
‘ReXplain’ Is Transforming Radiology With AI Like Never Before
A deep dive into 'ReXplain', an AI tool that creates personalized video radiology reports to communicate findings to patients effectively


Have you ever dealt with Radiology reports?
They look like large black-and-white sections with occasional bursts of colour unless you're a Radiologist.
I even struggle with some of them, even though I have been practising medicine for the last five years and studying it for the last six before that.
Worry not! It’s time for some exciting news!
A team of researchers has created an AI-driven tool to solve this problem.
In their pre-print published in ArXiv, they describe ‘ReXplain’ or ‘Radiology eXplaination’, a tool which integrates —
LLM for Radiology report simplification
Image segmentation model to identify and highlight different anatomic regions in Radiology images
Avatar generator model that creates human avatars that explain the radiology findings to patients in simple lay language
All of these work together to create a video report that can accurately deliver radiology findings to a patient, simulating an easy-to-understand one-to-one consultation.
This is incredible!
Here’s a story where we deep dive into how ‘ReXplain’ works and how tools like this improve patient care through AI-enabled multi-modal communication like never before.
Let’s go!
How ‘ReXplain’ Works
ReXplain borrows insights from a clinical workflow where radiologists or clinicians walk patients through their CT radiology reports.
It is noted that there are three important steps in this process.
These are:
Explaining essential findings to a patient in plain or lay language
Pointing at abnormalities in the radiology images
Telling the patient about how these images would look if they were from a healthy individual
Next, AI pipelines are created for each of these steps, resulting in a patient-friendly video report.
Let’s learn how this is done at each step.
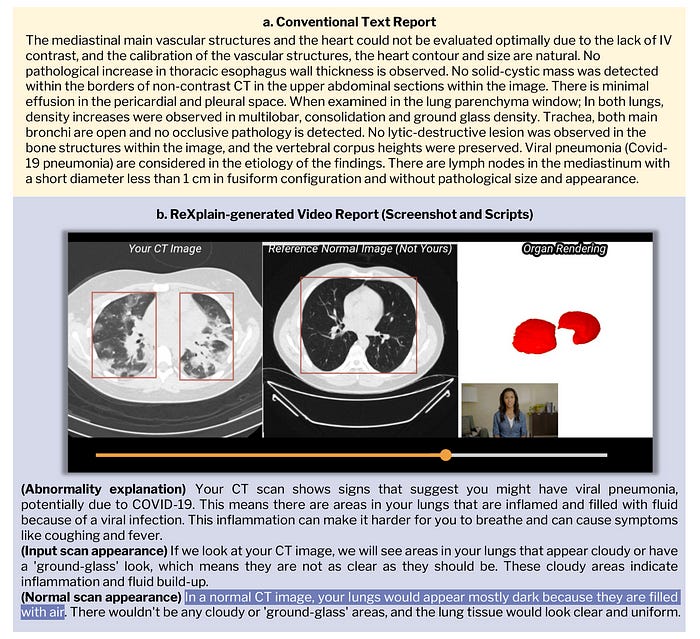
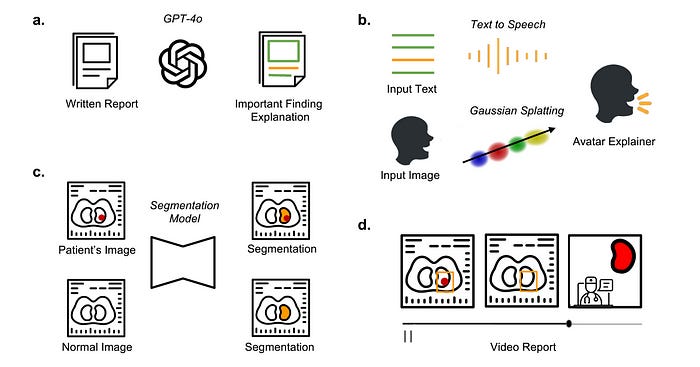
Step 1: Converting Radiology Reports To Lay Language
GPT-4o is used at this step, where it is prompted to extract phrases that describe positive findings from the radiology reports.
After this, GPT-4o generates more information about these phrases, where it —
Explains what these findings are
Describes how these findings appear on a CT scan
Describes how a CT scan would normally appear without these findings
The prompt used in this step is shown below.

Step 2: Connecting Extracted Findings To Radiology Images
In this step, GPT-4o is prompted to match the extracted findings from the previous step to an organ from a set of 201 human organs.
Currently, no AI model can localise specific lesions mentioned in radiology reports, so localization to organs is the best that could be done here.
The following prompt makes this possible.


Next, the Segment Anything in medical images via Text (SAT) model segments the patient’s CT scan using the extracted ‘organ’ tag.
After this segmentation step, PyTorch3D is used to generate 3D renderings of the selected organ.
Step 3: Supplementing With Normal Radiology Images
To make the images easy to understand, their normal counterparts are retrieved from a healthy individual’s scan.
These images are processed using the previous segmentation steps, and then a medical image registration tool called SimpleElastix is used to align the healthy CT scans with the patient's CT scans.
This tool uses Rigid registration, which ensures that the organs' orientation, size, and position in both scans match as closely as possible.
Step 4: Generating Avatar To Explain Reports
A text-to-video pipeline called Tavus is used to create a lifelike, expressive, and engaging virtual explainer that simulates a medical practitioner.
This pipeline uses:
3D head and shoulders reconstruction
Audio to facial animation generation
Avatar video rendering using 3D Gaussian Splatting, a technique that uses a set of Gaussian ellipsoids instead of traditional polygons or meshes to model a scene.
Step 5: Combining Everything To Generate A Video Report
All of the above are combined to create a video report.
This video is structured into three parts.
In the first part, the patient’s radiology image is shown with a bounding box highlighting the area of interest, and the AI avatar introduces the finding.
In the second part, the scan is further scrolled, and the radiology findings are described in detail.
In the third part, the patient’s scan is compared with a normal scan, with bounding boxes highlighting the differences. The AI avatar here describes how a healthy scan should look like.
How Well Does ‘ReXplain’ Perform
For evaluation, non-contrast 3D Chest CT images and radiology text reports were first selected from the publicly available CT-RATE dataset.
These images were used to create 10 video reports lasting up to 3 minutes.
These AI-generated video reports, along with the text-based conventional reports, were given to a team of five experienced radiologists.
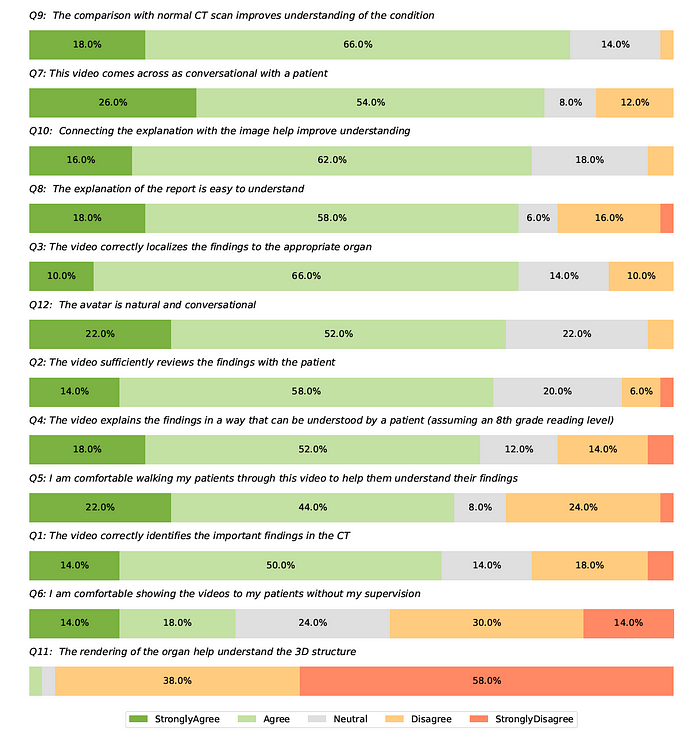
These radiologists were asked to complete a 12-question survey with the option for written feedback, as shown below.

The findings show that ‘ReXplain’ has a major limitation in that it highlights entire organs instead of showing smaller findings like lung nodules.
This is because of current limitations in AI models where they cannot segment each pathological lesion in radiology reports.
However, most other results are very positive.
The findings indicate that most radiologists believe the generated video reports are correct, easy to understand, communicate information effectively to patients, and reduce radiologists’ workloads by automating video report creation.
These findings are a significant step towards democratizing patient-centred healthcare with AI-enhanced tools.
What are your thoughts? Let me know in the comment below.