

LLMs Don't Really Understand Math.
A deep dive into the latest research showing that current state-of-the-art AI is not capable of understanding and solving math as popularized.


We are in an AI bubble right now.
There’s a lot of hype around the current capabilities of AI.
Some say it will make extremely skilled jobs like Software Engineering and Medicine obsolete.
Others warn of an upcoming AI apocalypse within the next few years.
These claims are far from the truth.
Yes, AI might someday take over our jobs, but the current AI architecture is incapable of doing that and has been juiced out.
LLMs, based on the Transformer architecture, are great next-word predictors and language generators, but there’s much evidence that they cannot reliably solve maths.
They can reliably fake doing so but lack true logical reasoning capabilities at their core.
Here’s a story in which we discuss the performance of the current state of AI in mathematical tasks, the reasons for this, and debunk the lies sold to us by big tech.
Linda Problem Breaks LLMs When It Becomes A Bob Problem
Have you heard about the classical Linda problem?
It is an example from cognitive psychology that shows the Conjunction fallacy.
In simple terms, this fallacy occurs when people mistakenly judge the likelihood of two events happening together (or in conjunction) as being more likely than the likelihood of one of the events alone when this is not mathematically true.
The problem goes like this:
Linda is 31 years old, single, outspoken, and very bright.
She majored in philosophy.
As a student, she was deeply concerned with issues of discrimination and social justice, and also participated in anti-nuclear demonstrations.
Which is more probable?
A. Linda is a bank teller.
B. Linda is a bank teller and is active in the feminist movementThe answer?
Statement A must be more likely than statement B because, mathematically, the probability of a conjunction P(A and B) is always less than or equal to the probability of any single event P(A) or P(B).
Take a look at what happens when GPT-4 answers this.

When prompted in a one-shot fashion, GPT-4 correctly identifies the conjunction fallacy and answers the question correctly.
But changing the name of Linda to Bob confuses it, and its logical reasoning goes down the drain.
(I tested the same on GPT-4o, and yes, it answered incorrectly.)
The researchers of this ArXiv paper generate several other tweaked questions and statistically analyse the performance of LLMs on them.

They consistently (with statistical significance) find that LLMs have a huge Token bias.
This means that LLMs largely rely on specific patterns or tokens in the input text when solving problems rather than truly understanding them.
Take a look at another example.
The “Twenty-five Horses” problem goes like this:
There are 25 horses.
The horses can only race five at a time, and you cannot measure their actual speeds;
you can only measure their relative rankings in a race.
The challenge is to find the minimum number of races needed to find the top three horses.Changing this problem to a “Thirty-Six Bunnies” problem again confuses GPT-4 and Claude 3 Opus, and they incorrectly solve this problem.

Apple Breaks The Ice With GSM-Symbolic
The GSM8K (Grade School Math 8K) benchmark is popularly used to assess LLMs' mathematical reasoning.
This dataset comprises 8.5 thousand high-quality linguistically diverse grade school math word problems.
The questions here are relatively simple for humans and require knowing only the four basic arithmetic operations (+ − × ÷) to reach the final answer.
These questions require multi-step reasoning, but a bright middle school student should still be able to solve every problem in this dataset.
Check out an example:
{
'question': 'Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May.
How many clips did Natalia sell altogether in April and May?',
'answer': 'Natalia sold 48/2 = <<48/2=24>>24 clips in May.
\nNatalia sold 48+24 = <<48+24=72>>
72 clips altogether in April and May.
\n#### 72',
}All state-of-the-art LLMs (including Claude, GPT-4o, o1, and Gemini) perform exceptionally well on GSM8K, but Apple researchers have questioned these metrics.
To test their hypothesis, they tweaked this benchmark using templates and generated variations of questions based on these.
Their modifications include changing names/ numerical values and adding or removing clauses from the original questions in GSM8K.
They called their new benchmark — GSM Symbolic.

Their LLM evaluation using this modified benchmark reveals some striking findings.
The average performance of most LLMs on GSM-Symbolic is lower than GSM8K (shown by the dashed line in the image below).
Also, there is significant variability in the accuracy of LLM responses across questions generated using GSM-Symbolic templates.

This performance drop is large for models like Mistral-7b-it and Gemma-2b-it compared to GPT-4o.

There’s another interesting finding that tells that LLMs are pattern matching based on their training data when solving mathematical problems.
As seen in the plots below, LLMs' performance significantly drops when the names, numbers, or both are changed in the original problem.
This should not be happening if LLMs really understood maths.

Reserachers took this evaluation further by generating three more datasets from GSM-Symbolic with different difficulty levels.
These are as follows:
GSM-Symbolic-Minus-1 (
GSM-M1): by removing a single clause from the original problemGSM-Symbolic-Plus-1 (
GSM-P1): by adding a single clause to the original problemGSM-Symbolic-Plus-2 (
GSM-P2): by adding two clauses to the original problem

The accuracy of all LLMs drops, and the variance increases as the number of clauses in the problems increases.
Surprisingly, this is true for OpenAI’s o-1 mini, a model specifically trained for better reasoning, as well.

Researchers don’t stop here. They further push these LLMs using a further modified dataset called GSM-NoOp.
GSM-NoOp is created by adding seemingly relevant statements to the problems that are in fact, irrelevant to the reasoning and conclusion.

Most models fail to ignore these statements and blindly convert them into additional operations, making dumb mistakes.
OpenAI’s most advanced reasoning model, o1-preview, experiences a 17.5% performance drop, and Phi-3-mini has a 65% drop over GSM-NoOp!

The full results of all models are shown below.

But OpenAI Must Be Safe, Right?
OpenAI’s most advanced reasoning models, o1-mini and o1-preview, resist the accuracy drop as the questions become more difficult.

However, both experience a significant accuracy drop on GSM-NoOp.
This is evident from o1-preview's response to this simple math problem tweaked with an irrelevant clause, shown below.
(However, it is worth mentioning that OpenAI’s current most advanced reasoning model, o1, solved this perfectly when I tested it.)

How Do LLMs Really Solve Maths?
Apple’s research shows how fragile current state-of-the-art LLMs' reasoning capabilities are.
Another interesting research from 2023 shows that when reasoning tasks are represented by computation graphs, correct predictions are more frequently associated with full computation subgraphs in an LLM’s training data than incorrect ones.
Does this mean that LLMs simply are memorising their training dataset?
The reality is a bit nuanced.
Recent research tells that LLMs use a “bag of heuristics” or simple rules/ patterns to solve maths rather than relying on discrete algorithms or merely memorising training data.
Let’s understand how.
In transformer-based LLMs, a subset of multi-layer perceptrons (MLP) layers or Attention heads that perform computations for a given task is called a Circuit.
When Llama3–8B is studied, many arithmetic-based circuits are discovered in its middle-to-late layers.
It is also seen that mostly MLPs take part in arithmetical operations rather than Attention heads.
Only a few Attention heads (mostly in the early layers) perform calculations, and most heads transfer information about operands and operators between sequence positions.
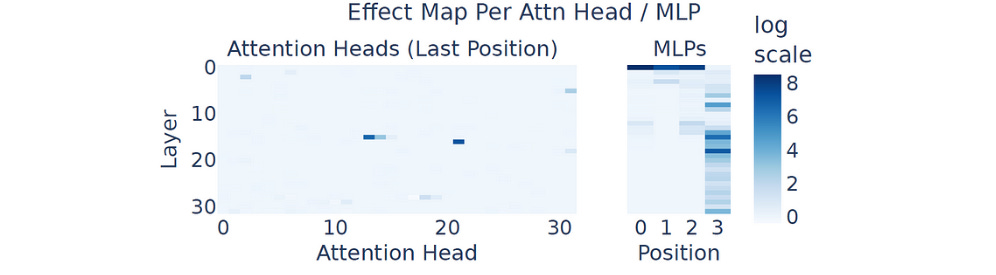
The early MLP layers process operands and operator embeddings, while mid-to-late layers focus on producing the result.

Roughly 1.5% neurons per layer are needed to compute arithmetic prompts in each layer correctly.
These neurons learn sparse, human-identifiable rules or heuristics, and a combination of these enables the model to produce accurate outputs.
Some of these heuristics are as follows:
Range Heuristic: Used when an operand or result falls within a specific numerical range.
Modulo Heuristic: Used when an operand or result has specific properties, for example, being even or divisible by 5.
Pattern Recognition Heuristic: Used to detect patterns in operands or the result, for example, both operands being odd or one being much larger than the other.
Identical Operands Heuristic: Used when both operands are equal.
Direct Result Heuristic: Used in cases where the result is directly memorised from the training data, like knowing that
226 – 68 = 158without further work.Indirect Heuristic: Unlike the Direct Result Heuristic, this heuristic is used in cases where an individual operand has a particular characteristic that helps arrive at the result easily, for example, an operand lying in the range of
[100, 200].
These heuristics emerge early in training and evolve over time, becoming more refined in later checkpoints.

So How Far Are We From Math-Genius AIs?
Popular benchmarks like MATH and GSM8K are flawed in evaluating the mathematical capabilities of LLMs.
First of all, these benchmarks assess LLM competency at the high school and early undergraduate levels.
Next, their popular use in many research papers and projects leads to data contamination.
Therefore, researchers have created a new benchmark called FrontierMath to test the advanced mathematical problem-solving abilities of LLMs.
FrontierMath contains hundreds of exceptionally challenging math problems from different domains that are crafted by expert mathematicians.

These problems are so hard that solving a typical one requires multiple hours of effort from a researcher in the relevant branch of mathematics.
For the harder questions, it takes them multiple days!
Check out some of them.

Are you interested in knowing how well our best LLMs do on them?
None of the models can achieve even a 2% success rate on the full benchmark.

For problems that could be solved by any model at least once (4 problems in total) and conducting repeated trials with five runs per model per problem, only ‘o1-preview’ could solve a question right on all five funs.

Compare this with other benchmarks, which are almost at their saturation point and give us a false impression that LLMs are exceptionally good at math problems.

An LLM really needs to crush the FrontierMath benchmark to brag about its mathematical abilities, and they are nowhere near this.
Our leading LLMs cannot understand and solve mathematics, and whoever is spreading this notion is in the business of scaremongering.
Yes, we might someday, but currently, AGI is a distant dream.
What are your thoughts on this? Let me know in the comment below.
Further Reading

Seems like memory layers are the path to getting LLMs to be good at maths.
Great work, sir. Keep it up.