has only one hidden layer and a single neuron.
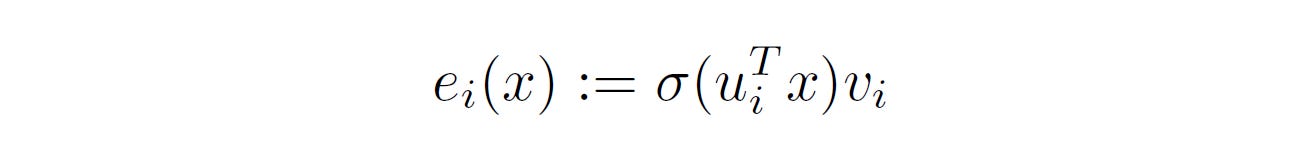
To improve Granularity (remember the Scaling law for MoEs), MoME keeps the size of the individual Experts to the minimum and rather uses Multi-head retrieval to increase its expressiveness.
This works similarly to the Multi-head attention in Transformers.
Instead of just one, multiple independent query networks (heads) from a shared pool of Experts (with the same set of product keys) compute their own query and retrieve a separate set of top-k Experts.
The results of these heads are then summed up to produce the final output.
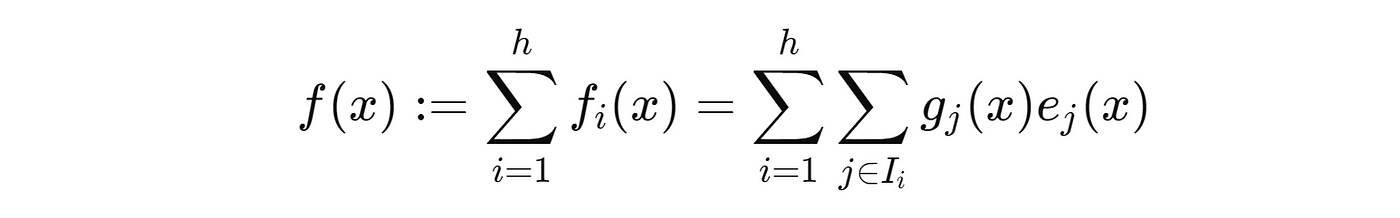
Pseudo-Code For Implementing PEER Layer Forward Pass
Let’s understand the pseudo-code of the PEER layer forward pass as described in the original research paper.
This will help us revisit the steps to learn how it works better.
def peer_forward (self , x):
# Embedding layers storing the down /up projection weights of all Experts
self . w_down_embed = nn. Embed ( num_embeddings = self . n_experts , features = self . d_model )
self . w_up_embed = nn. Embed ( num_embeddings = self . n_experts , features = self . d_model )
# Retrieve the weights of the top matching Experts using product keys
# indices and scores have the shape ’bthk ’, where h is the number of heads
indices , scores = self . get_indices ( self . query_proj (x), self . sub_keys , top_k = self .k)
w_down = self . w_down_embed ( indices )
w_up = self . w_up_embed ( indices )
# Compute weighted average of Expert outputs
x = jnp . einsum (’btd , bthkd -> bthk ’, x, w_down )
x = self . activation (x)
x = x * nn. softmax ( scores )
x = jnp . einsum (’bthk , bthkd -> btd ’, x, w_up )
return x
# bthkd means batch_size, time_steps, num_heads, top_k, dimension
# einsum is Einstein summationThe peer_forward function works by initializing the embedding layers that store the down and up projection weights for all Experts.
(The down-projection weights project the input to a lower dimensional space, while the up-projection weights project it back to a higher dimensional space.)
For a given input, it finds the indices and Router scores of the top matching Experts using a query network.
The top Experts’ projection weights are then stored into w_down and w_up.
The inputs are then combined with the down-projection weights using an einsum operation, and a non-linear activation function is applied to the result.
This result is multiplied by the Softmax normalized Router scores and then combined with the up-projection weights using another einsum (Einstein summation) operation.
Finally, these processed outputs are summed up to produce the final result.
Let’s finally learn how this architecture performs compared to its traditional counterparts.
Performance Of The MoME Architecture
The performance of the MoME architecture is quite remarkable, as demonstrated in various tasks.
Pretraining IsoFLOP Analysis
Pre-training refers to the initial phase of training an LLM on large amounts of unlabelled text.
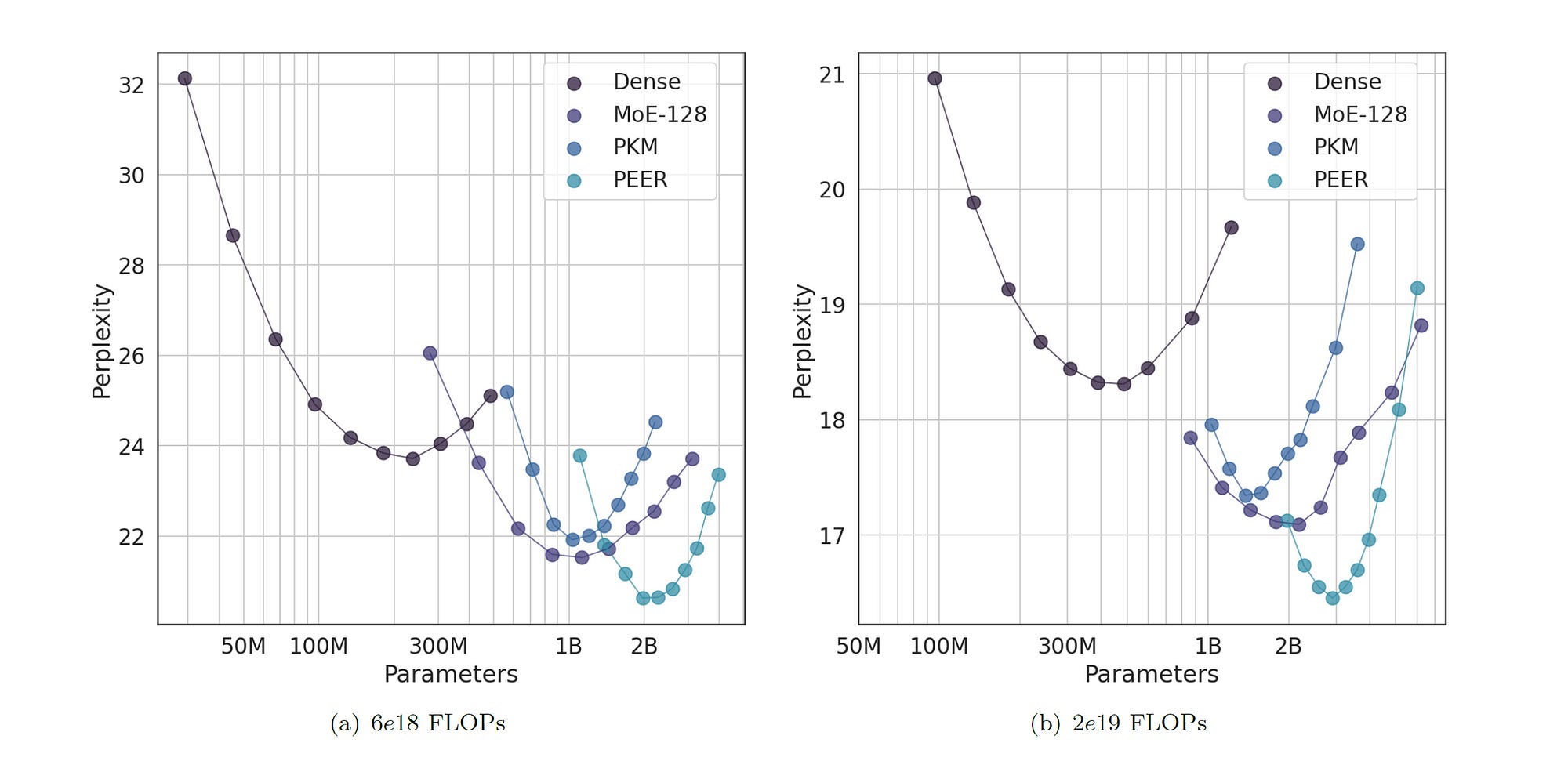
With this analysis, the researchers compare MoME’s Pre-training performance with other baselines under equivalent computational resources (hence, the term iso-FLOP) using the C4 dataset.
The four different models compared are:
LLM with Dense Feed-forward layers (FFW)
Mixture-of-Experts (MoE) with 128 Experts with Expert Choice Routing (where Experts choose the top-k token rather than token choosing the top-k Experts)
LLM with the Product Key Memory layer (PKM) with 1024² memories
LLM with the PEER layer (MoME architecture) with 1024² (i.e. 1,048,576) Experts
To create comparable models, dense models of different numbers of layers, attention heads and dimensions were chosen first.
Then, the Feedforward layer in the middle block of their Transformer was replaced by MoE, PKM and PEER layers.
The results show that compared to the dense FFW baseline, the other models shift the isoFLOP curves downward and to the right.
This downward and right shift might initially seem counterintuitive, as one might expect that adding more parameters would increase the computational cost (or it would push the curve upwards and right).
However, this is not true because even though these sparse models introduce a larger number of total parameters, they still activate and utilize a small subset of them.
The results are shown in the plots below, and it can be seen that given the same computing budget, the MoME architecture with the PEER layer attains the lowest compute-optimal perplexity.
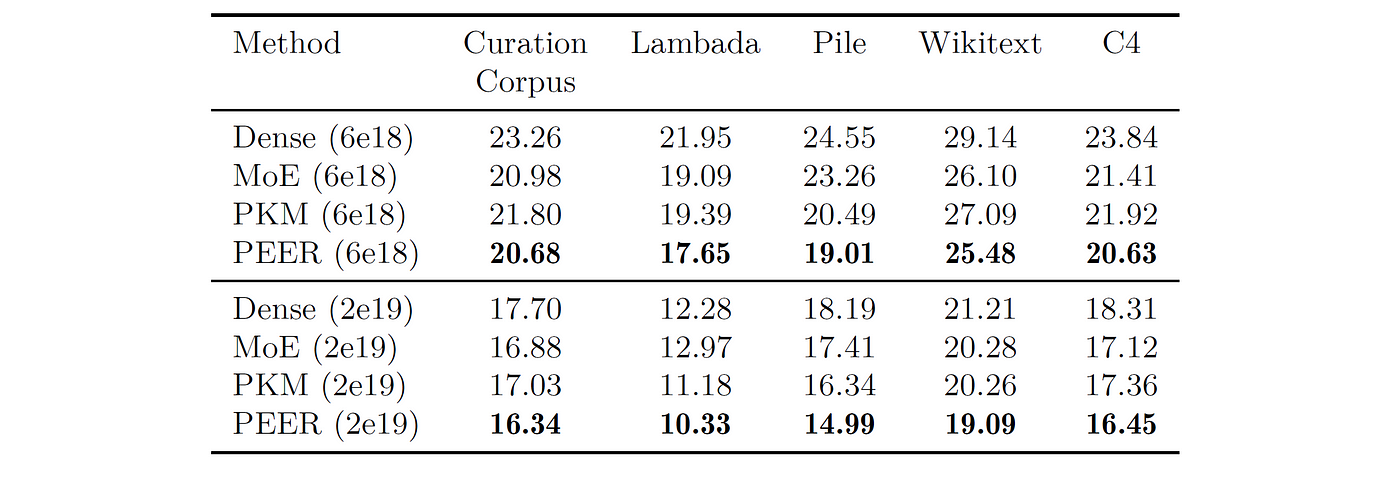
Performance On Language Modeling Datasets
After choosing the compute-optimal models from the isoFLOP analysis, their performance is evaluated on many popular language modeling datasets.
The results show that the MoME architecture again achieves the lowest perplexities compared to other models.
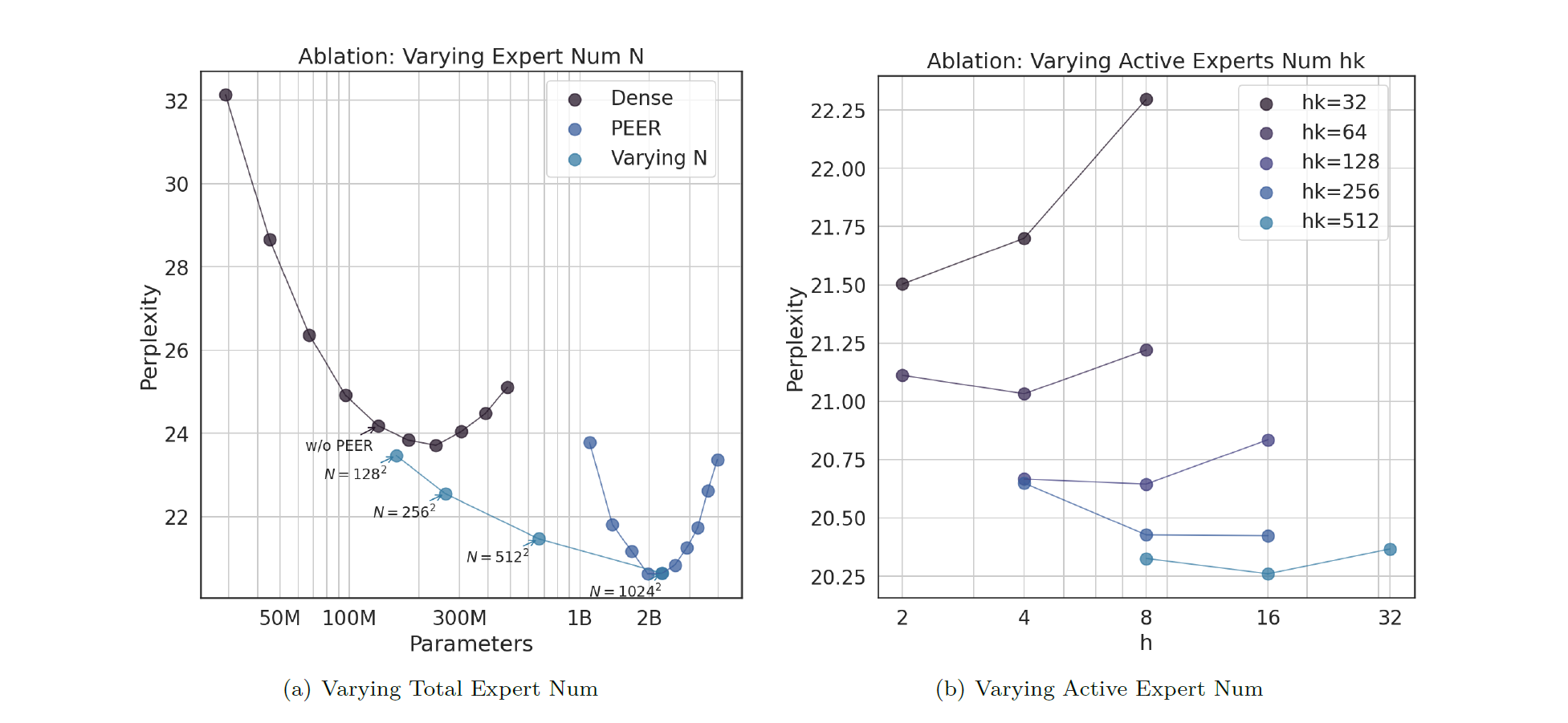
Performance Of Variations Of The MoME Architecture
The researchers next study how varying numbers of total and active Experts affected perplexity.
It is found that simply increasing the number of total Experts improves the performance without any added cost.
However, when the number of active Experts is changed while keeping the total number of Experts constant, the performance improves until a certain point, after which it saturates and increases memory consumption.
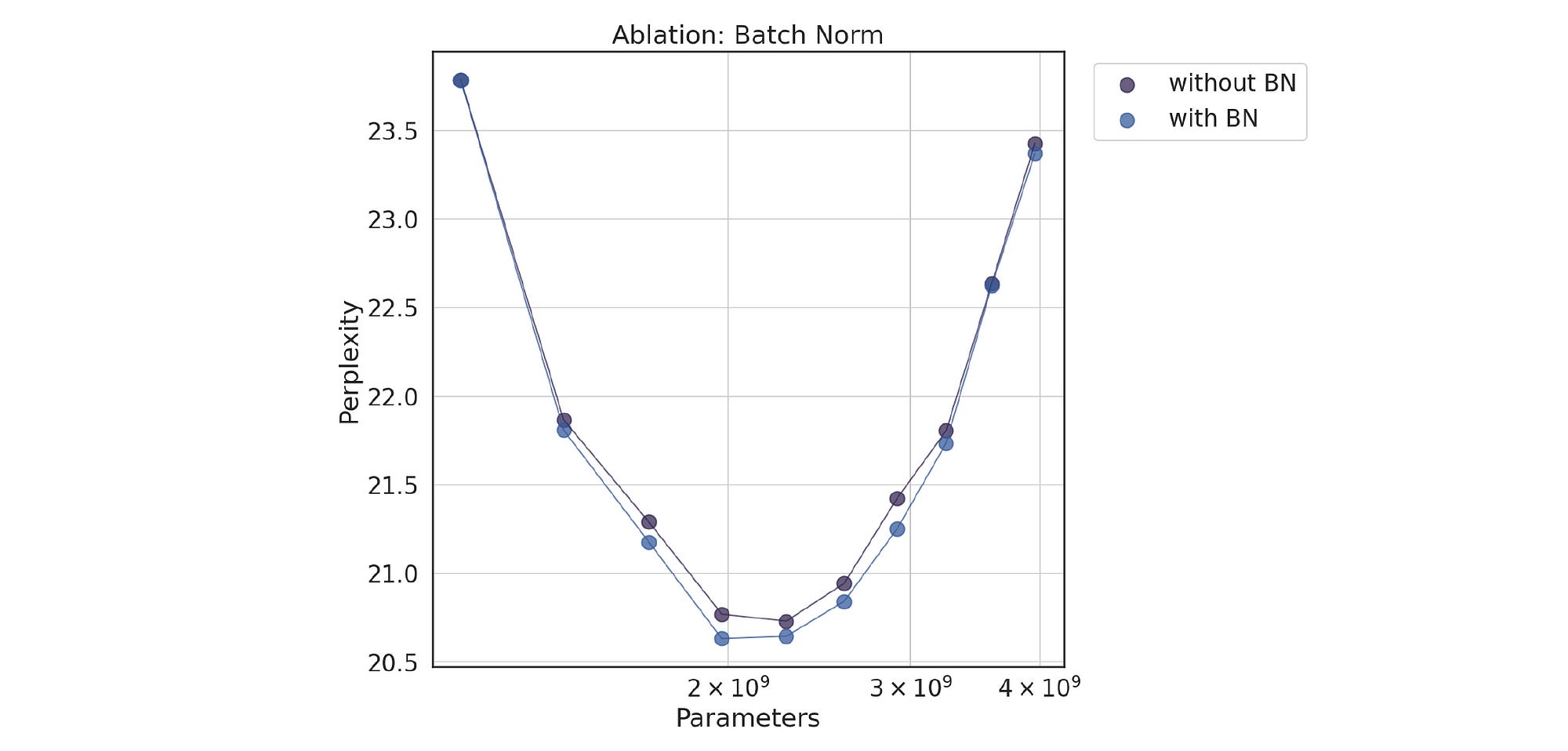
Performance Difference With Query Batch Normalization
The researchers finally study the role of Query Batch Normalization (where the query vectors are normalized across a batch of inputs before their usage) on the model’s Perplexity.
Two additional metrics are used in this analysis.
Expert Usage: This is the number of active Experts during inference.
KL Divergence/ Unevenness: This measures how much a given probability distribution deviates from the Uniform distribution.
The results show that using query Batch Normalization leads to a more balanced use of the Experts and obtains lower perplexities.
It should also be noted how the model’s Expert Usage is close to 100%, even for more than a million Experts!

Additionally, the isoFLOP curves show that the model generally achieves lower perplexities (especially around the isoFLOP-optimal region) when it uses Query Batch Normalization.
The results from this research paper are exceptional, and I am quite optimistic about how this will positively alter the future of LLMs.
What are your thoughts about it? Let me know in the comments below.
Further Reading
Research paper titled ‘Mixture of A Million Experts’ published in ArXiv
Research paper titled ‘Large Memory Layers with Product Keys’ published in ArXiv
Research paper titled ‘Mixture-of-Experts with Expert Choice Routing’ published in ArXiv
Research paper titled ‘Scaling Laws for Fine-Grained Mixture of Experts’ published in ArXiv