
🗓️ This Week In AI Research (9-15 November 25)
The top 10 AI research papers that you must know about this week.


1. AlphaResearch: Accelerating New Algorithm Discovery with Language Models
AI models, while being impressive with specific tasks, still struggle to discover the previously unknown.
This paper presents AlphaResearch, an autonomous AI research agent capable of discovering new algorithms. AlphaResearch can propose new ideas, verify them, and optimize research proposals to achieve better performance.
Notably, AlphaResearch has discovered an algorithm with the best known performance on the Packing circles problem, beating the results of human researchers and Google DeepMind’s AlphaEvolve.
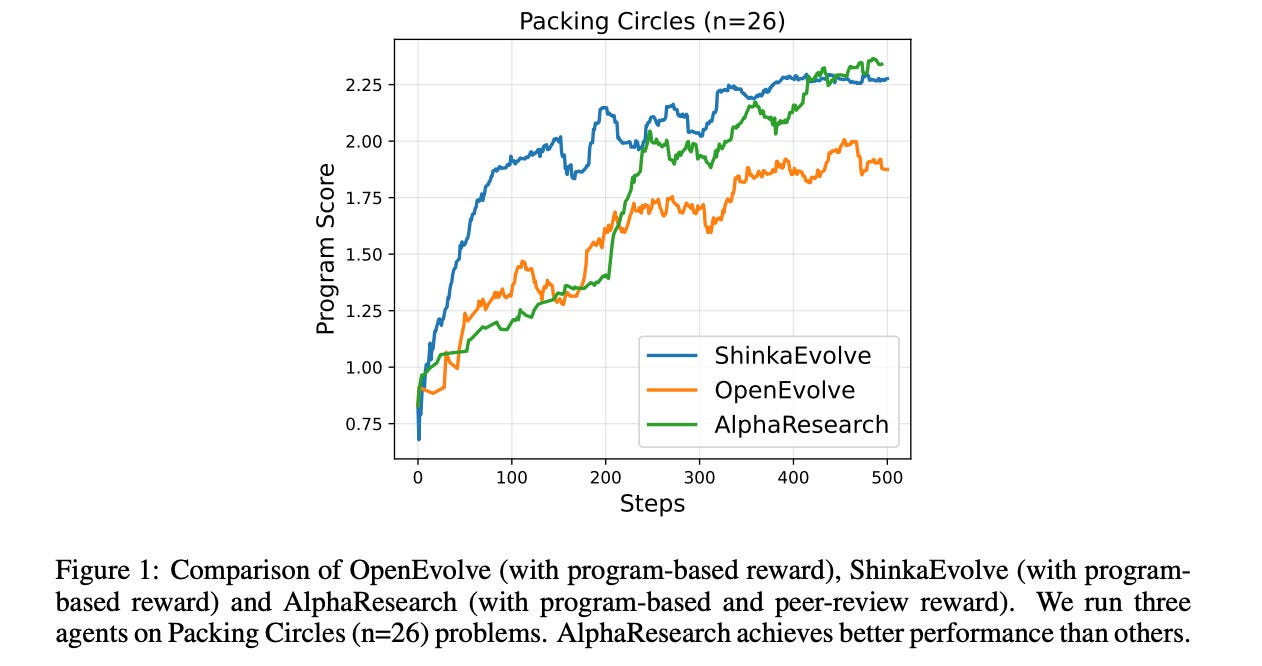
Read more about this research paper here.
Before we move forward, I want to introduce you to the Visual Tech Bundle.
It is a collection of visual guides that explain core AI, LLM, Systems design, and Computer science concepts via image-first lessons.

Others are already loving these books. Why not give them a try?
2. LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
This paper by Randall Balestriero and Yann LeCun focuses on teaching models useful representations of the world without human labels (self-supervised learning).
They introduce a theoretically grounded approach to Joint-Embedding Predictive Architectures (JEPAs), which previously relied on trial-and-error methods.
The authors prove that JEPA embeddings should follow an isotropic Gaussian distribution to minimize prediction risk and introduce a new objective, Sketched Isotropic Gaussian Regularization (SIGReg), to achieve this.
The result is LeJEPA (Latent-Euclidean JEPA), a lean, scalable framework that works stably across different architectures.
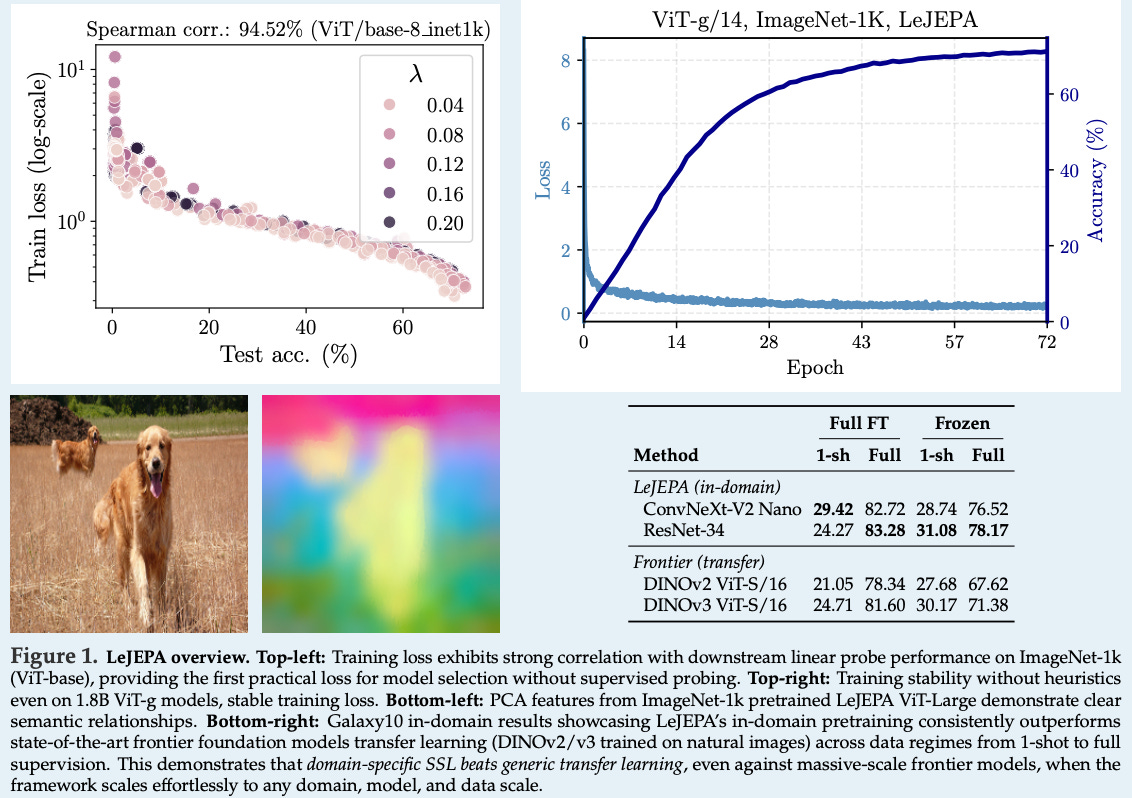
Read more about the research here.
3. Solving a Million-Step LLM Task with Zero Errors
LLMs struggle to solve long-range tasks. As the number of steps in a task increases, errors accumulate, and model performance decreases.
This paper introduces MAKER, a system that successfully solves a Towers of Hanoi task with over one million LLM steps with zero errors.
MAKER uses extreme task decomposition into subtasks, each of which can be tackled by focused microagents.
Such decomposition enables error correction at each step via an efficient multi-agent voting scheme.
This combination of extreme task decomposition and error correction enables scaling to a million steps and beyond.
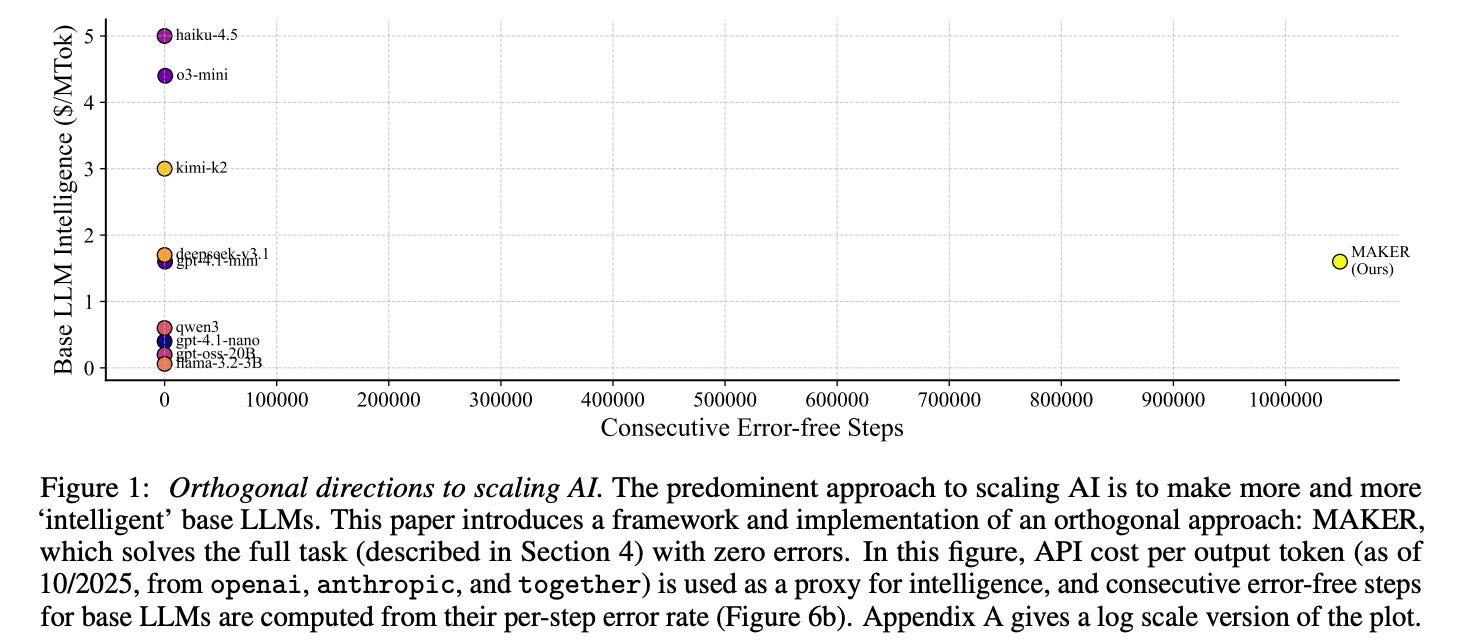
Read more about this research paper here.
4. Depth Anything 3: Recovering the Visual Space from Any Views
This paper from ByteDance Seed researchers introduces Depth Anything 3 (DA3), a model that predicts consistent 3D geometry from any number of images, with or without knowing the camera positions.
It relies on a single standard transformer and a single depth-ray prediction target, and is trained via a teacher–student approach.
On a new visual geometry benchmark covering camera pose estimation, any-view geometry, and visual rendering, DA3 sets a new SOTA across all tasks, surpassing prior SOTA performance by an average of 35.7% in camera pose accuracy and 23.6% in geometric accuracy.
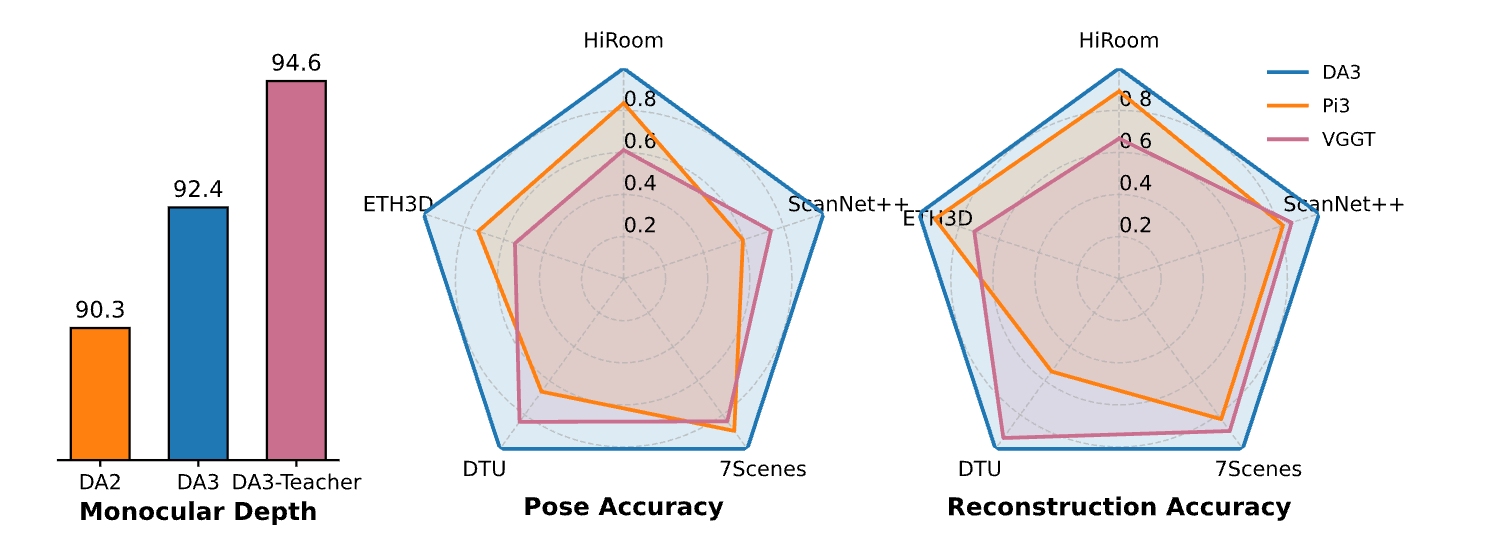
Read more about this research paper here.
5. Hail to the Thief: Exploring Attacks and Defenses in Decentralised GRPO
This paper introduces a near-perfect adversarial attack on decentralized Group Relative Policy Optimization (GRPO), a popular reinforcement learning method used for post-training LLMs.
Researchers show that malicious players can poison decentralized GRPO systems by injecting harmful content into otherwise correct model completions in both out-of-context and in-context attacks.
These attacks are highly effective, achieving success rates up to 100% in as few as 50 iterations.
Researchers also propose defenses that can achieve up to 100% stop rates on such attacks.

Read more about this research paper here.
This article is free to read. If you are enjoying reading this article, restack it and share it with others.
6. The Path Not Taken: RLVR Provably Learns Off the Principals
Reinforcement Learning with Verifiable Rewards (RLVR) improves LLM reasoning while modifying only a small fraction of parameters.
Meta researchers show that this sparsity masks a deeper pattern: RLVR’s optimization consistently updates specific off-principal, low-curvature regions of parameter space that the model preferentially uses.
This non-mainstream approach in weight space explains why the updates appear sparse, even though they significantly alter the model’s behavior and improve its reasoning performance.
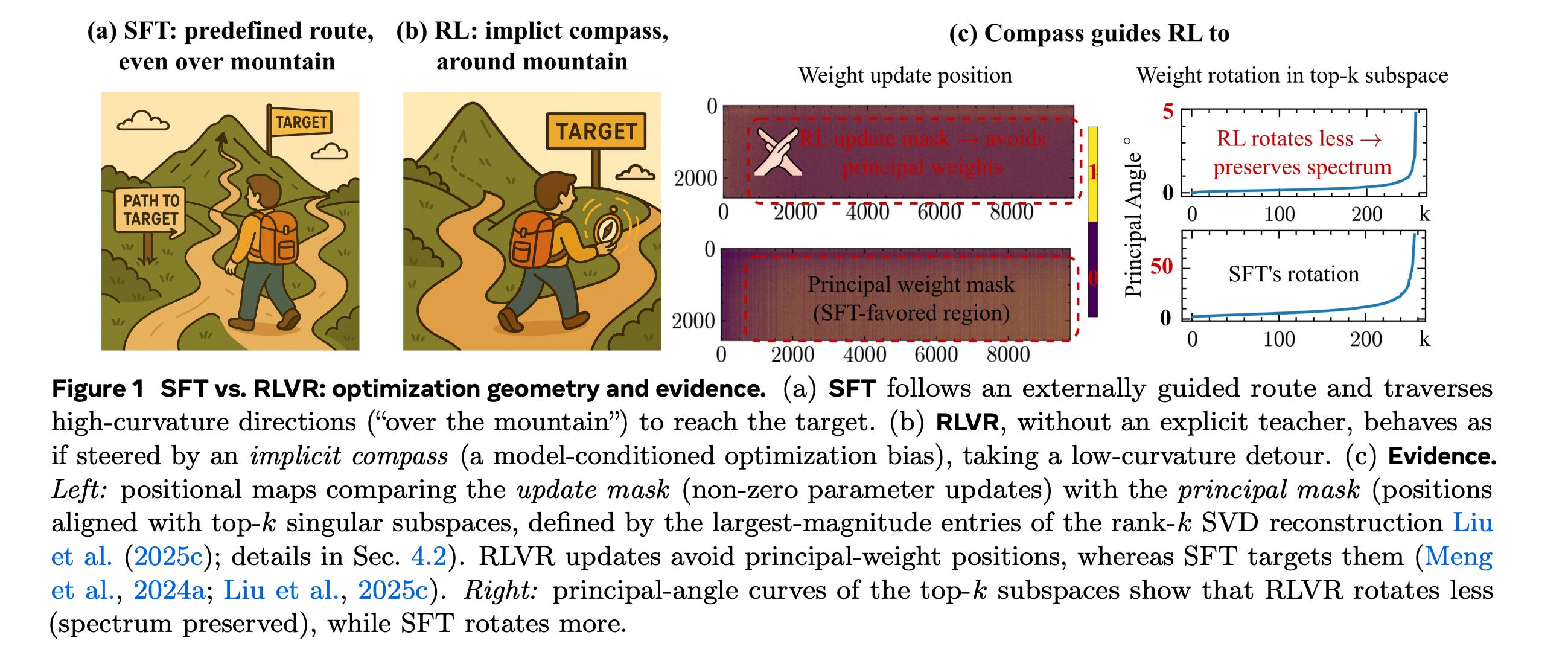
Read more about this research paper here.
7. Training Language Models to Explain Their Own Computations
This paper is a significant step forward in the field of Explainable AI (XAI) and introduces a technique that enables LLMs to faithfully describe their own internal computations.
Using existing interpretability techniques as ground truth, the researchers fine-tune explainer models to produce natural language descriptions of:
the information encoded by the model’s internal features,
the causal structure of activations, and
the influence of specific input tokens on the model’s outputs
Explainer models trained this way, which can access their internals, show meaningful generalization to new queries and work better than using a different model to explain their computations, even when that other model is significantly more capable.
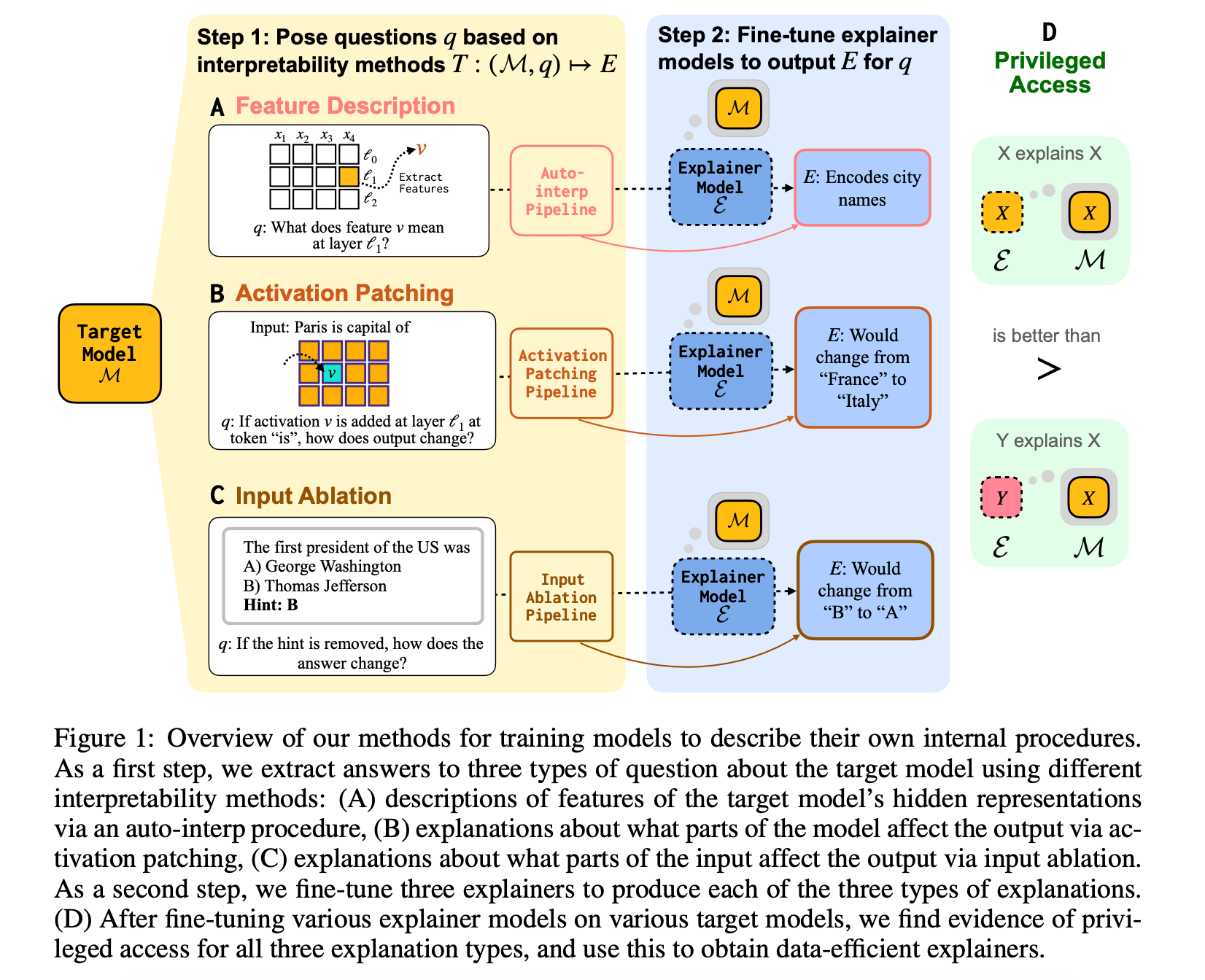
Read more about this research paper here.
8. AgentEvolver: Towards Efficient Self-Evolving Agent System
This paper from Alibaba researchers introduces AgentEvolver, a self-evolving agent system that autonomously learns using the advanced reasoning capabilities of LLMs, without relying on manually built datasets or extensive RL exploration.
It does this through three mechanisms:
Self-questioning
Self-navigating
Self-attributing
Experiments show that AgentEvolver achieves more efficient exploration, better sample utilization, and faster adaptation than traditional RL baselines.
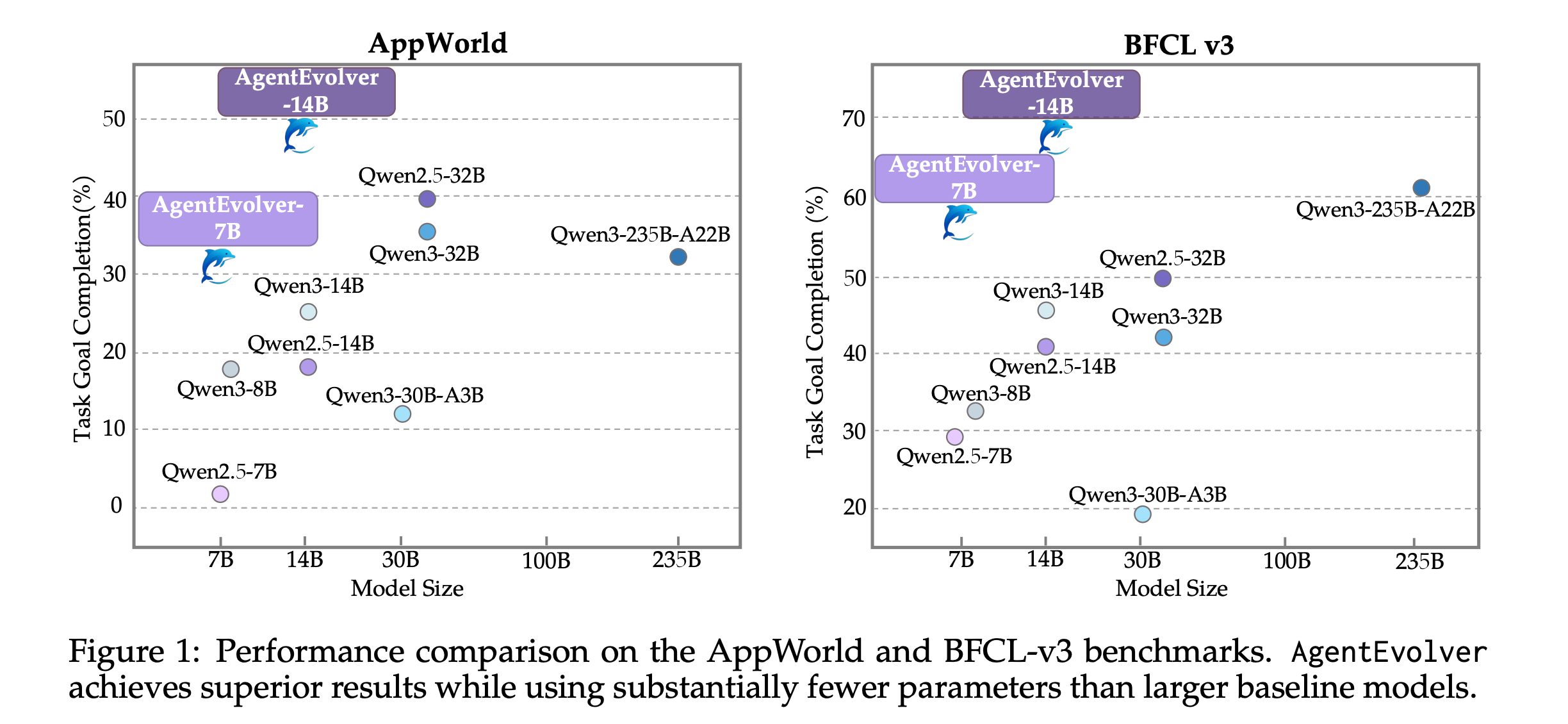
Read more about this research paper here.
9. TiDAR: Think in Diffusion, Talk in Autoregression
This paper from NVIDIA researchers introduces TiDAR, a new hybrid architecture that combines the speed of diffusion models with the quality of autoregressive models for language generation.
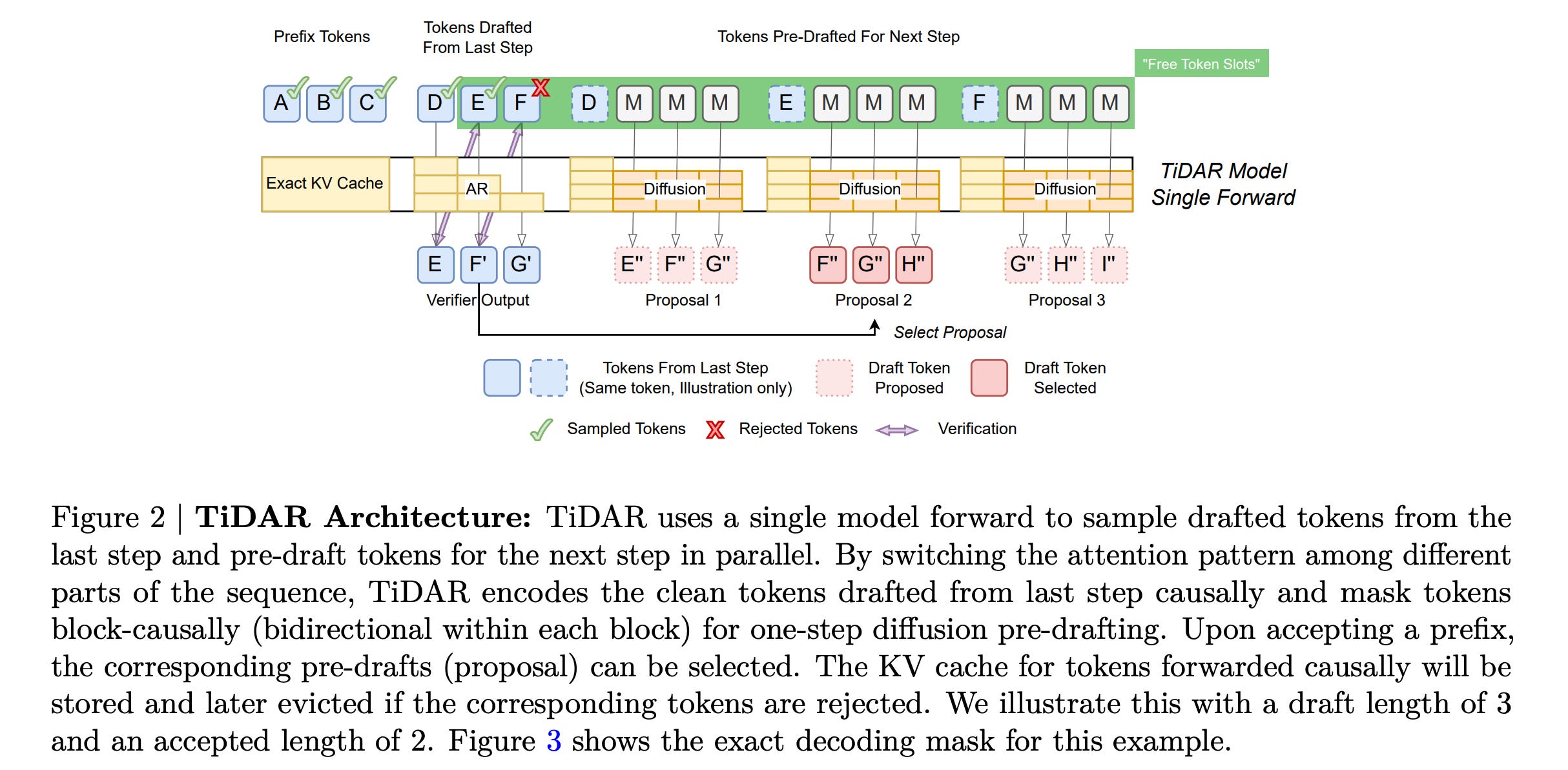
TiDAR drafts tokens in parallel using diffusion (“thinking”) and then samples final outputs autoregressively (“talking”), all within a single forward pass, using specially designed attention masks.

At 1.5B parameters, it generates 4.71× more tokens per second than a standard autoregressive model while maintaining quality, and at 8B parameters, it reaches 5.91× speedup.
Read more about this research paper here.
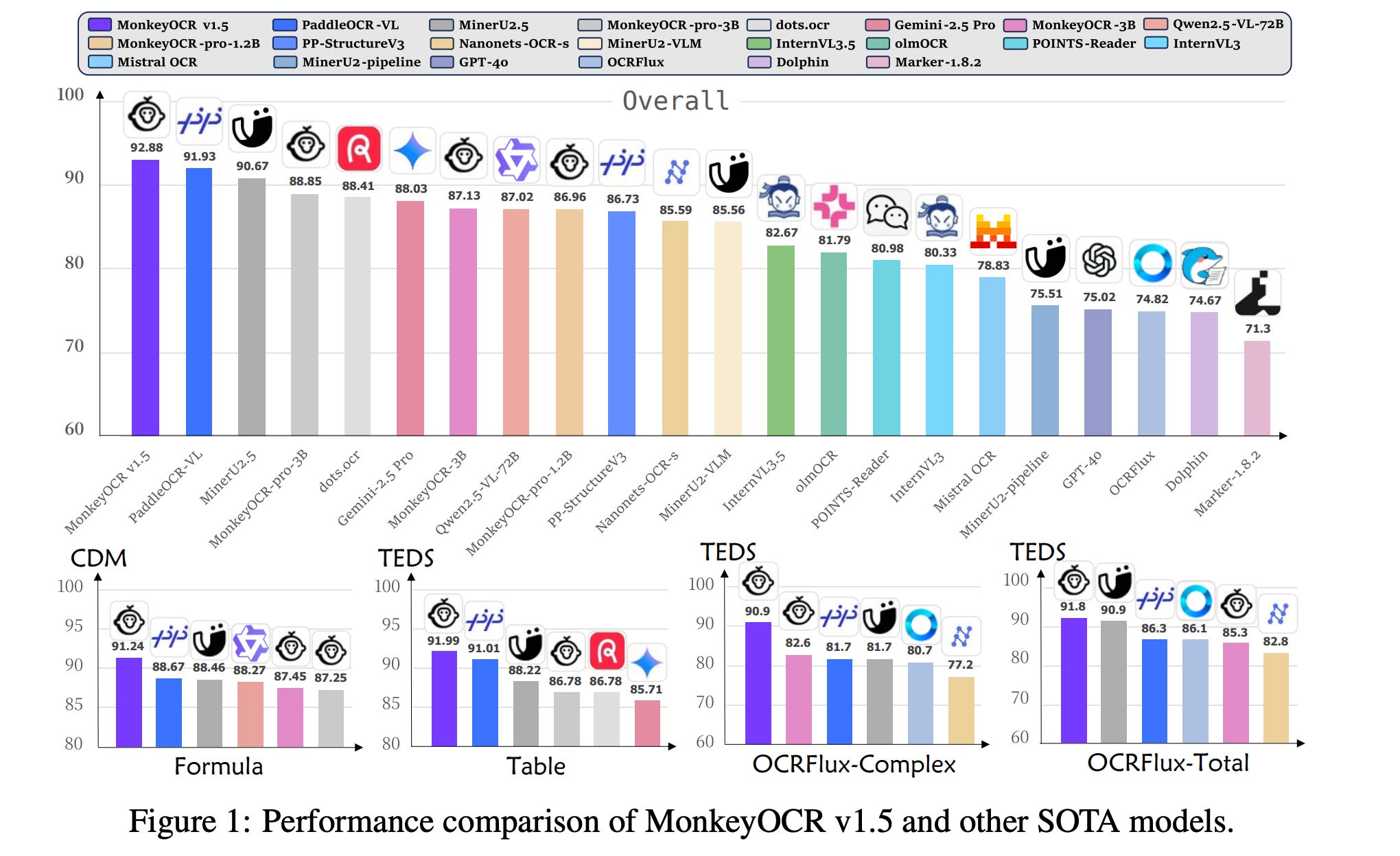
10. MonkeyOCR v1.5 Technical Report: Unlocking Robust Document Parsing for Complex Patterns
MonkeyOCR v1.5 is a unified vision–language framework designed to handle complex documents with multi-level tables, embedded images, formulas, and cross-page structures using a two-stage parsing pipeline.
Experiments on OmniDocBench v1.5, a benchmark for document parsing and evaluation, show that MonkeyOCR v1.5 achieves state-of-the-art performance in visually complex document scenarios.
Read more about this research paper here.
This article is free to read. If you loved reading this article, restack it and share it with others.
If you want to get even more value from this publication, become a paid subscriber and unlock all posts.
You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.
