
The Open Source "Agentic Reasoning" Beats Google Gemini Deep Research
A deep dive into how the "Agentic Reasoning" framework works and the techniques behind it that make it outperform the most advanced reasoning LLMs today.


Deep Research is getting popular.
With Google releasing an LLM agent that can impressively complete complex multi-step research tasks, this trend was soon followed by OpenAI and then Perplexity.
Now, there’s another exciting update, which surprisingly is open-source.
A team of researchers from the University of Oxford has just put out a framework called Agentic Reasoning that uses external tool-using LLM agents to solve multi-step logical problems that require deep research.
The results of this framework are surprisingly good, so much so that it outperforms leading RAG systems and closed source LLMs on PhD-level scientific reasoning (GPQA) and domain-specific deep research tasks.
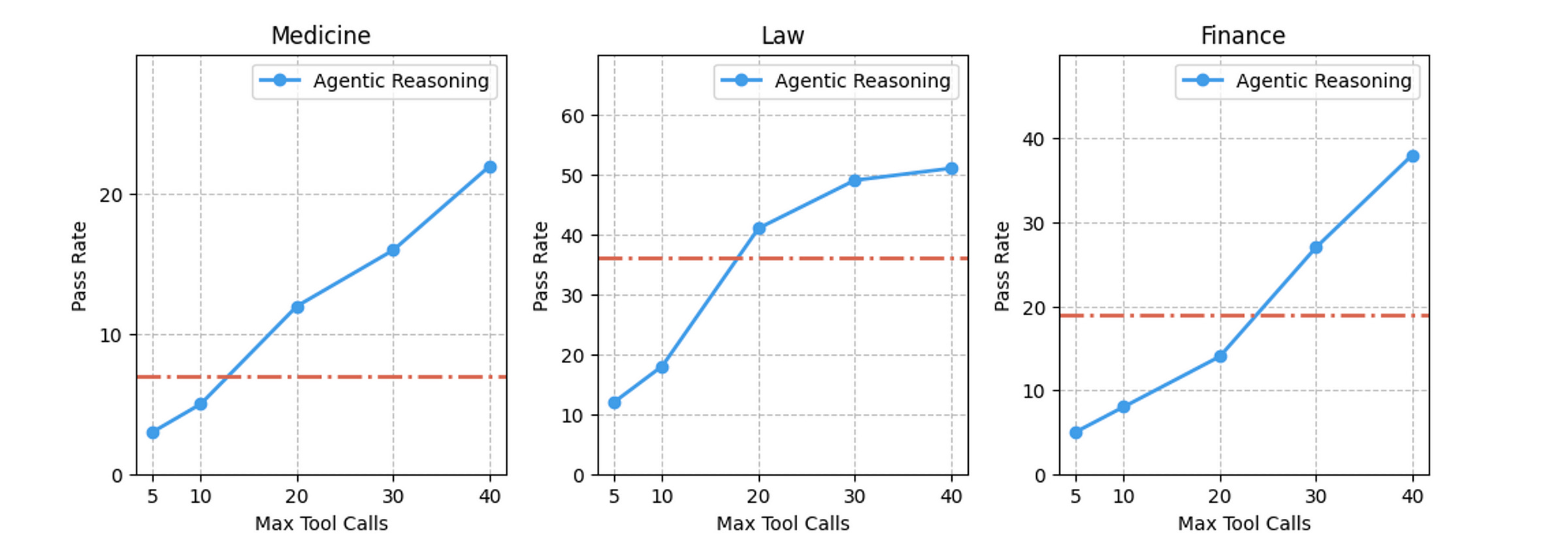
The framework even beats Google Gemini Deep Research across multiple open-ended Q&A tasks in finance, medicine and law!
Here’s a story where we deep dive into how this framework works and the techniques behind it that lead to such impressive results.
Let’s begin!
The “Brain” Behind Agentic Reasoning
Reasoning LLMs like OpenAI o1 and DeepSeek R1 have been trained on large-scale chain-of-thought reasoning data using Reinforcement learning.
While these models perform well on maths and coding problems (where the solutions are easily verifiable), many fields like Ethics and Social sciences might still be unconquered due to the complex and abstract social and moral reasoning involved.
Can the human approach of reasoning through information gathering (using the internet), quantitative analysis (with computing tools) and organising thoughts (on whiteboards) inspire us?
Seems like the answer is — Yes!
And this is what leads to the creation of “Agentic Reasoning”.
While a conventional agent directly uses external tools to gather data and perform computations, the Agentic Reasoning framework uses external LLM-based agents as tools.
Three agents are essentially used in this framework —
Web-search agent: Gets information from the internet
Coding agent: Helps perform computations using Python code
“Mind Map” or Memory agent: Constructs knowledge-graph based on reasoning context
A reasoning LLM supervises and instructs these agents, gathers their outputs and uses these to reason, leading to the final answer.
Let’s mathematically formulate the framework.
Given a multi-step reasoning query (q), the goal is to generate:
a logical reasoning chain (
r)a final answer (
a)
For this, a reasoning LLM with given task instructions (o) interacts with external agents used as tools to obtain valuable outputs (e) along with an agent that holds the reasoning memory (k).
The goal can be summarised as follows —
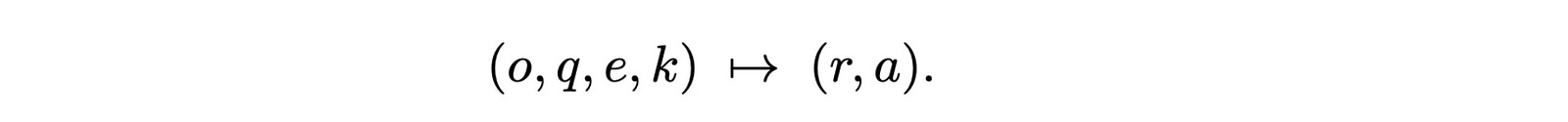
The probability that the reasoning LLM will generate the reasoning chain r and the final answer a given the inputs (o, q, e, k) is given by —
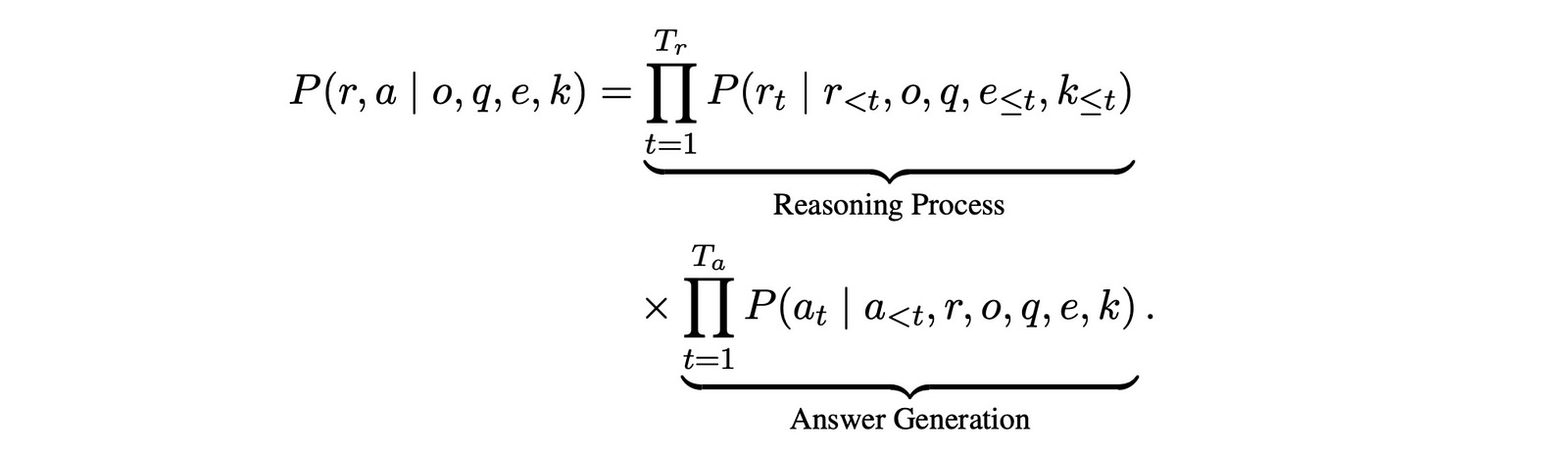
The reasoning LLM starts with the task instructions (o) and the query (q) and decides in real time if it needs any more external information.
It uses specialized tokens during reasoning to request the help of external LLM agents.
These tokens are:
Web search tokens
Coding tokens
Mind-map calling tokens
When any of these tokens is detected, the model pauses reasoning and generates a specific query along with the reasoning context as a message to the appropriate agent LLM.
The appropriate agent LLM processes this request, and this response is integrated into the reasoning chain.
This process takes place iteratively till the reasoning model reaches a fully reasoned final answer.
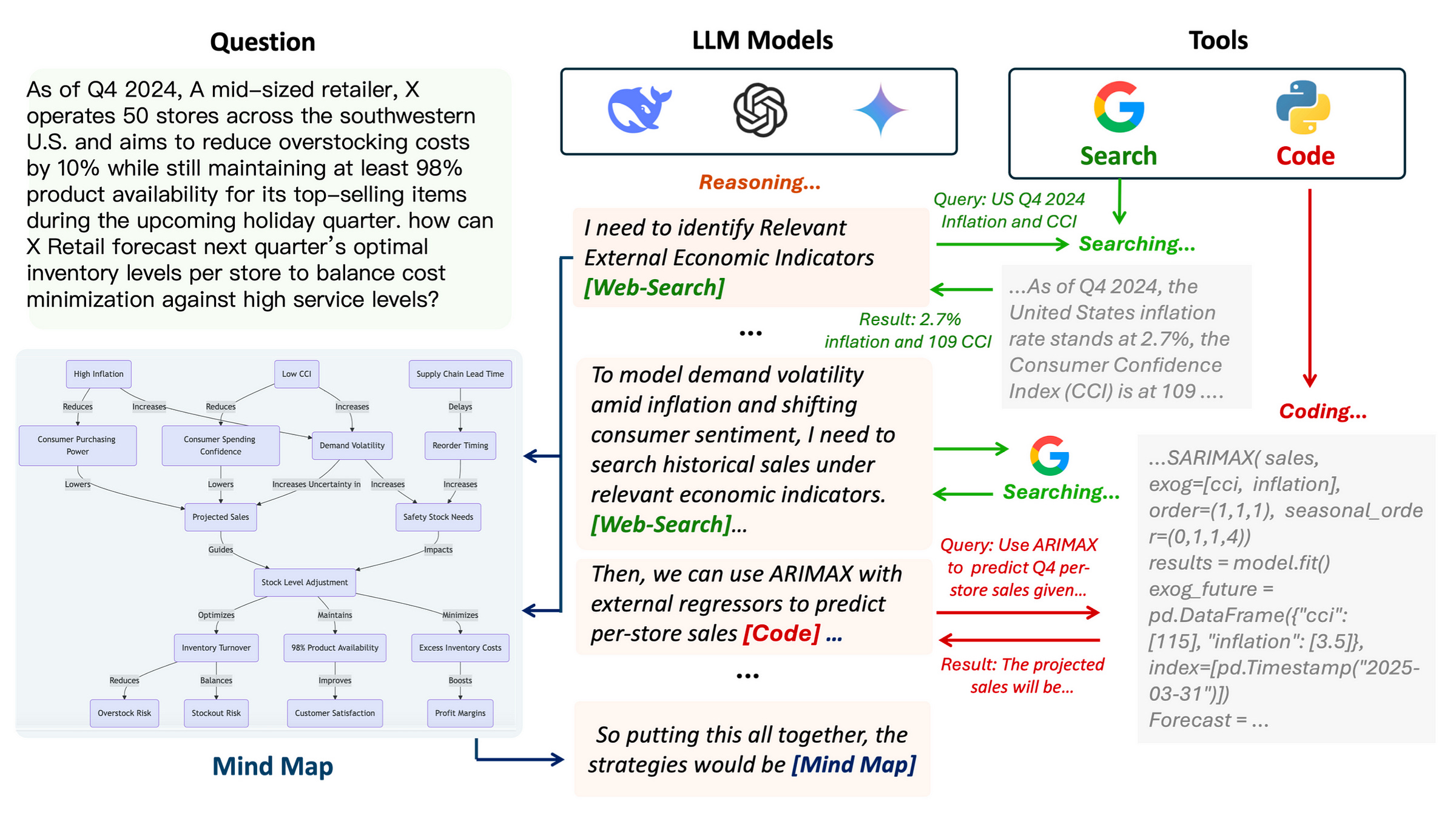
The Components Of Agentic Reasoning
Now that we know how the framework works overall let’s learn how each LLM agent works in more detail.
Web Search Agent
This agent uses tools to perform web searches and retrieve relevant documents.
Instead of using raw web pages directly, these are first processed and filtered before the most relevant content is extracted and dynamically integrated into the reasoning chain.
Coding Agent
Based on the reasoning LLM’s message, the user query and the reasoning context from the Mind Map, this agent generates code, executes it using a compiler and returns the result in a natural language.
This allows easy integration of the response into the reasoning chain.
Mind Map Agent
This agent structures and stores the reasoning context as a structured knowledge graph.
This approach is borrowed from a previous ArXiv research that starts by clustering reasoning context into different groups using Community Clustering and using an LLM to generate summarises for each group.
The resulting knowledge graph can then be queried using RAG to retrieve the relevant information.
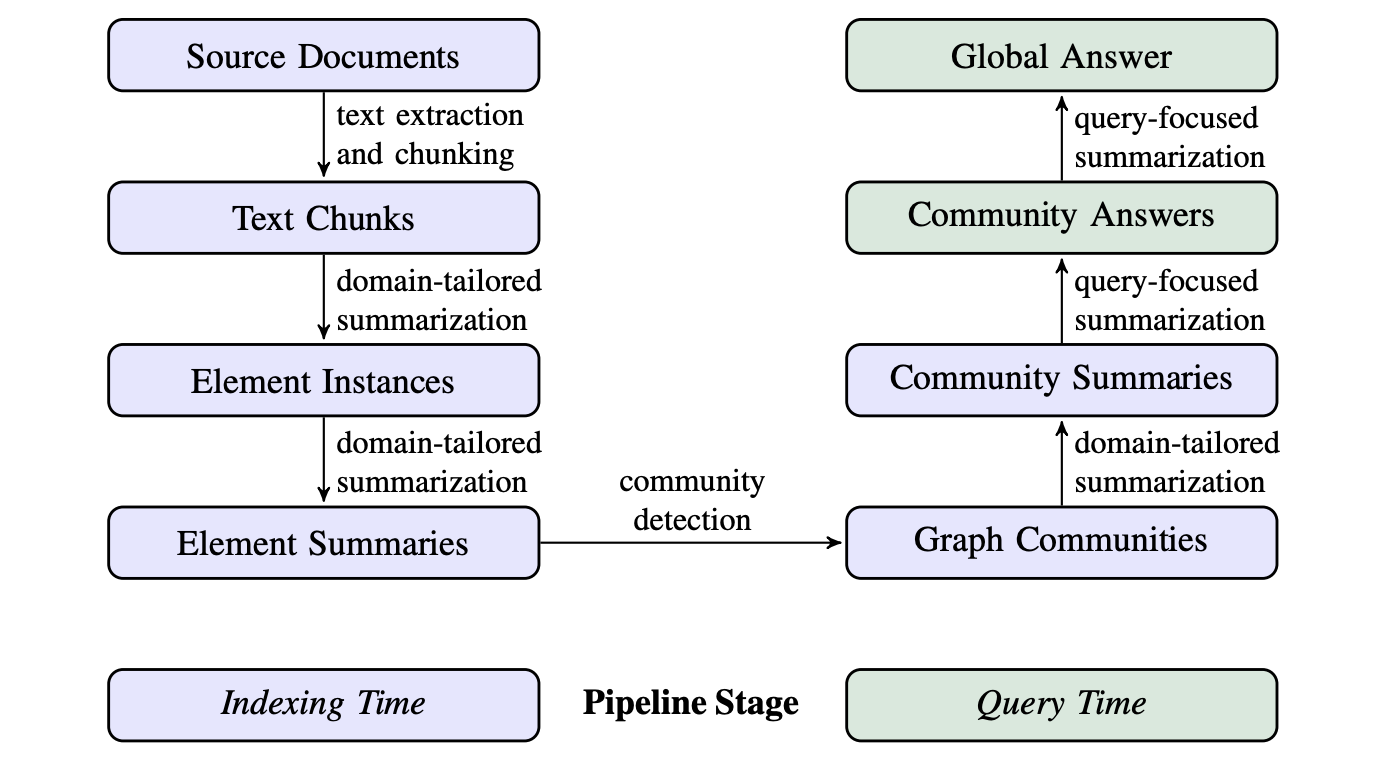
The Mind Map agent serves as a memory for the reasoning LLM and other agents while they are queried during the process.
How Good Is Agentic Reasoning?
It is seen using just a small number of agentic tools in the framework leads to the best results.
This is because adding more tools increases the risk of the reasoning LLM selecting the wrong ones when solving an issue.
Errors also accumulate due to inaccuracies in the tool outputs, which can lead to an incorrect final response.
Next, delegating tasks to multiple LLM agents reduces the “cognitive load” on the reasoning LLM, allowing it to focus on its core task rather than performing all tasks by itself.
Delegation also ensures that the best-performing LLMs are used for each task (for example, DeepSeek-R1 for reasoning and Claude-Sonnet for coding), enhancing overall performance.
It is also seen that using more tools leads to better reasoning for a single question.
However, many tool calls across different questions aren’t necessarily a good thing as they indicate that the initial reasoning of the model might be flawed, leading to a less accurate final answer.
Experiments show that Agentic Reasoning has the best performance on the Diamond set of the GPQA dataset compared to other RL-trained open/ close-sourced reasoning LLMs and RAG-enhanced LLMs.
This dataset consists of PhD level MCQs in Physics, Chemistry and Biology, and its Diamond set consists of 198 of the most challenging questions in these subjects.
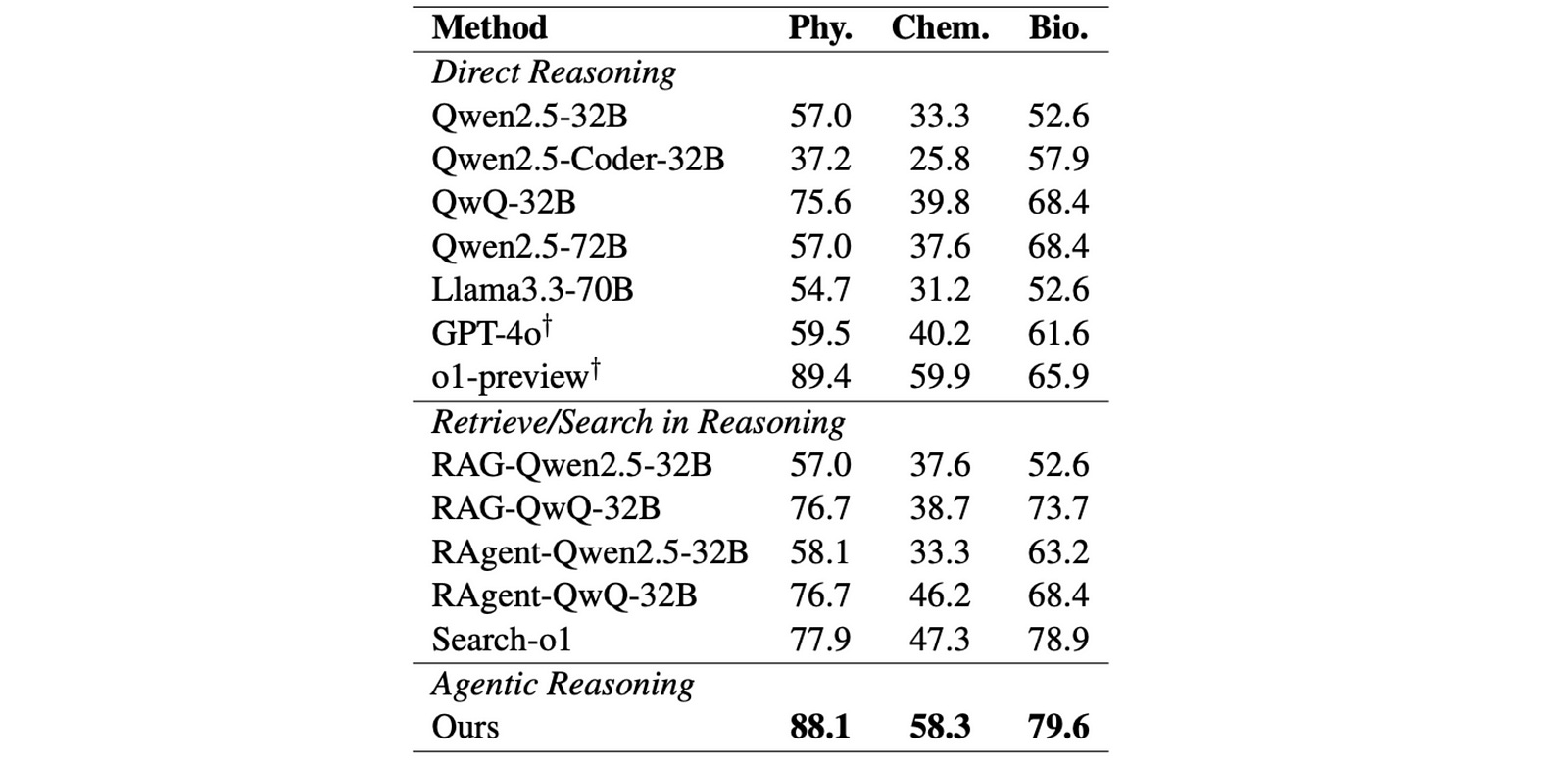
There are further 546 questions in the Extended set of this dataset, and the framework achieves better accuracy than human experts across all subjects in this set as well.
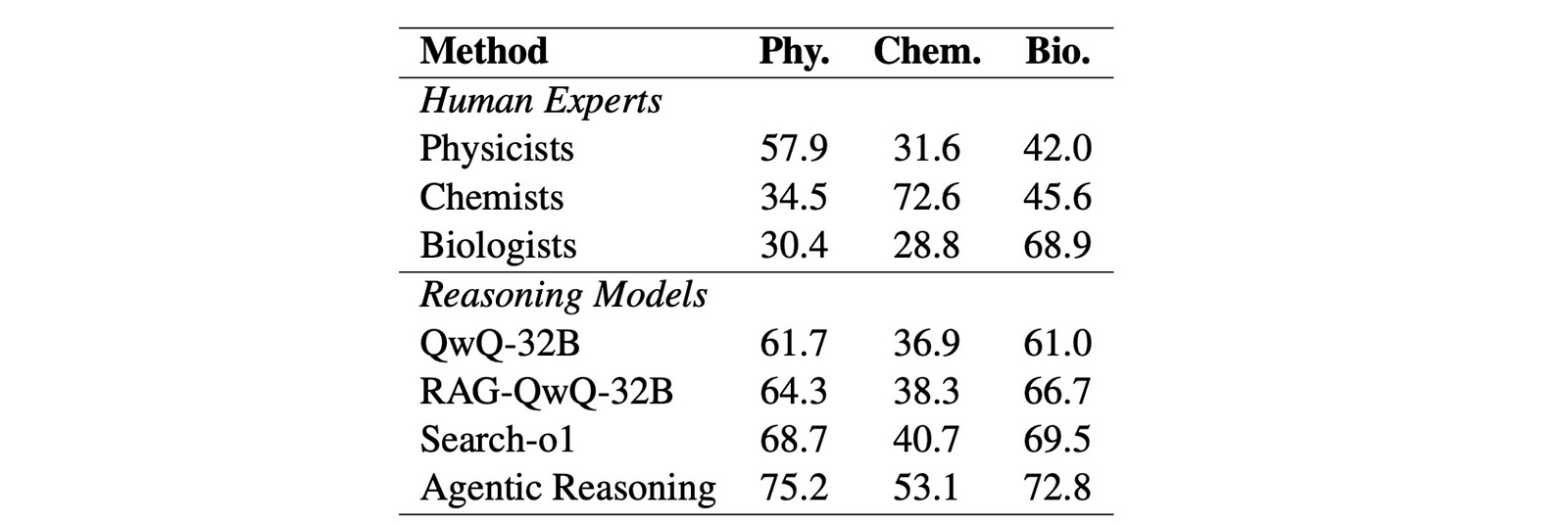
Next, Agentic Reasoning is tested on open-ended, knowledge-intensive Q&A tasks from Finance, Medicine and Law that require deep research.
15–30 such questions are formulated by PhD experts in these subjects.
Each question requires at least 20 minutes of in-depth human expert research to answer them well.
Agentic Reasoning surprisingly outperforms Gemini Deep Research across all these questions from the three subjects, as seen in the plots below.

AI agents will play a massive role in our future when it comes to solving complex problems.
Building open-source AI is the way forward to ensure it constantly improves and remains fair and accessible to all.
Further Reading
Research paper titled ‘Search-o1: Agentic Search-Enhanced Large Reasoning Models’ published in ArXiv
Source Of Images
All images are obtained from the original research paper unless stated otherwise.
