

LLMs Can Now Self-Evolve At Test Time Using Reinforcement Learning
A deep dive into Test-Time Reinforcement Learning (TTRL), a technique that allows LLMs to learn from test-time data using RL without ground-truth labels.


Large Reasoning Models (LRMs) are trained on vast amounts of long CoT reasoning data, and take a longer time at Inference to reason better.
But what if an LLM could be trained to reason better during Test/ Inference-time itself?
Researchers from Tsinghua University and Shanghai AI Lab have now made this a reality.
They have just introduced a new technique called Test-Time Reinforcement Learning (TTRL) in their recent research paper.
This technique enables LLMs to improve themselves during Inference using unlabelled test data, through Reinforcement learning (RL).
TTRL is highly effective in improving the performance of LLMs on multiple tasks.
Experiments show that it is so good that it boosts the pass@1 accuracy of Qwen-2.5-Math-7B by 211% on AIME 2024!
Alongside this, TTRL-trained LLMs nearly match the performance of those trained directly on test data with ground-truth labels using RL.
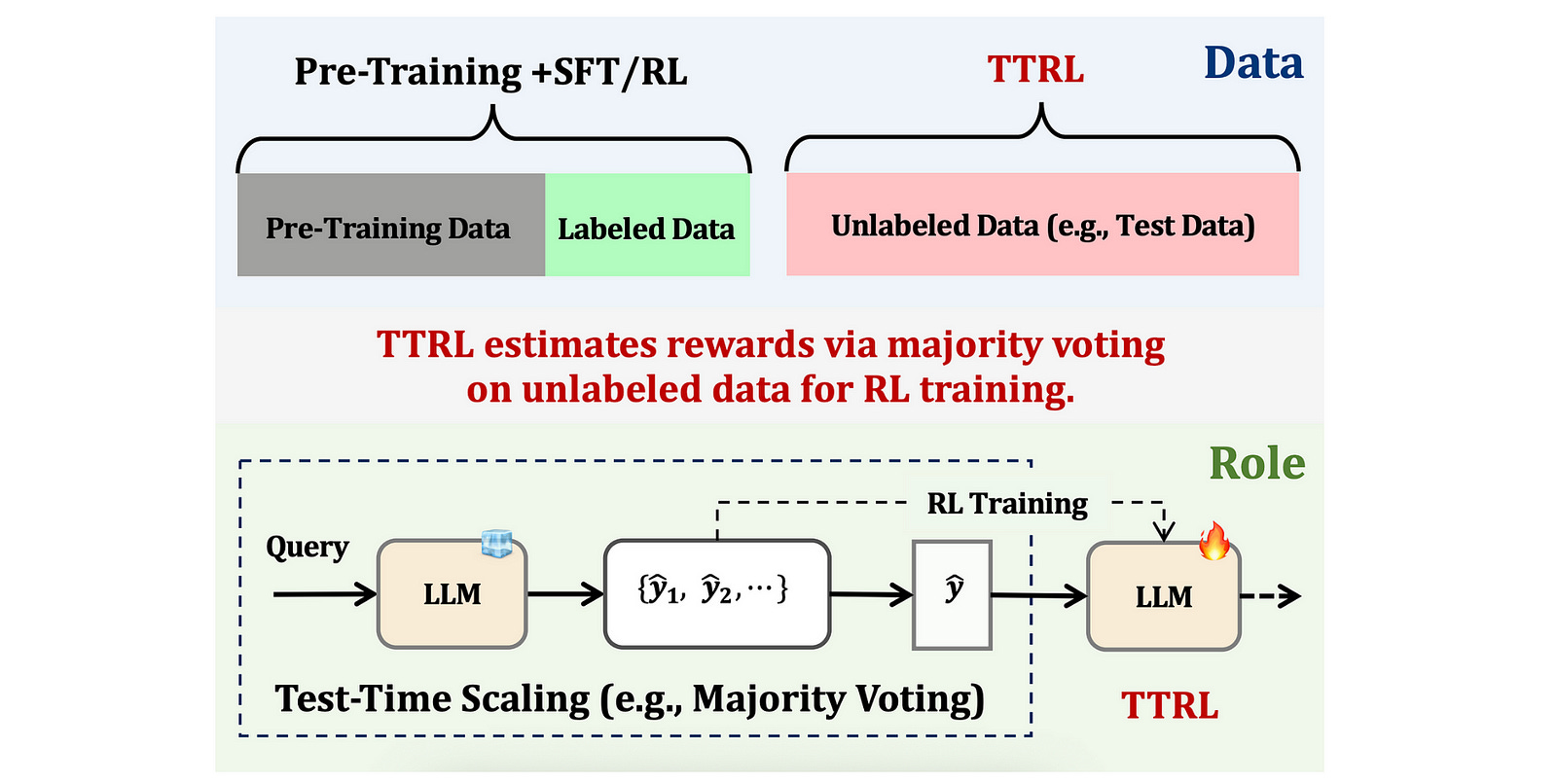
Here is a story that takes a deep dive into Test-Time Reinforcement Learning (TTRL), exploring how it works and how effective it is in improving the performance of LLMs and LRMs.
Let’s begin!
My latest book, called “LLMs In 100 Images”, is now out!
It is a collection of 100 easy-to-follow visuals that describe the most important concepts you need to master LLMs today.
Grab your copy today at a special early bird discount using this link.

Let’s Start With LRMs
LRMs or Large Reasoning Models are LLMs that are trained specifically for using reasoning to solve complex problems.

These models are trained on human-annotated data to reason better (using SFT/ RL), which gives them the ability to use long Chain-of-Thought (CoT) reasoning at inference time.
This enables them to perform remarkably well on challenging problems, such as in the benchmarks Humanity’s Last Exam and ARC-AGI.
However, as these benchmarks are updated with newer and more complex problems, the performance of LRMs declines as they struggle to solve these increasingly challenging questions.
Check out the plot below, which shows how OpenAI’s o3 achieves 60.8% accuracy on ARC-AGI-1 as compared to just 6.5% on the updated ARC-AGI-2.
A similar accuracy drop is seen for OpenAI’s o4-mini.
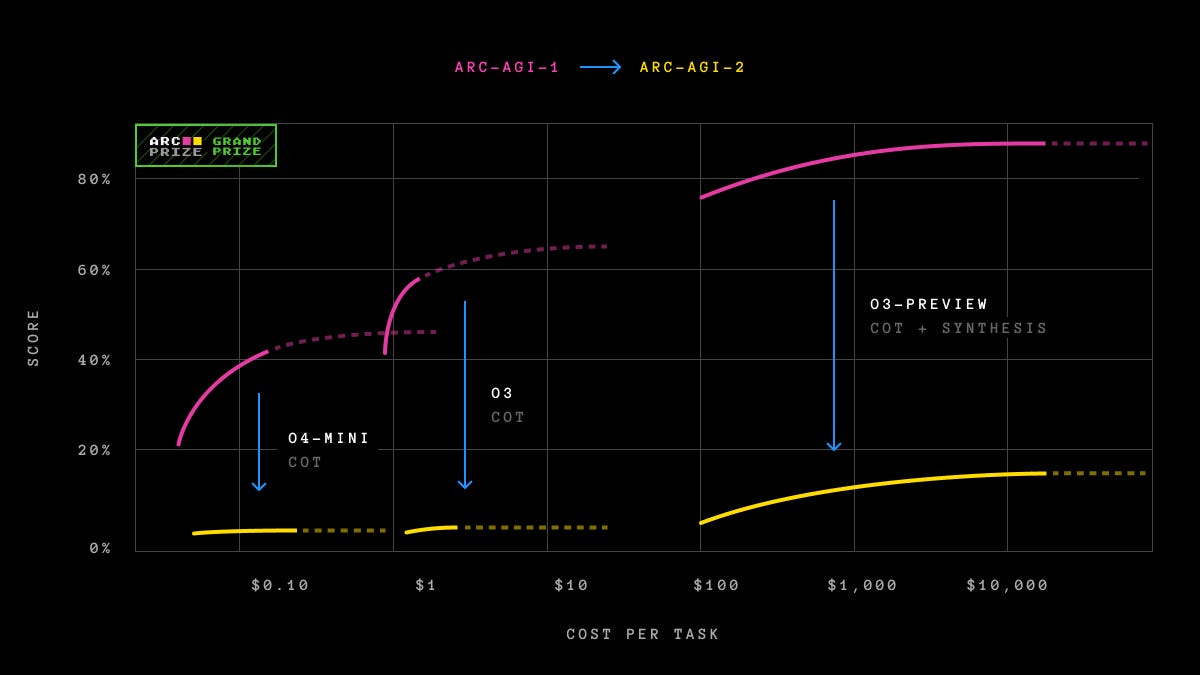
{kind=link}
What if there were a way for LLMs/LRMs to adapt to test/inference-time data to understand it better before solving it?
A method for achieving this adaptation has been studied in previous research, and it is known as Test-Time Training (TTT).
Let’s discuss it next.
Training At Test Time? Yes!
Traditional LLMs, once trained, keep their parameters frozen when evaluated on test data.
Test-time Training (TTT) is different from this.
It involves adapting an LLM’s parameters at test time based on the structure and distributional properties of the test data.
This is achieved using self-supervised learning on examples synthesised from the test data and fine-tuning lightweight LoRA adapters.
This enables the LLM to handle distribution shifts, out-of-domain examples, and few-shot scenarios well.
A previous research titled ‘The Surprising Effectiveness of Test-Time Training for Few-Shot Learning’ tells how effective TTT is when it comes to training LLMs to solve tough problems from the ARC and BIG-Bench Hard (BBH) benchmarks.
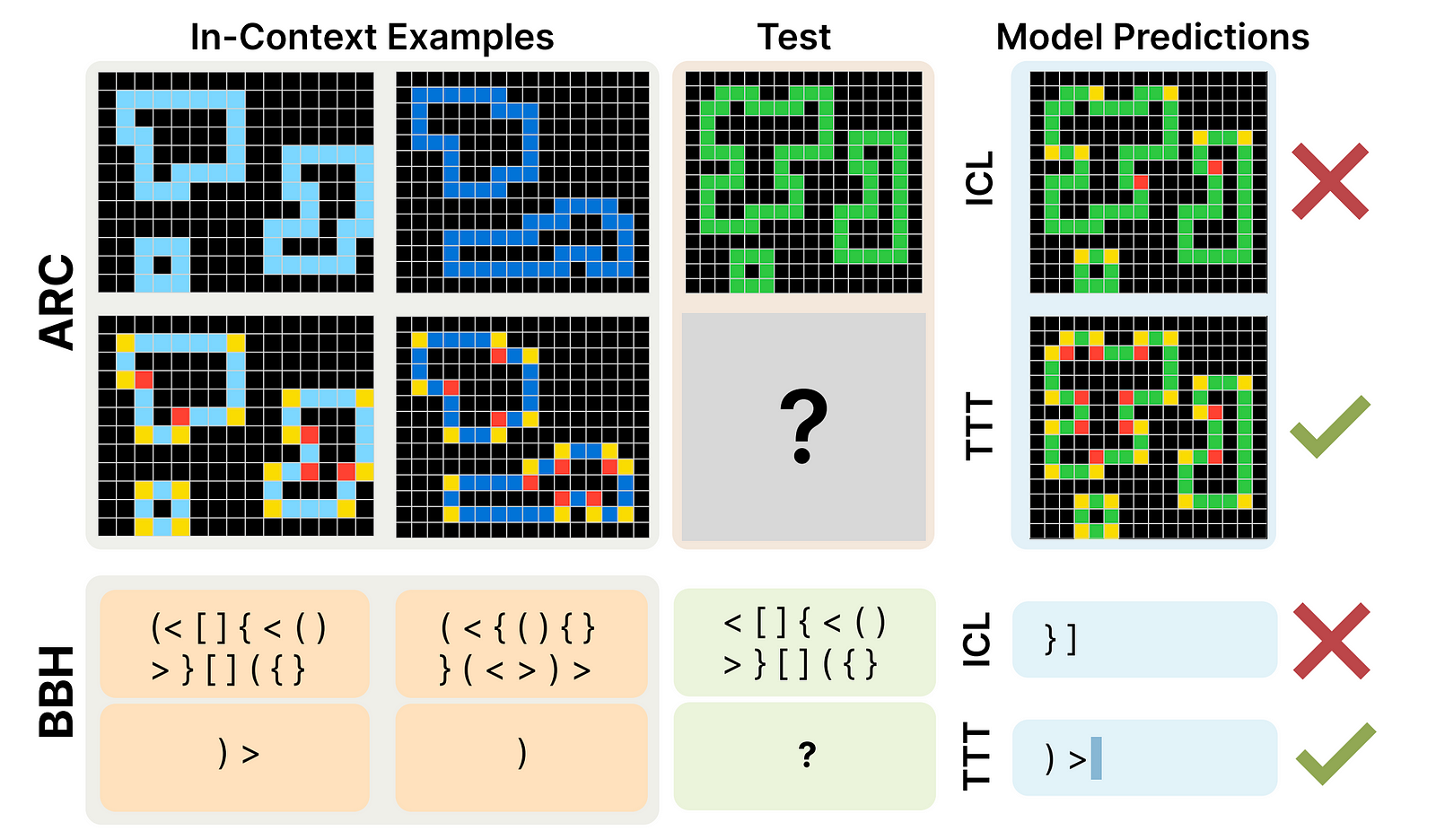
TTT, as described in this research paper, boosts the performance of fine-tuned 8B Llama 3 on ARC by 27.5% and increases its accuracy on BIG-Bench Hard (BBH) by 7.3%.
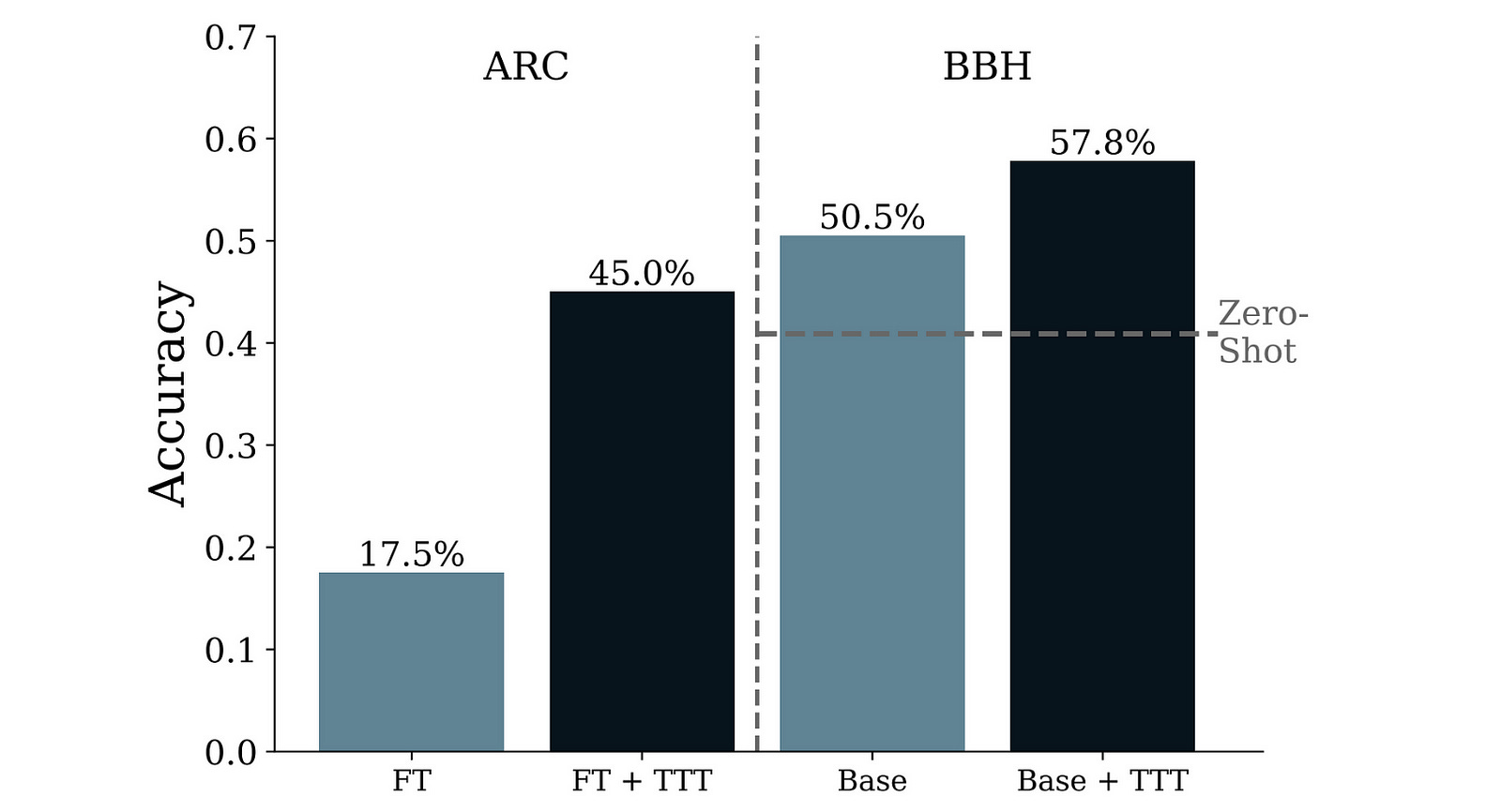
How about we extend TTT and make its gains more permanent?
Here Comes Test-Time Reinforcement Learning
Training data is labelled or verifiable. This provides the ground truth (for supervised learning) and reward signals (for RL) during LLM training.
Test time data, on the other hand, is unlabelled and largely unverifiable (except for programming/ mathematical tasks).
Test-Time Reinforcement Learning (TTRL) gives a solution to this problem of training a pre-trained LLM during test time using RL without ground-truth labels.
Let’s understand how it works.
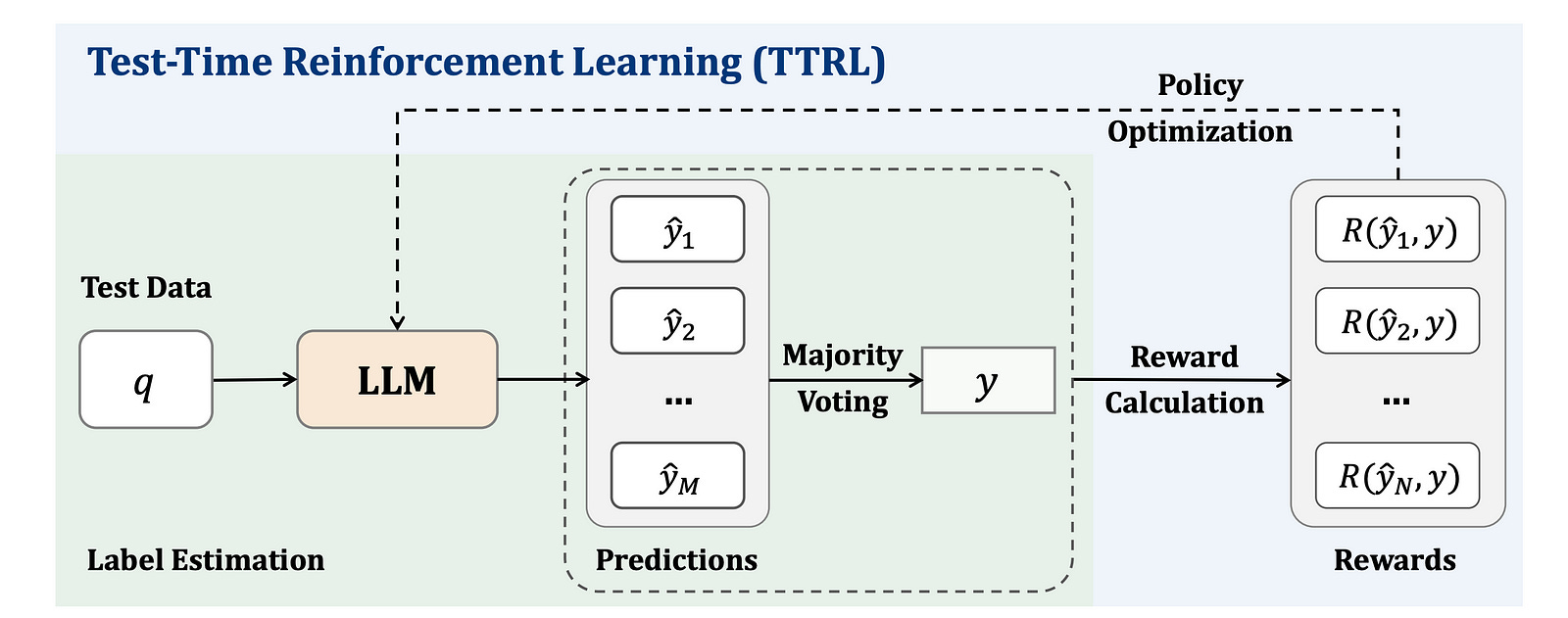
Given a prompt or test-time input x (called ‘State’ in RL terms), an LLM π (called ‘Policy’ in RL terms) with parameters θ produces an output y (called ‘Action’ in RL terms).
The secret sauce of TTRL lies in producing a reward signal without ground-truth labels.
For this, the LLM first produces multiple candidate outputs y(1), y(2), …, y(N) for a given prompt.
It then selects a consensus output y* given these candidate outputs. This acts as a pseudo-label or a proxy for the optimal output/action.
This selection is done using a scoring function as follows:
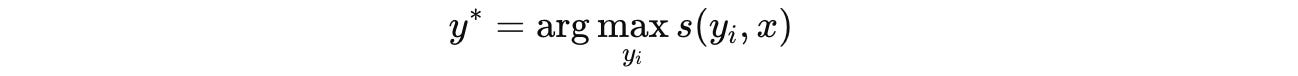
The scoring function can be implemented using different techniques such as:
Majority Voting: which involves selecting the most frequent output among the candidates
Best-of-N: which uses a reward model to score each candidate and selects the highest-scoring one
Weighted Best-of-N: which involves combining each candidate’s frequency (from majority voting) and quality score (from a reward model) using a weighted sum to select the best candidate
A reward is then calculated based on how well an output/ action y aligns with the consensus output/ action y*.
This is done using a reward function r(y, y*) that returns a reward of 1 if the model’s output y matches the consensus output y*, and 0 otherwise.
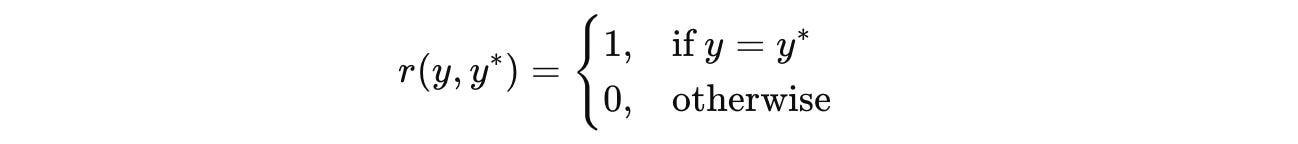

Finally, the LLM is trained to maximize the expected reward, shown in the following equation:
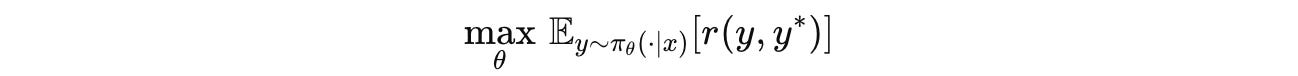
This is done by updating the LLM parameters (Policy optimization with GRPO) using Gradient ascent:
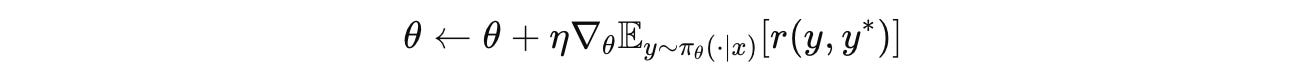
The following illustration shows the complete TTRL process.
Does TTRL Really Work Well?
Based on the above methodology, researchers implement TTRL on multiple LLMs as follows:
LLMs from Qwen family
LLMs from LLaMa family
LLMs from DeepSeek family
LLMs from Mistral family
These LLMs are then evaluated before and after applying TTRL on:
GPQA-Diamond: a set of 198 extremely difficult, expert-validated MCQs in biology, chemistry, and physics
3 mathematical reasoning benchmarks, namely, AIME 2024, AMC, and MATH-500
The primary metric to evaluate the LLMs on each benchmark is pass@1 accuracy, which tests whether the LLM’s top response matches the correct answer.

Here is what the results tell!
TTRL Consistently Improves All LLMs On Most Tasks
TTRL improves the performance of all LLMs across the four highly challenging benchmarks.
On the AIME 2024, TTRL achieves at least a 105% improvement across all LLMs.
Notably, applying it to the Qwen2.5-Math, a 1.5B LLM makes it gain a 40.3% accuracy on the MATH-500 benchmark!
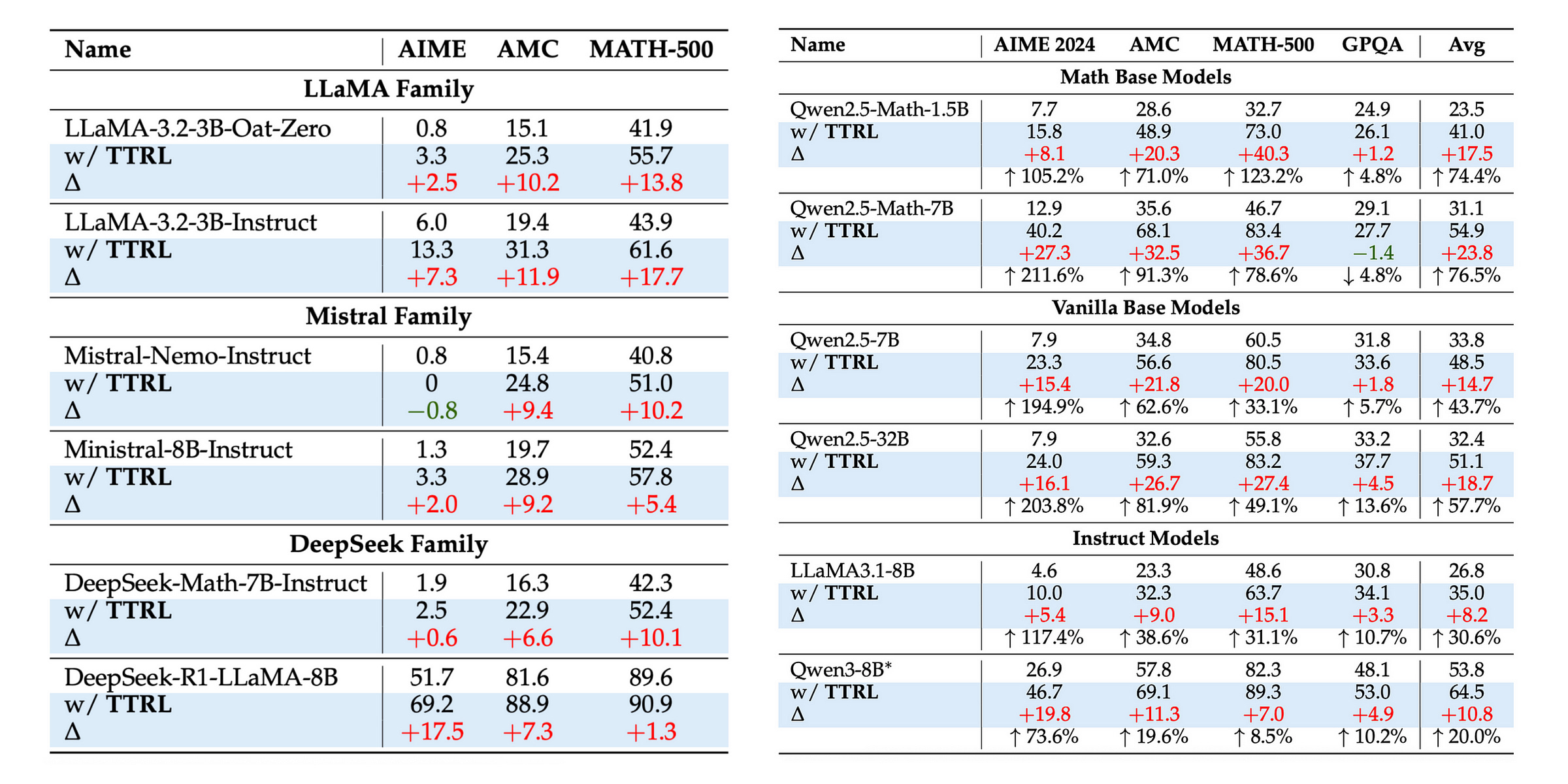
Alongside these, despite being trained on unlabelled data using self-generated rewards, TTRL’s performance matches or exceeds that of other models, RL-trained on fully labelled datasets.
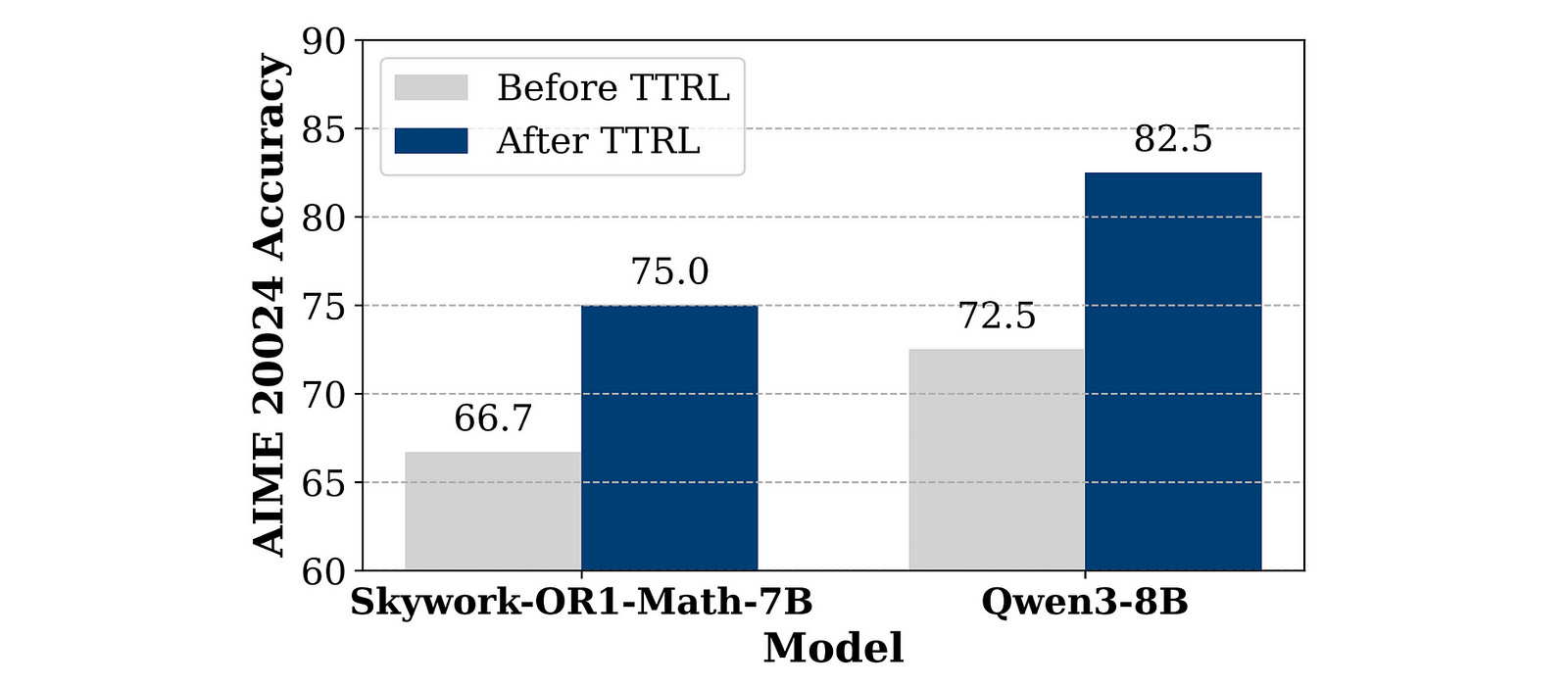
TTRL Even Boosts The Performance Of Strong LRMs
LRMs that have been extensively trained on massive reasoning datasets still get significantly better, and a jump of around 10% accuracy is seen in their performance after TTRL.
TTRL Works Better As Models Get Bigger
As the model parameters increase, their performance consistently improves after TTRL.
This is because larger models are better at generating accurate answers when using majority voting, which helps them learn more effectively from their own outputs using TTRL.
Performance Gains After TTRL Aren’t Merely Task Specific Or RL Algorithm Specific
TTRL doesn’t just improve LLM performance on the specific task it was trained on, but also helps on other tasks (out-of-distribution) it wasn’t trained for.
As shown in the image below, Qwen2.5-Math-7B demonstrates generalizable gains when trained with TTRL on one benchmark and then evaluated on others.
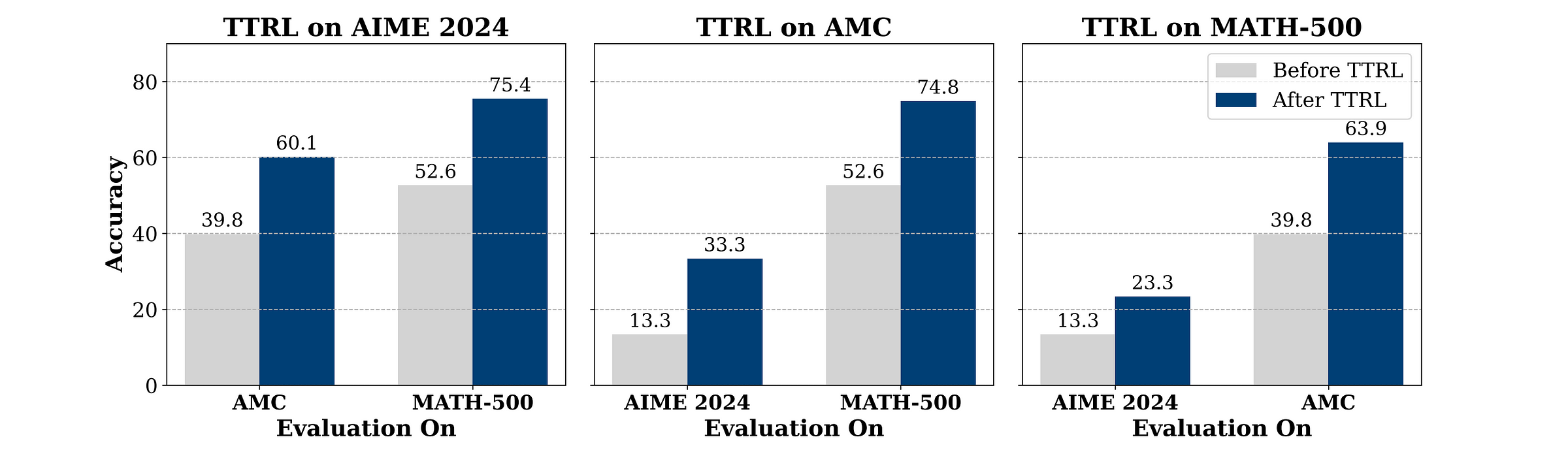
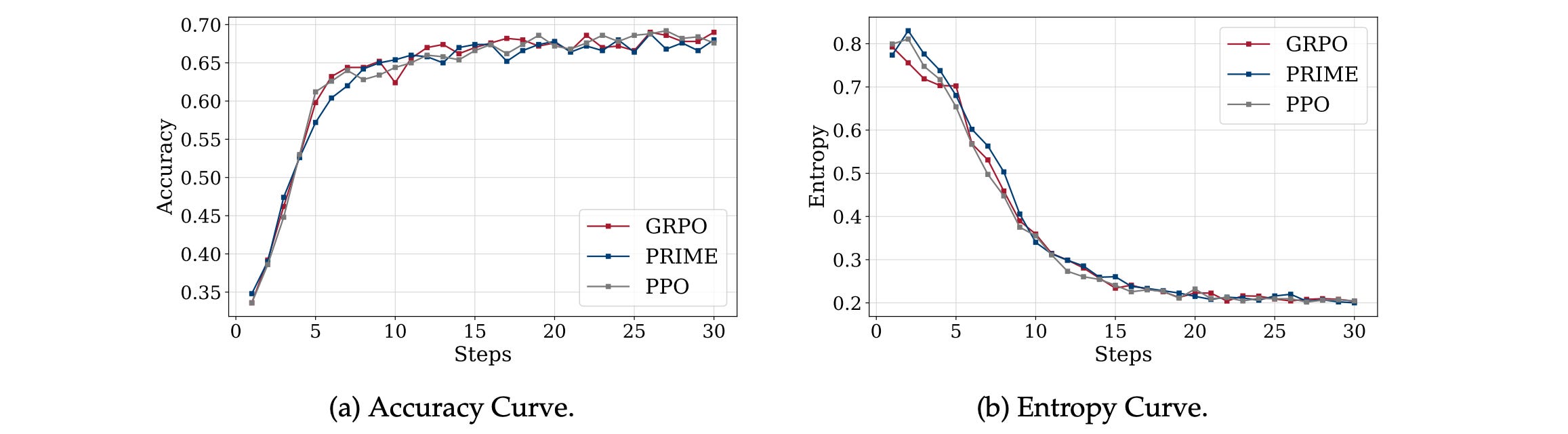
Similarly, TTRL applied using three different RL algorithms (GRPO, PPO, and PRIME) leads to similar accuracy gains/ entropy drops on MATH-500, indicating that it is algorithm-agnostic.
What Does This Mean For The Future Of LLMs
Labelled data is expensive and requires a significant amount of time and human effort to assemble.
With more unlabelled data available than labelled data, TTRL represents a massive leap in training LLMs, enabling them to self-evolve with experience rather than relying on human supervision.
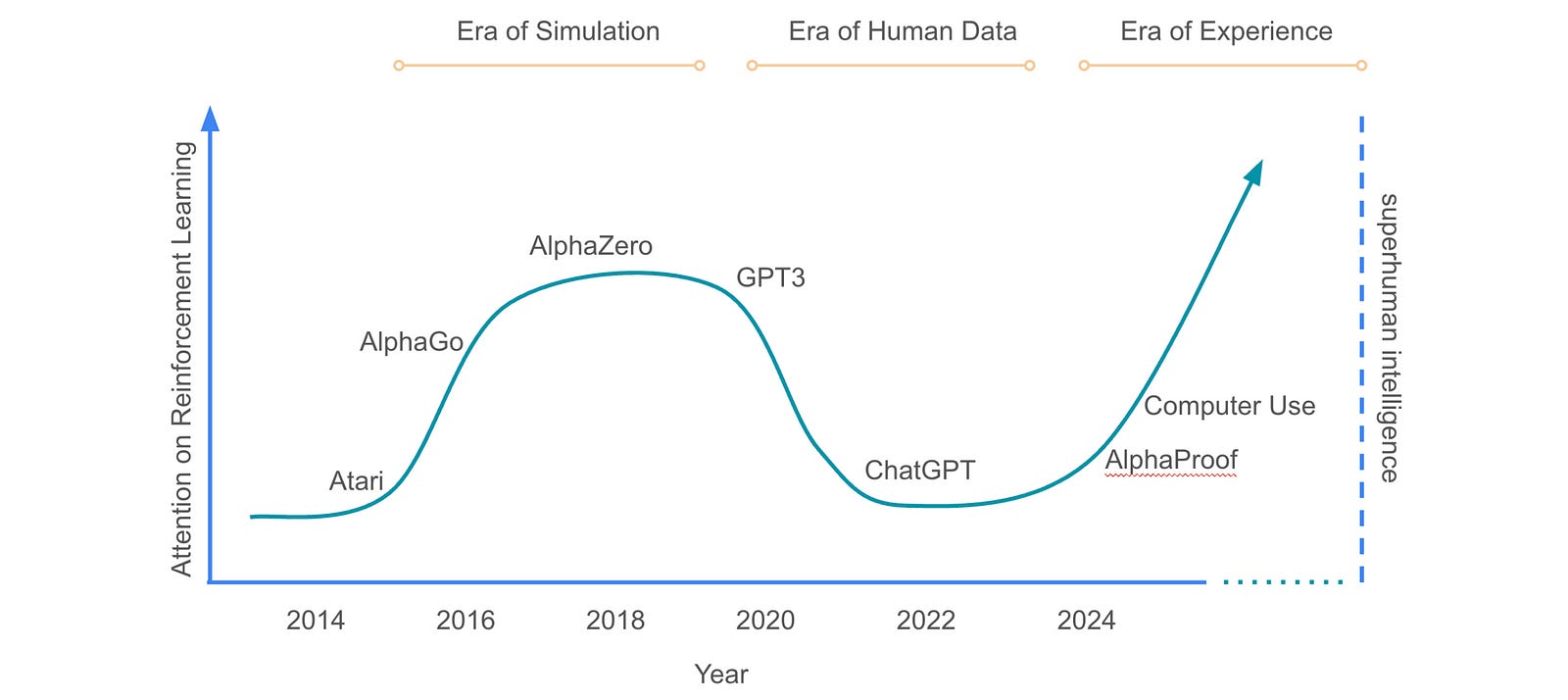
We are rapidly transitioning towards the “Era of Experience”, and techniques like TTRL are helping us do this and step up towards superhuman intelligence.
What are your thoughts on this? Please share them with me in the comments below.
Further Reading
Research paper titled ‘TTRL: Test-Time Reinforcement Learning’ published in ArXiv
Github repository associated with the original TTRL research paper
Source Of Images
All images used in the article are created by the author or obtained from the original research paper unless stated otherwise.
