

The Hidden Optimization Every LLM Uses
Why KV Cache is a non-negotiable for LLM systems.



This week’s newsletter introduces you to optimization techniques that are used extensively by LLM-based applications today.
It is written by the guest author Nikhil Anand from AI Made Easy.
Nikhil is a Research Associate at Adobe and a graduate of the Indian Institute of Technology, Madras. He loves unpacking challenging AI concepts using intuitive visual explanations in his articles.

Follow and connect with him through the links given below:
Newsletter AI Made Easy
Let’s get started!
When I first started using LLMs locally, I generated tokens one at a time in a loop. This took several minutes to process each prompt.
A little later, I discovered that the model generate function could output tokens much faster.
A question that took 3 minutes now takes 15 seconds.
I had to figure out why.
Turns out, the generate function was using something called KV Cache.
In this blog, we’ll talk about KV Cache — what it is, how it makes LLMs ridiculously more efficient, and how you can scale it.
How Does Attention Actually Work?
Let’s start with the basics.
Every time an LLM generates a new token, it needs to “pay attention to” all the previous tokens in the sequence.
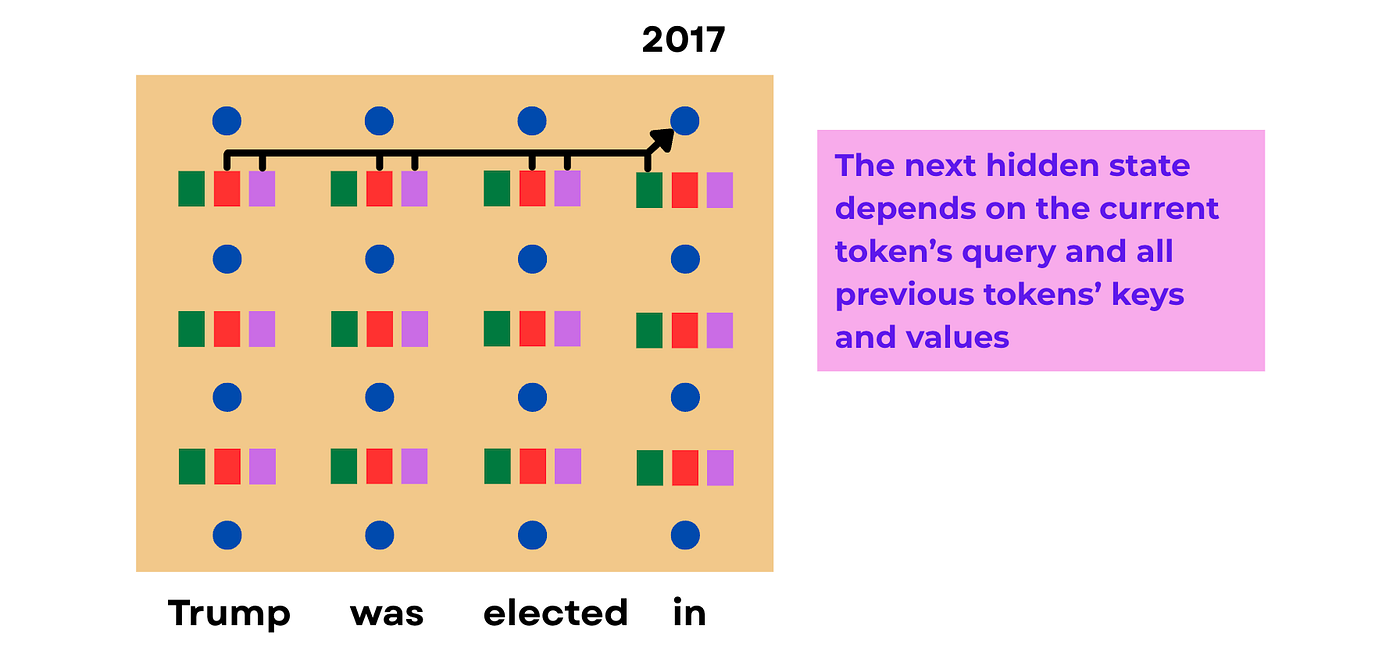
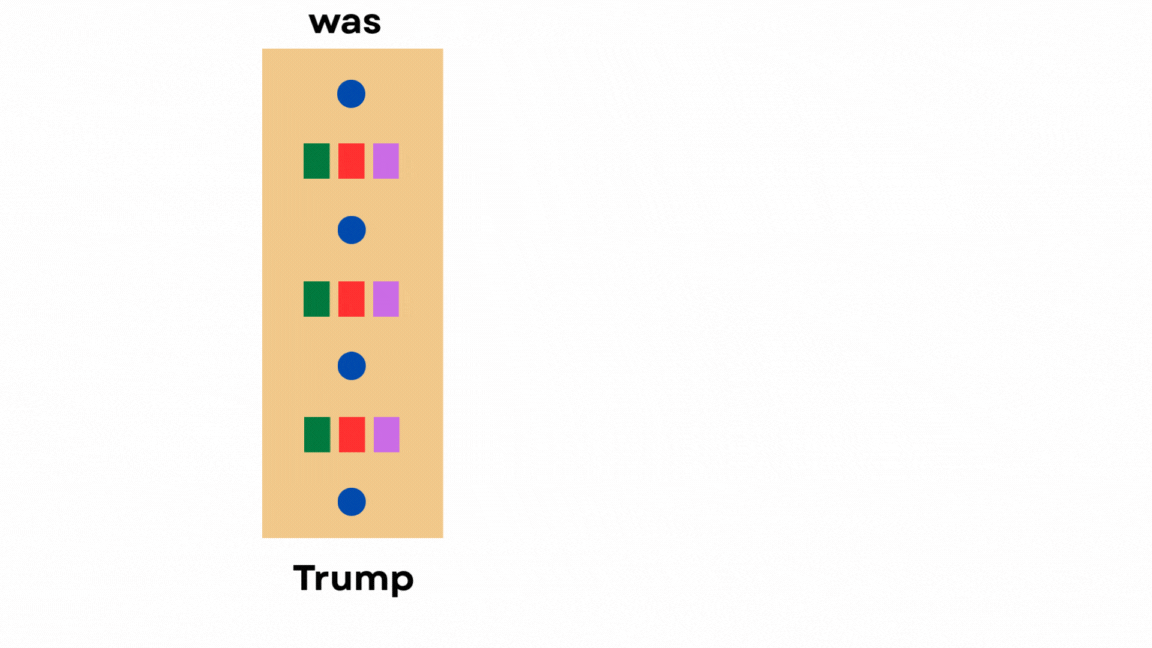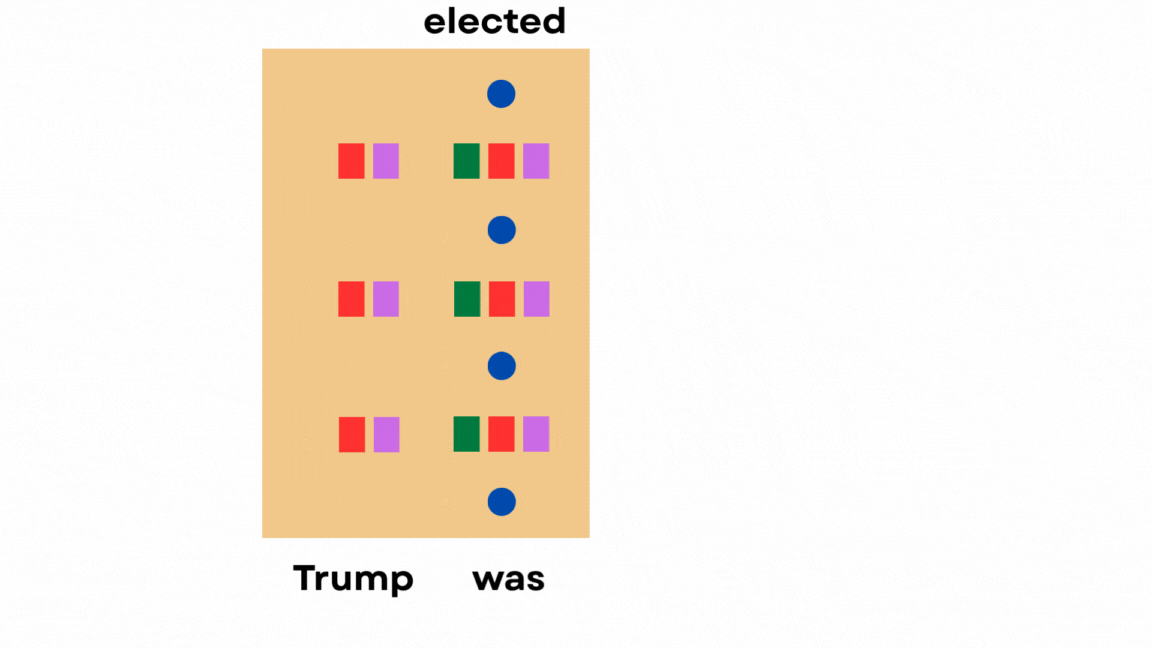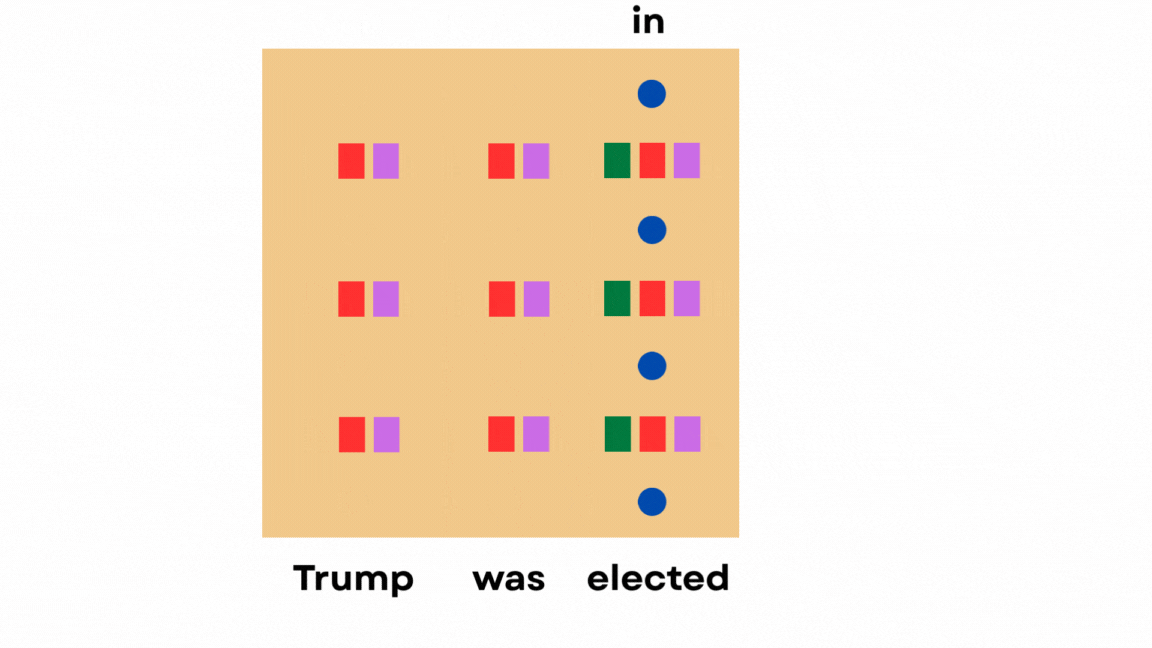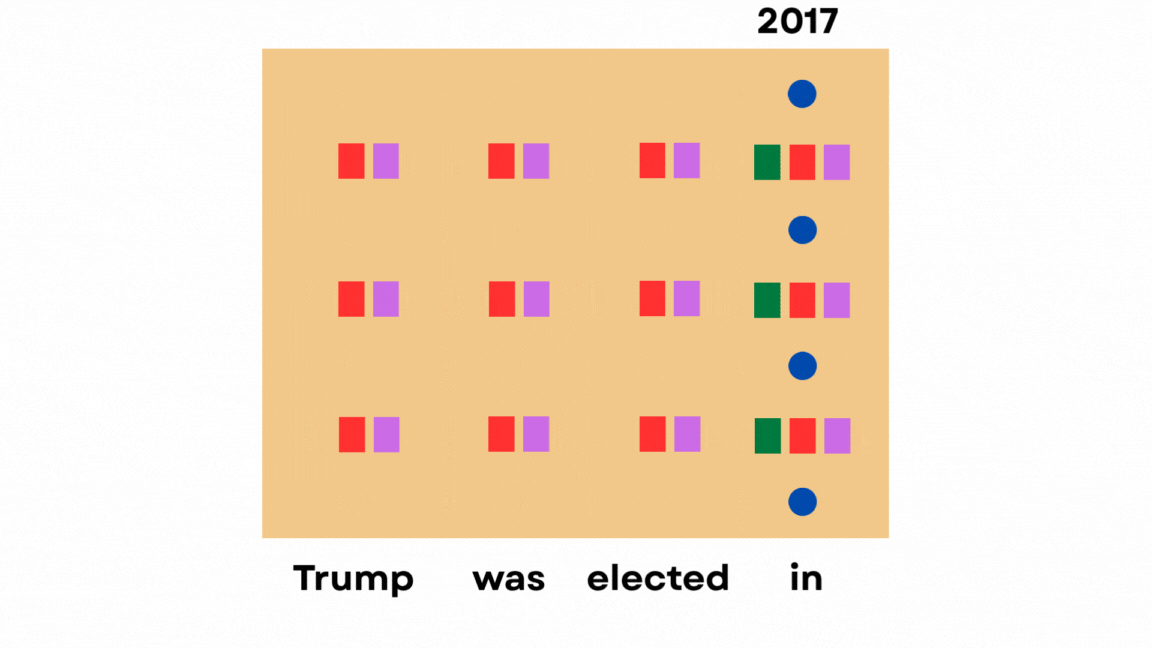
For instance, let’s say we have the sentence “Trump was elected in”. To predict the next token (which would be “2017”), the model needs to look back at the word “Trump” and understand the context.
Here’s how Attention works.
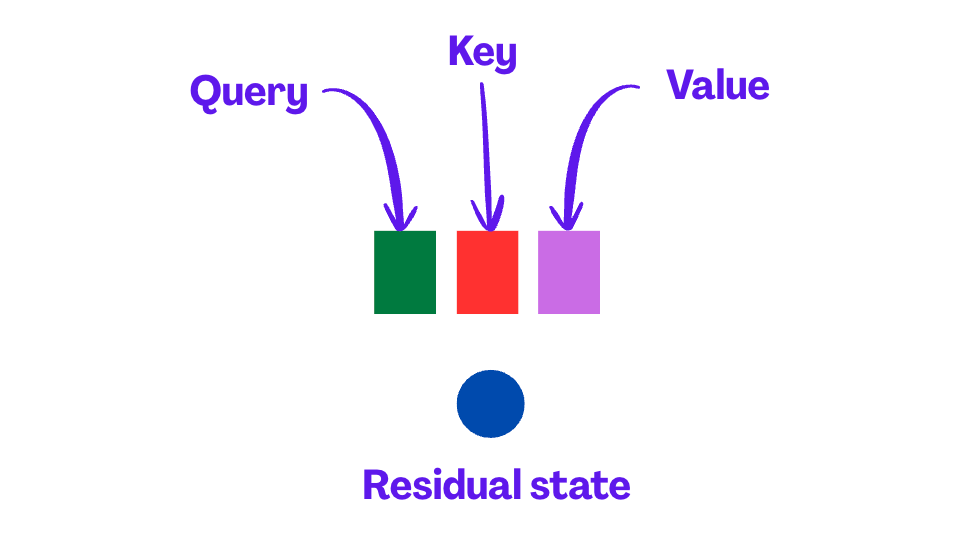
At every layer of the transformer, the model computes three things for each token:
Queries (Q): what the current token is “looking for”
Keys (K): what information each previous token contains
Values (V): the actual information from previous tokens
It also captures a residual state, which is the vector representation in the “transition area” after one attention layer and before the next.
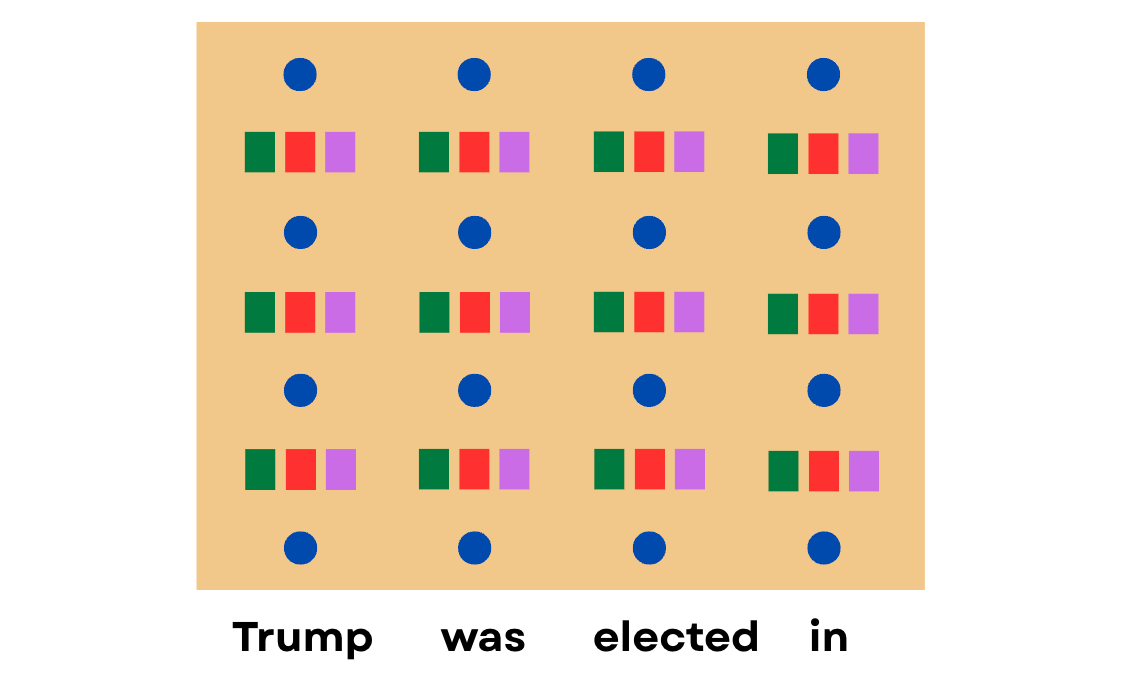
After passing a prompt, the entire hidden state gets populated like this:
The current token’s query “attends to” all previous tokens by looking at the keys of the previous tokens, and the values of the previous tokens contribute with different weights to the current token’s hidden state.
This is how attention is captured in LLMs, and how previous tokens can influence the next token output.
The Problem: Why Generating Tokens Is Painfully Slow
Consider this code snippet:

I create a string and keep passing it into the generate function to get the next token.
The generate function passes the string into the LLM and predicts the next token.
This could take a ridiculously long time.
Why? Because every time we call generate, we have to pass the whole string again.
The Solution: Just Cache The Previous Values
How do we solve this problem?
Pretty simple.
Just cache the hidden states of previous tokens instead of clearing the memory every time, so that future tokens can reuse them.
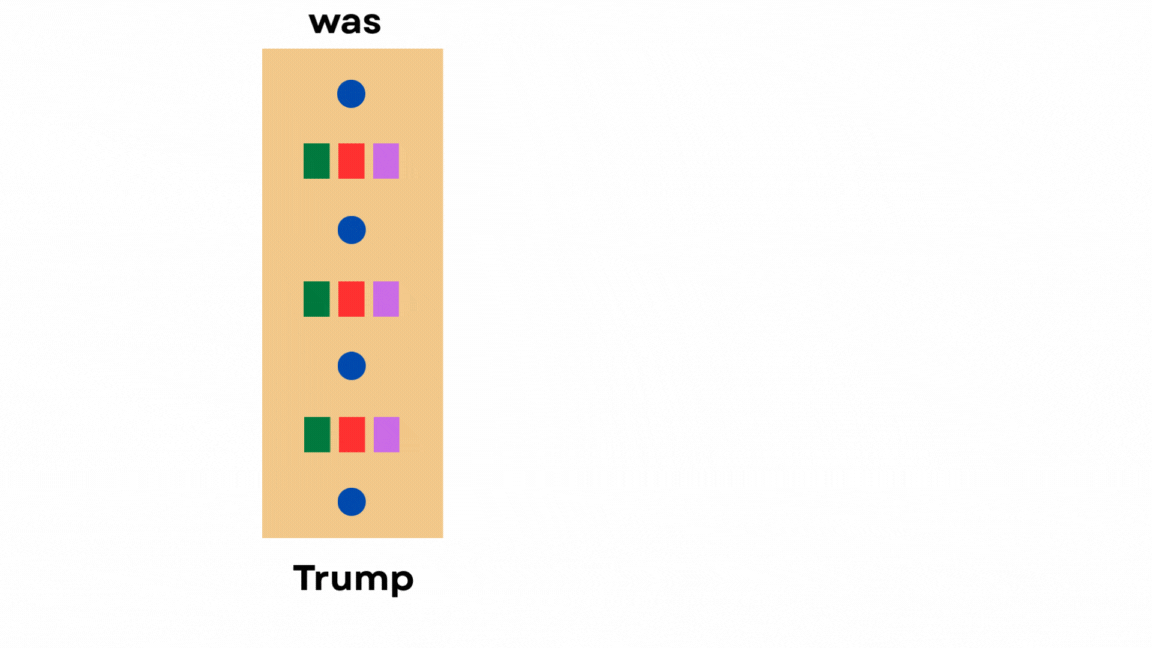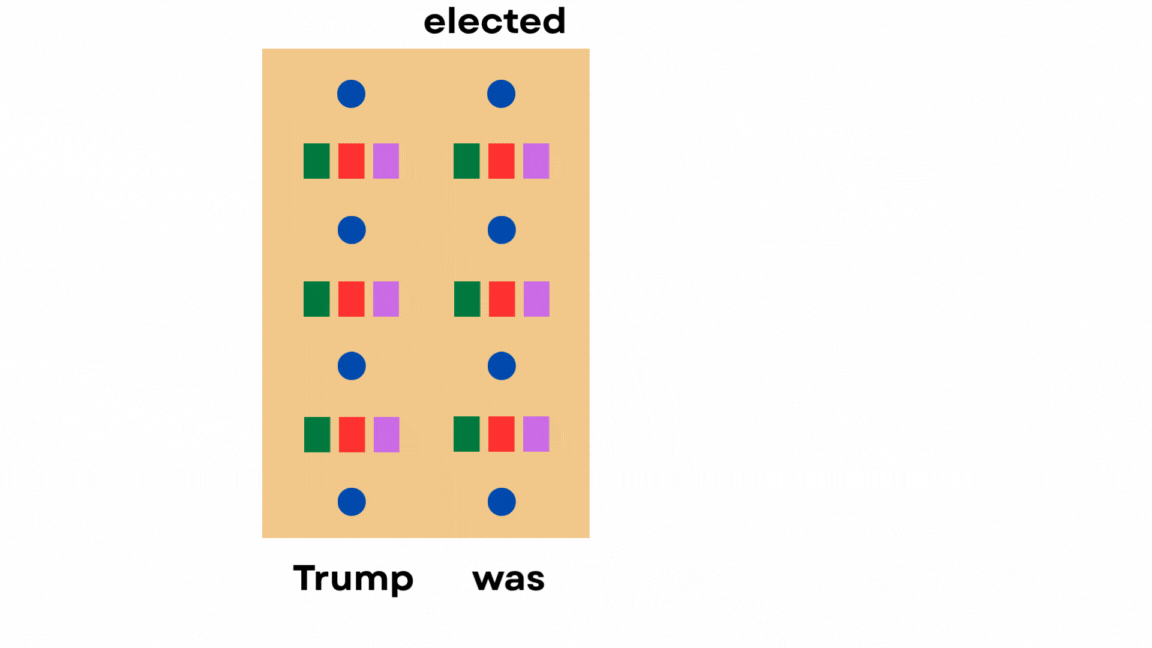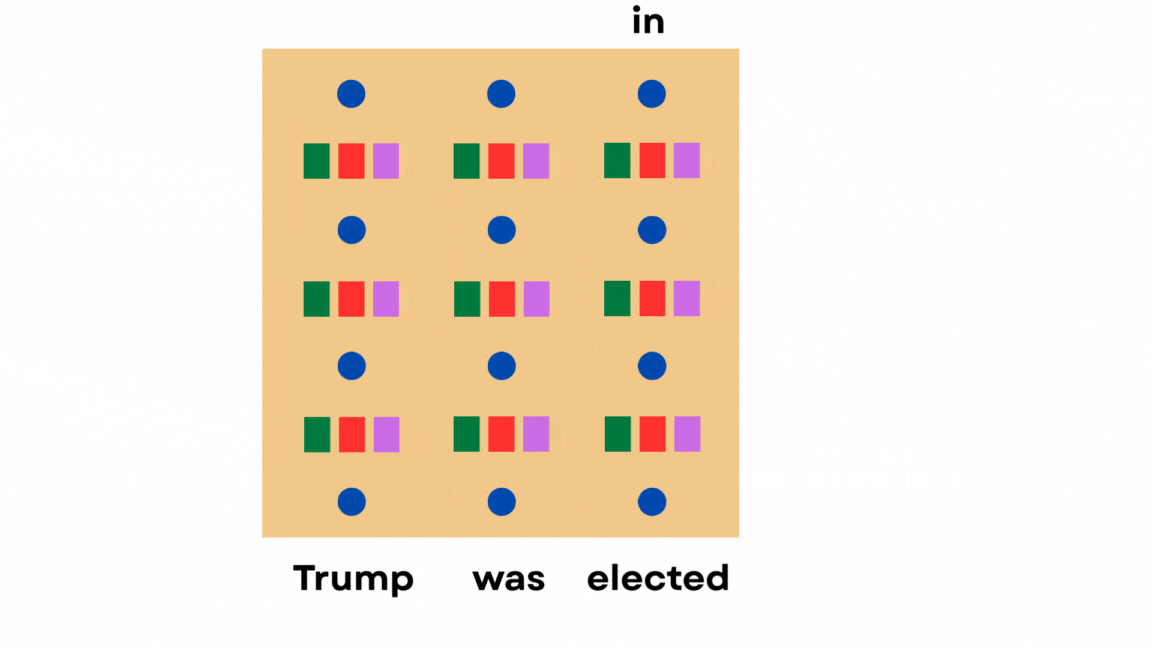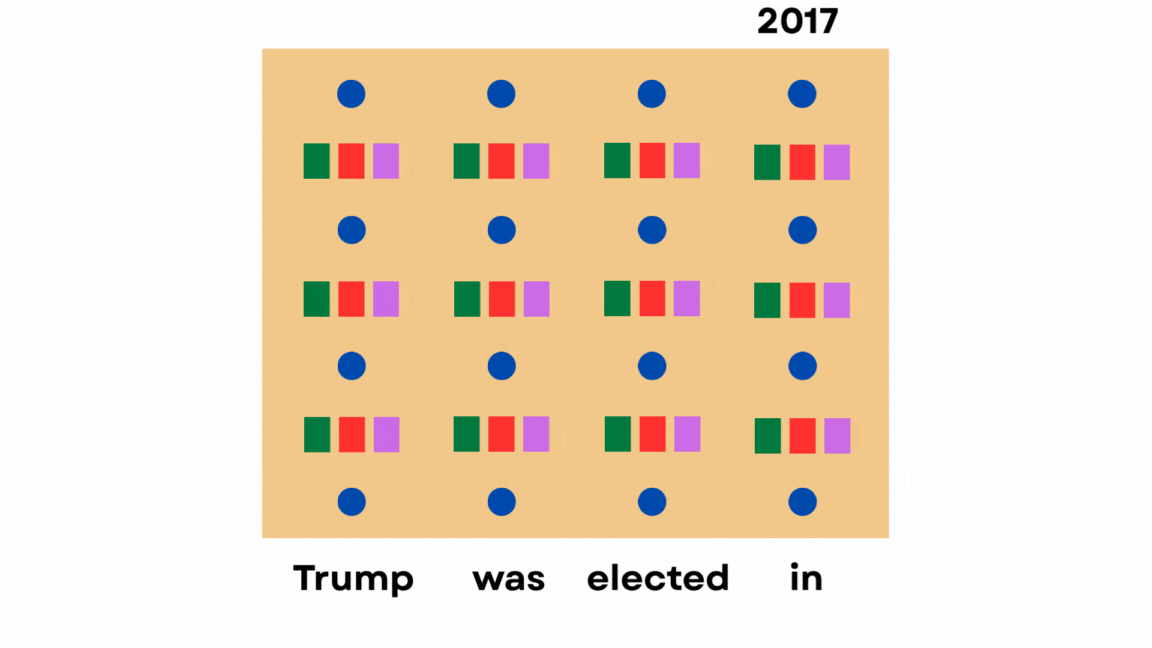
But here’s the thing.
The model only needs the keys and values of past tokens to attend to them. It doesn’t require any of the other hidden states.
So we only cache the keys and values, which is why it’s called KV Cache.
Now if I run model.generate(”Trump”, n_tokens=10), it can generate multiple tokens one at a time without repeating all those operations.
Prefill vs. Generation
The initial forward pass is often called the Prefill, and subsequent passes are called Generation.
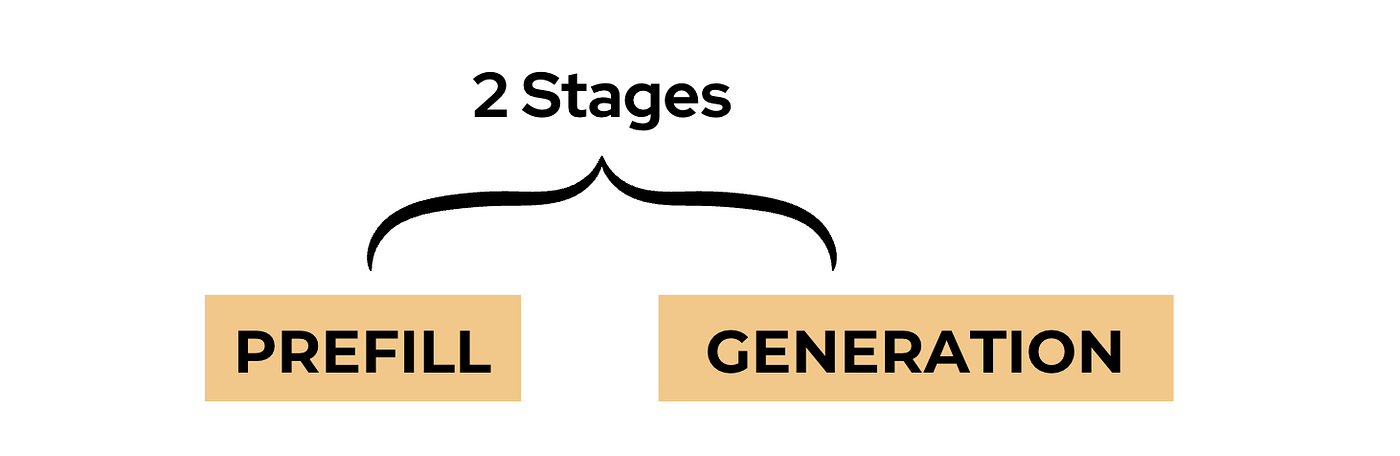
Let me give you an example.
Imagine you have a long context prompt that you’re asking questions about.

Loading this context onto the LLM is called the Prefill phase.
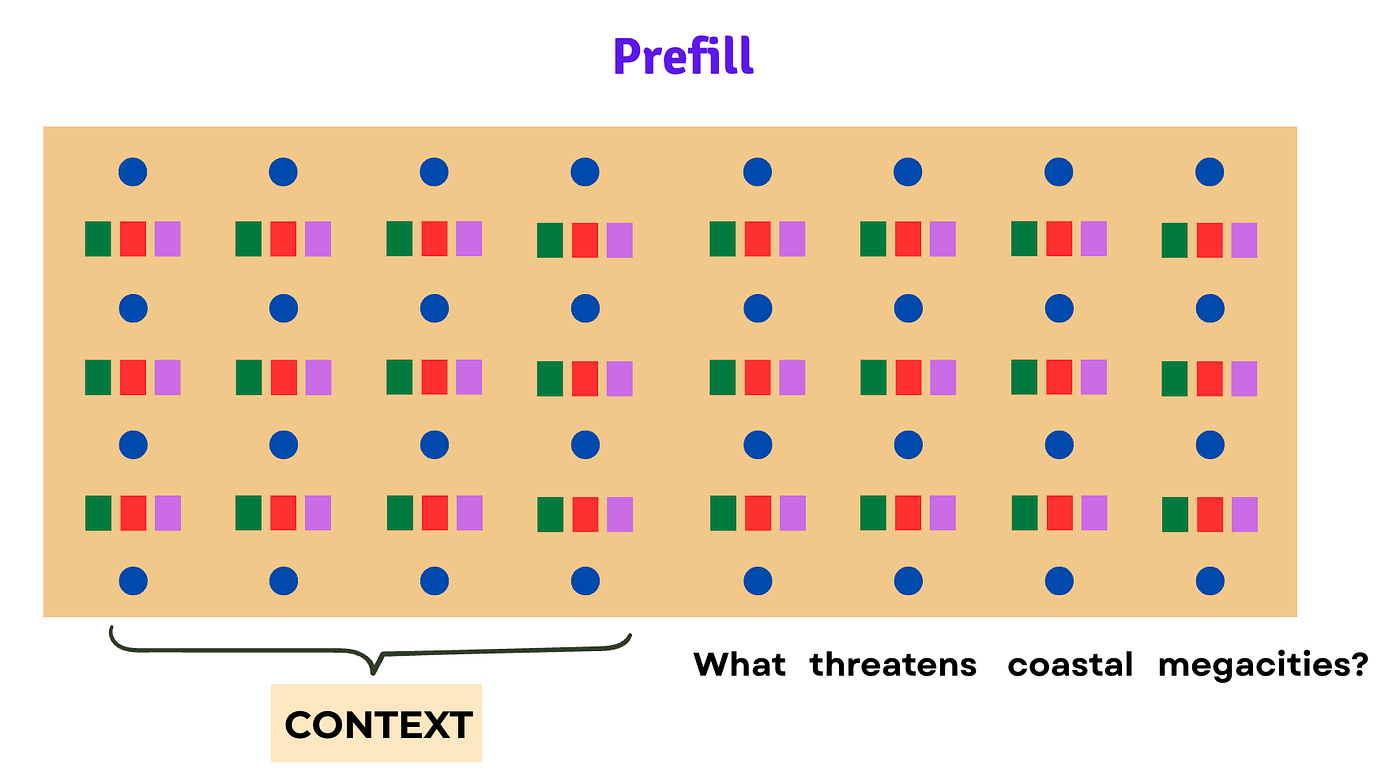
Since the context is so long and spans so many tokens, the Prefill takes time. (Let’s say, 10 seconds.)
We can see the benefits of KV caching here.
Without the KV cache, repeated forward passes would take up to 10 seconds for every single token to be generated.
But with KV cache, only the first token takes 10 seconds to generate. Subsequent tokens take way less time (maybe 0.1 seconds each) since the context has already been loaded and cached.
This first delay is called Time to First Token (TTFT), and the subsequent generations are much faster because we’re reusing cached values.
Could We Optimize Things Even More?
Think of another use case.
What if you have a RAG app where you ask multiple questions based on the same context?
This is an opportunity for us to use Prefix caching.
Since contexts match across prompts, we can reuse the context’s keys and values instead of repeating the Prefill every time.
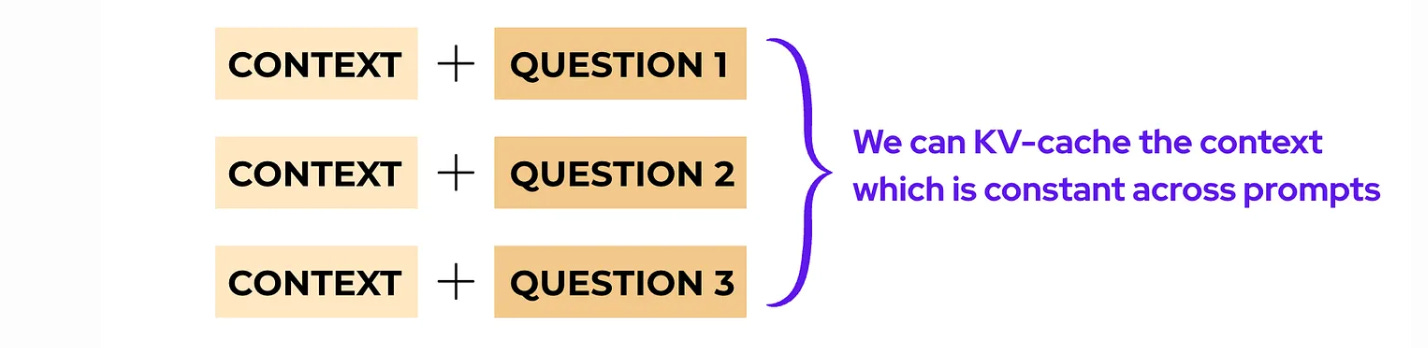
For example:
First query: “Here’s a document about quantum physics… What is quantum entanglement?”
Second query: “Here’s a document about quantum physics… What is superposition?”
The context (the document) is the same, so we cache it. Since only the question changes, it needs to be processed afresh.
Sharing KV Caches Across Users
Now we can even share KV caches between users in a shared disk system.
Think about it.
Multiple users might have the same context but different questions.
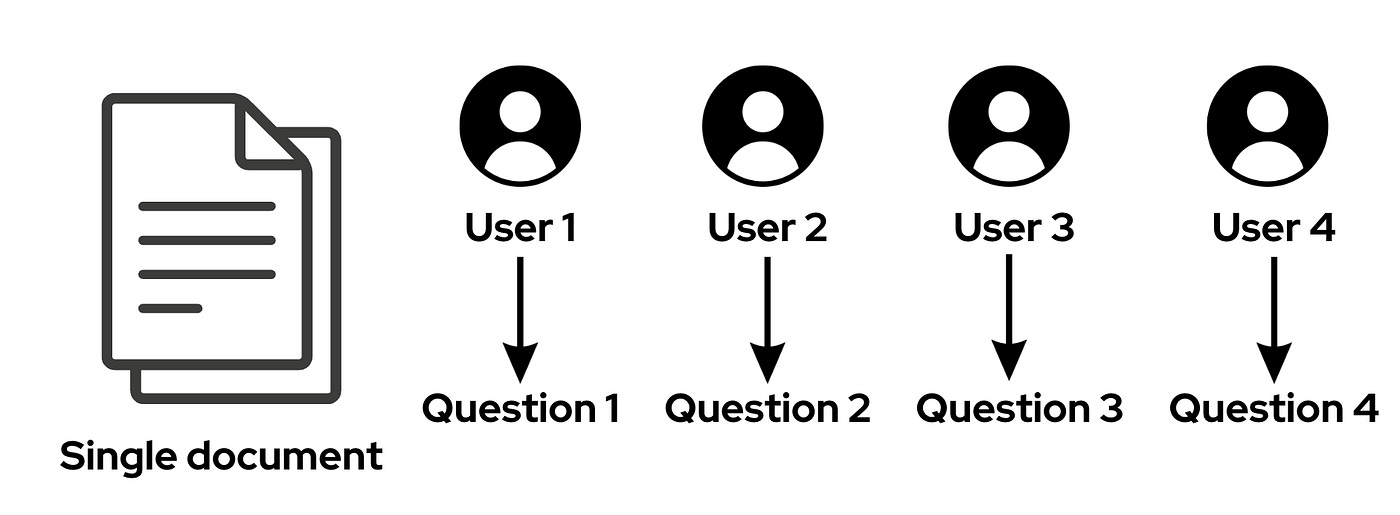
The system could easily be made more efficient if KV’s of one user are reused by another who is working with the same context.
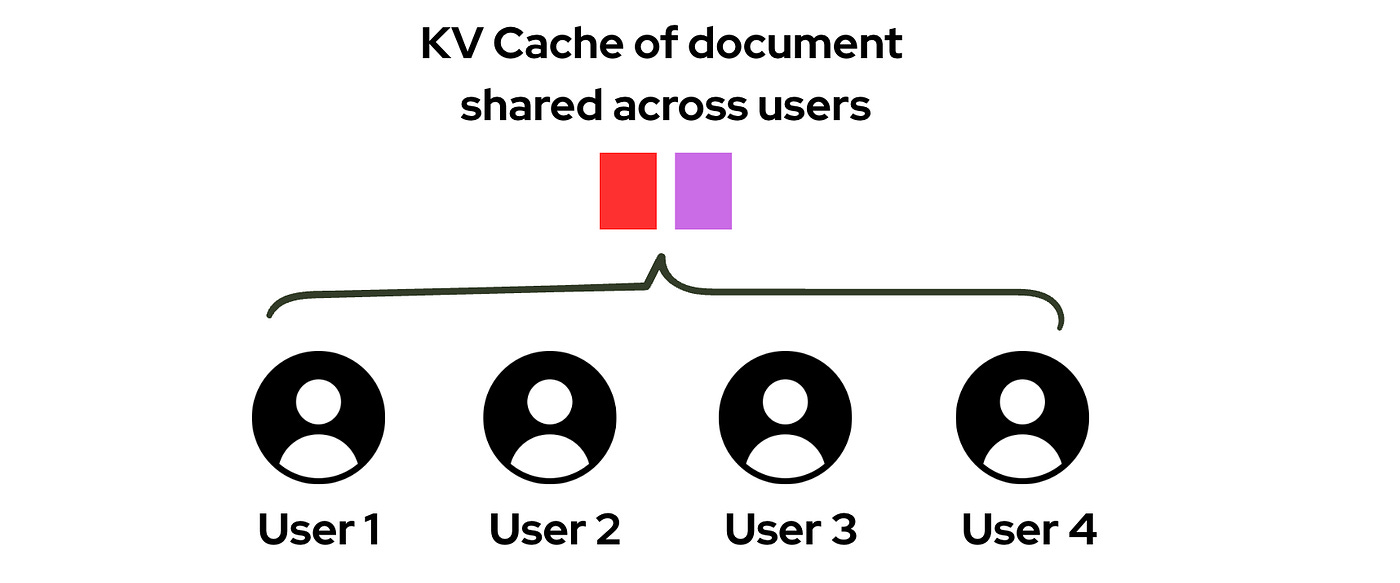
Currently, an open-source library called vLLM allows people to serve LLMs hosted locally, and these LLMs are optimised as much as possible.
The processes are made super efficient, such that if one user asks a query whose prefix matches the query of another user, the system automatically catches on and reuses those KVs.
Closed-source LLMs like OpenAI’s API probably do something similar internally to cut costs, but we don’t get to hear about it.
Wrapping Up
In this blog, we discussed KV Cache — a simple yet incredibly powerful technique that makes LLMs significantly more efficient.
The first forward pass (Prefill) takes time, but subsequent token generations are lightning fast.
If you’re building anything with LLMs — a chatbot, a RAG app, or a multi-user system — and you’re not efficiently caching KVs, you’re leaving massive performance gains on the table.
Start using it. Your users (and your server bills) will thank you.
I would like to thank Nikhil again for writing this valuable article! Don’t forget to subscribe to AI Made Easy by Nikhil Anand.

Unlock access to every article on ‘Into AI’ by becoming a paid subscriber:

 | A guest post by
|