

‘Skeleton Recall Loss’ Is The New Breakthrough In Segmentation
A deep dive into how conventional Segmentation works and how the ‘Skeleton Recall Loss’ sets itself as the new state-of-the-art in Thin-structure Segmentation


Precise segmentation is a critical requirement across many domains today.
These include training self-driving cars, medical image recognition systems, and monitoring using satellite imagery, to name a few.
Further precision is needed in many other fields where the objects of interest are minuscule but critical, such as studying blood vessel flow, surgical planning, detecting cracks in architectural structures, or optimizing route planning.
A lot of work has been previously done to address such challenging segmentation.
This includes mathematical techniques like:
Furthermore, advancements in deep learning neural networks such as U-Nets and their variations have greatly enhanced segmentation accuracy.
“What’s the issue then?”— you’d ask.
All of these methods poorly segment tiny, elongated and curvilinear structures.
And the loss function involved might be one to blame.
Even when these deep-learning networks use state-of-the-art losses such as centerline-Dice or cl-Dice, their computational cost is extremely large, so much so that they fail miserably on large volumes and Multi-class segmentation problems even on modern GPUs.
But not anymore. A new loss is finally here in the open-source fair!
It demonstrates an overall superior performance to current state-of-the-art losses on five public datasets for Topology-preserving Segmentation.
The best part is that by replacing the intensive GPU-based calculations that conventional state-of-the-art segmentation losses involve with cheap CPU-based operations, it achieves a computational overhead reduction of more than 90%!
Due to this, for the first time, this novel loss, called Skeleton Recall Loss, allows multi-class thin structure segmentation with unparalleled accuracy and computational efficiency.
The findings of this research have been published in ArXiv, and the code has been open-sourced on GitHub.
Here is a story where we explore how conventional segmentation works, why the previous loss functions that it involved were inefficient, and how the new Skeleton Recall Loss sets itself as the new state-of-the-art for this process.
Let’s dive in!
But First, How Does Segmentation Work?
Segmentation is the process of dividing a digital image into simpler regions that are more meaningful and easier to analyze.
U-Nets, a type of Convolutional Neural Network (CNN) architecture published in 2015, completely revolutionized this process by being fast, highly accurate, generally adaptable, and efficiently trainable deep neural networks.
This architecture consists of:
a contracting path (Encoder) — that downsamples and captures the features of the input images
a symmetrical expanding path (Decoder) — that reconstructs the downsampled images from the features learned during the contracting phase
A key feature of the U-Net architecture is Skip connections between the Encoder and Decoder sub-networks that improve gradient flow during training and help preserve spatial information well.

U-Nets conventionally use loss functions such as:
Cross-entropy loss — measures the difference between predicted probabilities and true class labels, penalizing inaccurate predictions
Dice Coefficient loss — measures the overlap between predicted and true segments, penalizing dissimilarity
A modification of Dice called centerline-Dice (cl-Dice) is specifically used to train Topology-preserving Segmentation networks for thin structures and is considered state-of-the-art.
Let’s talk about Dice and cl-Dice next.
What Is Dice?
The Dice similarity coefficient measures the similarity between two sets.
In terms of image segmentation, it measures the overlap between the predicted and ground-truth segmentation.
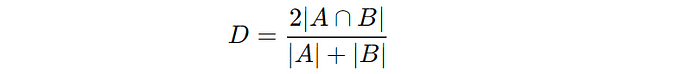
For this metric, a value of 1 indicates perfect overlap, and a value of 0 indicates no overlap.
For it to function as a loss function that decreases as the model improves, a differential version of the Dice loss called ‘Soft Dice loss’ is defined as follows —
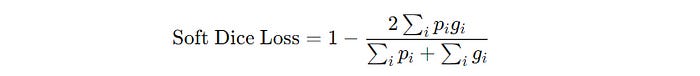
cl-Dice was introduced to improve the accuracy of segmentation further.
Let’s discuss it next.
What Is cl-Dice?
Centerline-Dice (cl-Dice) is a metric that combines the traditional Dice coefficient loss with the skeleton or centerline of the segmented structure.
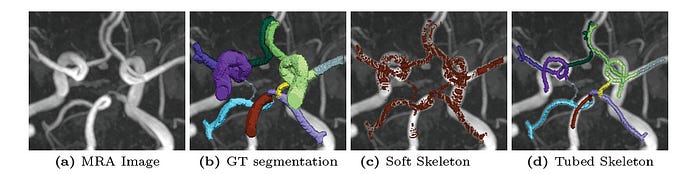
In this context, the term ‘skeleton’ refers to a one-pixel-wide line representing the central path or connectivity of the tubular structure.
Since the original mathematical skeletonization approach is non-differentiable, an approximate skeletonization approach called ‘Soft skeletonization’ is used.
This approach is differentiable (using min and max-pooling operators along with ReLU iteratively ), which is essential for neural network training.
This loss is hence called the Soft cl-Dice loss function.
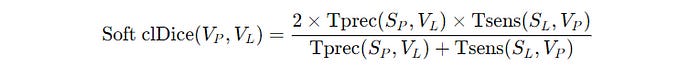
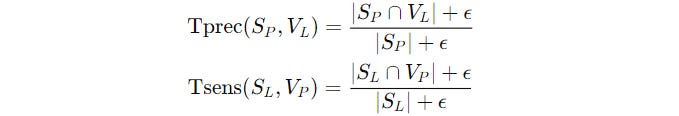
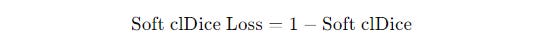
The Problems With cl-Dice
The differentiable soft skeletons used in the cl-Dice loss can often be jagged and perforated, leading to segmentation inaccuracies.
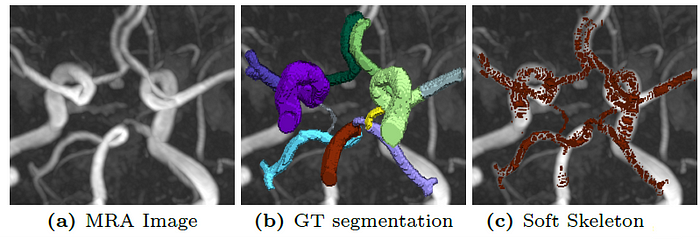
In addition, the calculations in the cl-Dice loss involve intensive GPU-based operations, which makes it unsuitable for large 3D datasets and multi-class segmentation problems.
Efforts have been made to improve the approximate soft skeletonization algorithm utilized in cl-Dice.
The Topo-clDice Loss is one such method that generates more accurate differentiable skeletons. However, it demands even higher computational resources.
These inaccuracies are adequately addressed by researchers who developed the Skeleton Recall loss.
Let’s move forward to learning about it.
Skeleton Recall Loss To The Rescue
The Skeleton Recall Loss is designed to preserve the connectivity in thin tubular structures during segmentation while simultaneously reducing the computational overhead associated with this process.
This loss applies to any deep learning segmentation network regardless of whether the inputs are 2D or 3D.
The insight that gives rise to this computationally efficient loss is as follows:
“The usage of a skeleton for the preservation of connectivity is an effective method, but it does not need to be differentiable.”
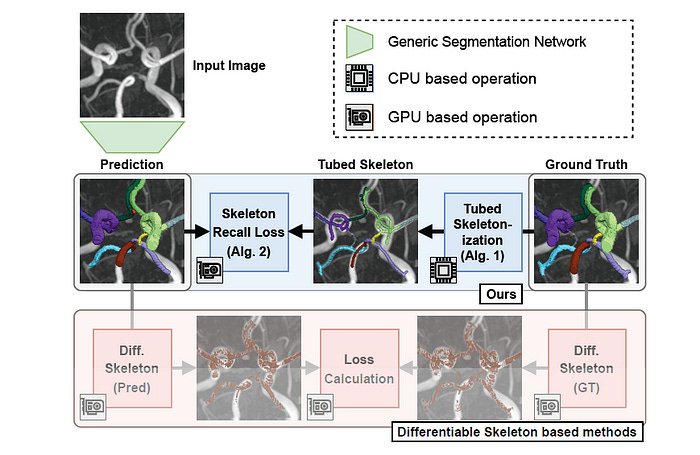
Following this insight, a Tubed skeletonization approach is performed on the ground truth instead of the GPU-based soft-skeletonization.
This is how it works:
Binarization: The ground truth segmentation mask (
Y) is converted into a binary form (Y_{bin}), where the foreground and background are labelled distinctly.Skeleton Extraction: The skeleton of the binarized mask is computed using the previous approaches for 2D and 3D inputs.
Dilation: The binarized skeleton is dilated using a diamond kernel of radius 2 to make it tubular. This increases the effective area and stabilises loss computation by including more pixels around the skeleton.
Multi-class Assignment: For multi-class segmentation problems, the tubular skeleton is multiplied by the original ground truth mask (
Y) to assign different parts of the skeleton to their respective classes.
The pseudo-code for the Tubed Skeletonization approach is shown below.
Require: Y are K-classed hard targets where Y_{i,j,(,k)} ∈ [0, K]
1: Y_{bin} ← Y > 0 % Binarize to foreground and background labels
2: Y_{skel} ← skeletonize(Y_{bin}) % Extract binarized skeleton
3: Y_{skel} ← dilate(Y_{skel}) % Dilate to create tubed skeleton
4: Y_{mc-skel} ← Y_{skel} × Y % De-binarize to create multi-class tubed skeleton
5: return Y_{mc-skel}Note that all of the above operations are computationally cheap and can be performed on a CPU during data loading.
These can even be pre-computed using libraries like scikit-image.
After Tubed Skeletonization, a ‘soft’ (differentiable) Recall Loss function is used that incentivises a neural network to predict segments that include as much of the tubular skeleton as possible.
This is called the Skeleton Recall Loss.
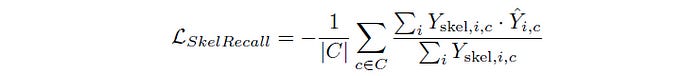
The visual below demonstrates how the Skeleton Recall loss differs from the previous state-of-the-art losses.
Performance Of The Skeleton Recall Loss
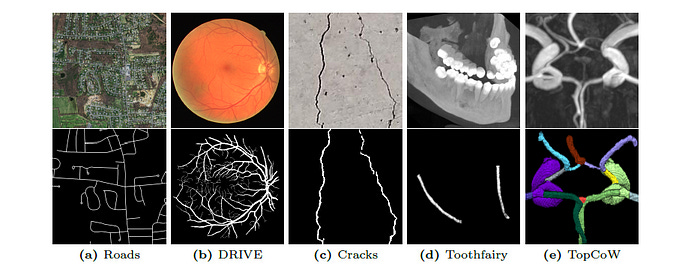
The Skeleton Recall Loss is evaluated on five public datasets that feature thin structures from different domains, including both binary and multi-class segmentation problems in 2D and 3D contexts.
These datasets are as follows —
Roads: Contains 2D aerial images of roads with binary labels
DRIVE: Contains 2D images of retinal blood vessels with binary labels
Cracks: Contains 2D images of cracks on concrete structures with binary labels
ToothFairy: Contains 3D Cone-beam CT images with the Inferior alveolar canal as the target structure, with binary labels
TopCoW: Contains 3D CTA and MRA images of 13 different types of vessels in the Circle of Willis vessels in the brain
The evaluation metrics used are as follows —
For measuring overlap: Dice similarity coefficient
For measuring connectivity: cl-Dice
For measuring topological accuracy: absolute Betti Number Errors of
0th and1st Betti Numbers (β0andβ1) calculated on whole volumes
Two baseline state-of-the-art loss functions are used to benchmark the novel loss —
All the losses are used with two powerful segmentation networks as follows —
Medication image segmentation network nnUNet
Natural image segmentation network HRNet that is pre-trained on the ImageNet dataset
A New State-of-the-art In Segmentation
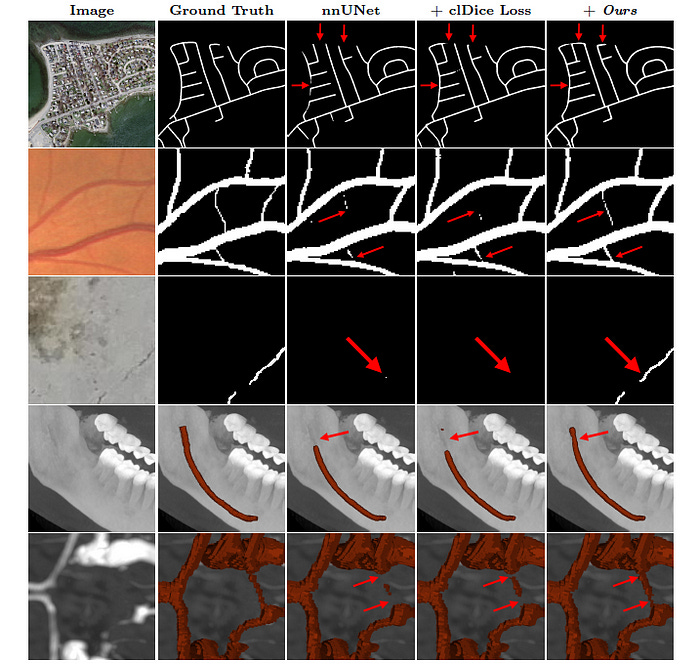
Skeleton Recall Loss consistently outperforms clDice and Topo-clDice Loss across multiple datasets by improving Dice, clDice, and Betti number metrics on both nnUNet and HRNet, demonstrating that it is architecture agnostic.
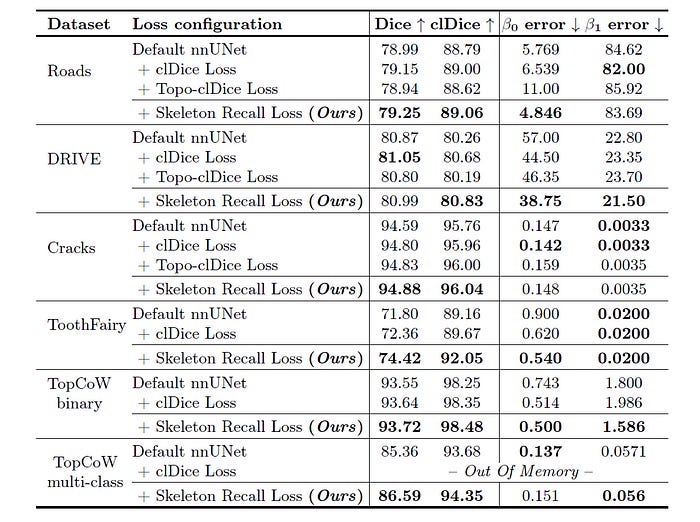
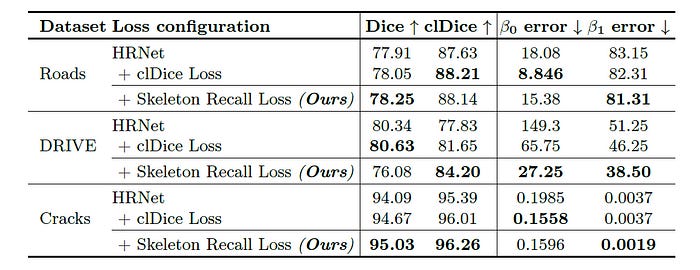
Results Showing Connectivity Conservation
Skeleton Recall Loss shows improved preservation of topology and enhanced connectivity for image segmentation across most datasets.
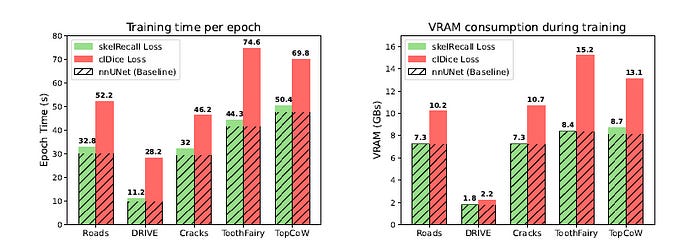
Results Showing Resource Utilization
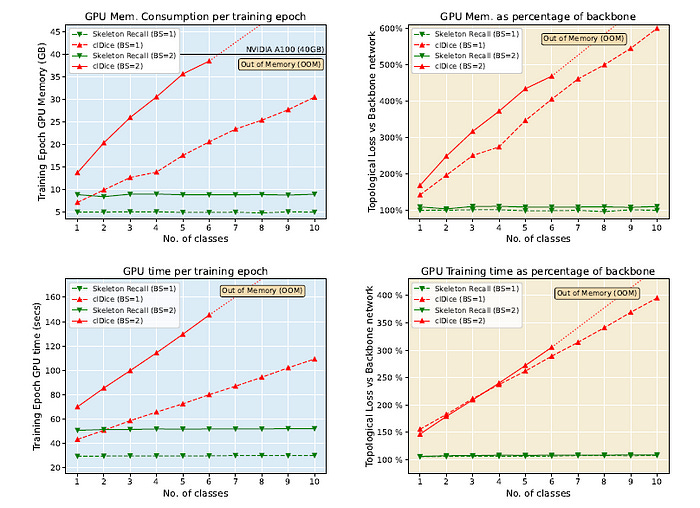
Skeleton Recall Loss minimally increases VRAM usage (2%) and training time (8%) as compared to cl-Dice Loss over the plain nnUNet backbone.
Skeleton Recall Loss excels in multi-class segmentation and outperforms clDice Loss, which becomes infeasible due to high memory usage (note the Out-of-Memory error shown below) and training time as the number of classes increases.
Overall, the Skeleton loss is a new state-of-the-art in segmentation.
It is memory-efficient, minimizes training time, seamlessly integrates into various architectures for 2D and 3D segmentation, and supports multi-class labels without significant computational overhead.
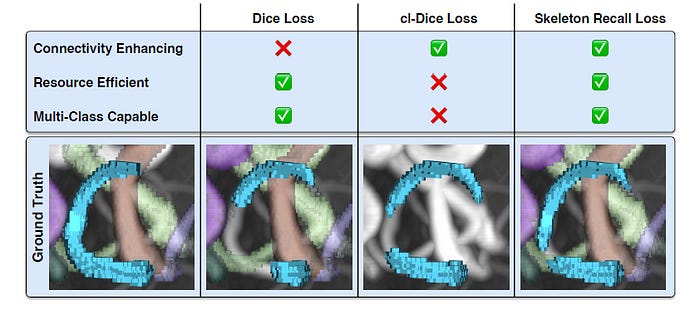
These findings are incredibly significant, and I believe they will greatly speed up the use of artificial intelligence in medical imaging and other critical domains like never before.
What are your thoughts on this? Let me know the comment below.