
Is OpenAI’s o1 The AI Doctor We’ve Always Been Waiting For? (Surprisingly, Yes!)
A deep dive into o1’s performance in Medicine, its strengths and weaknesses, and how it can be further enhanced towards an early promising AI doctor candidate.


OpenAI’s o1 is out, and its performance on STEM tasks is mind-bending!
Quoted from OpenAI’s research article titled ‘Learning to Reason with LLMs’:
OpenAI o1 ranks in the 89th percentile on competitive programming questions (Codeforces), places among the top 500 students in the US in a qualifier for the USA Math Olympiad (AIME), and exceeds human PhD-level accuracy on a benchmark of physics, biology, and chemistry problems (GPQA).
The model has been trained using Reinforcement learning and uses a long internal Chain-of-Thought approach to think through the problem before generating an output.
Its performance scales incredibly with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute).
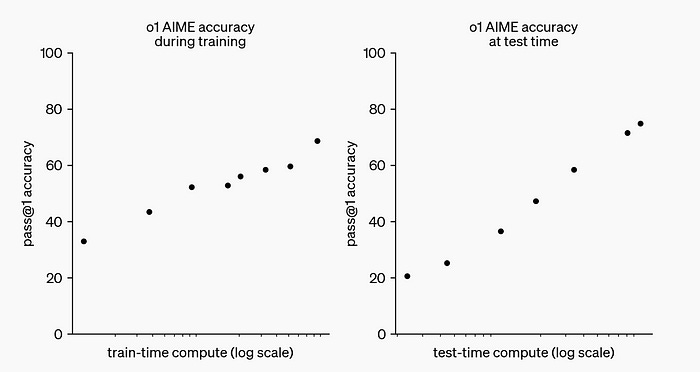
Whether mathematics, competitive programming, or Ph. D-level questions in Physics, Chemistry, and Biology, it answers them all with a high degree of correctness.

And, its performance is substantially higher than the previous state-of-the-art GPT-4o.

But what about Medicine?
Reserachers of this new pre-print on ArXiv answered precisely this.
Keep reading with a 7-day free trial
Subscribe to Into AI to keep reading this post and get 7 days of free access to the full post archives.