

You Don't Need 'Thinking' In LLMs To Reason Better
Deep dive and learn about the novel 'NoThinking' method that bypasses thinking in conventional reasoning LLMs to surprisingly supercharge them.


Reasoning LLMs have taken the world by storm.
From multiple closed-source reasoning models to the impressive open-source DeepSeek-R1 and Kimi k1.5, they are bringing us closer to the superintelligence we have always dreamed of.
Reasoning models are trained to take their time and think before they answer, which has been found to be very effective when solving tough problems.
However, recent research has shattered this notion, challenging whether thinking is really needed for reasoning.
Published in ArXiv, researchers propose a new method called ‘NoThinking’, which outperforms Thinking LLMs across seven reasoning tasks (including math, coding, and theorem proving), especially in low-budget settings.
Here’s a story in which we discuss this method in depth and learn how it works so well compared to conventional thinking LLMs.
Let’s begin!
Sure, But What Is ‘Thinking’ In The First Place?
Reasoning LLMs that think through a problem well before they answer are fairly new.
It was just in 2022 that researchers from Google Brain introduced Chain-of-Thought (CoT) prompting.
This technique encourages LLMs to generate intermediate reasoning steps for successfully solving a given complex problem.
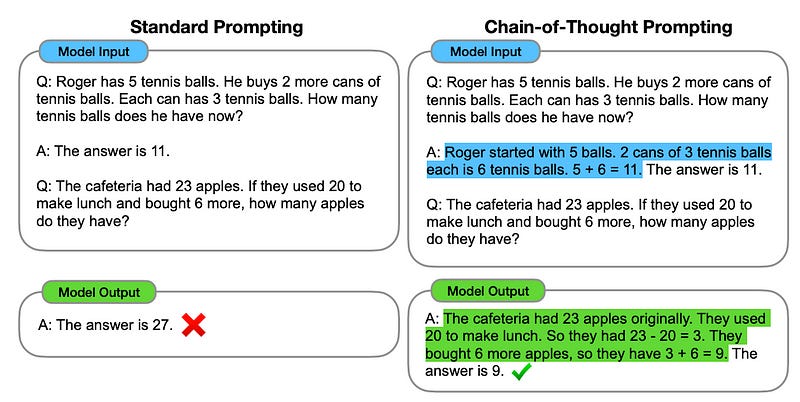
Further prompting approaches soon followed this, all the way up to OpenAI releasing its first reasoning model, o1 and DeepSeek outperforming it and open-sourcing their impressive reasoning approach with R1.
These LLMs think and reason by using Inference-time or Test-time scaling. This is when more computational resources are allocated during inference to improve the LLM’s output quality.
Inference-time scaling can be achieved by simply CoT (or an advanced version) prompting an LLM or using various other techniques mentioned in this paper.
Then there’s another way where LLMs can be trained to internalise Chain-of-Thought reasoning data using Supervised fine-tuning, Reinforcement learning or both.
These LLMs then generate similar long CoT at inference time to reason better (as seen with DeepSeek-R1 and Kimi-k1.5).
When smaller models are supervised fine-tuned with reasoning outputs from larger, more powerful reasoning models, this process is termed Knowledge distillation.
This is seen with DeepSeek-R1-Distill-Llama and DeepSeek-R1-Distill-Qwen models, which are Llama and Qwen models distilled using DeepSeek-R1, respectively.
Although these methods lead to impressive performance, thinking comes with increased token usage (therefore high cost) and high latency.
Numerous methods have been introduced in research to tweak LLM thinking and make it more efficient (“fix overthinking”).
One of the impressive ones uses an RL algorithm called Length Controlled Policy Optimization (LCPO) to train a reasoning LLM called L1 that can follow user-specified reasoning length constraints while maximizing accuracy.
However, going back to the first principles, the following question remained unaddressed:
“Is thinking really required for better reasoning?”
But not anymore.
Reasoning LLMs Are Switched Not To Think Before Answering
For a given query, reasoning models generate their thinking process within <|beginning_of_thinking|> and <|end_of_thinking|> tokens, followed by their final answer.
Researchers call this the Thinking method, which is the default for reasoning LLMs and can cost hundreds to thousands of tokens.
Next, they introduce a method called NoThinking where they prompt LLMs to skip the thinking process and jump straight to the final answer, as follows.
<|beginning of thinking|>
Okay, I think I have finished thinking.
<|end of thinking|>A token budget is used to compare both methods fairly. As per this budget, if the model hits the token limit before finishing, it is forced to end the reasoning and generate the final answer.
Both of these methods and the outputs obtained from them are shown in the image below.

This method seems quite trivial, but the results will surprise you.
Eliminating Thinking Leads To Surprising Results
Researchers use DeepSeek-R1-Distill-Qwen-32B for their experiments.
This reasoning model is created by distilling Qwen32B by training it on the reasoning outputs generated by DeepSeek-R1.
Alongside this, Qwen-32B-Instruct is used as a non-reasoning baseline.
These models are evaluated on:
Mathematical problem solving tasks using AIME and AMC benchmarks for standard problem solving and the OlympiadBench benchmark for advanced problem solving
Coding tasks using the LiveCodeBench benchmark
Formal theorem proving tasks using the MiniF2F and ProofNet benchmarks
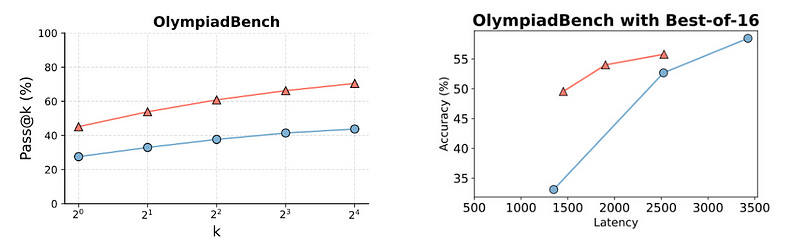
The main metric used to evaluate these methods is pass@k, which is described as follows.
For a given query, an LLM generates n answers. Amongst these, c answers are correct.
The pass@k metric tells the probability that, if you randomly select k answers from the n answers, at least one of them will be correct.

In practice, pass@1 (called ‘first-pass accuracy’) is most commonly used for math and coding benchmarks, while pass@32 is the standard for formal theorem-proving benchmarks.
Let’s move forward to learn about the experiment results.
When the inference token budget is not controlled, NoThinking performs similarly to Thinking on theorem-proving tasks using 3.3-3.7× fewer tokens.
It shouldn’t be thought that the reason for similar performance is that these benchmarks are easy to solve, given that OpenAI’s o1 only gets ~30% accuracy on the MiniF2F benchmark.
On other tasks, NoThinking lags behind on pass@1 but surpasses Thinking as k increases, while still using 2-5× fewer tokens.

When the token budget is controlled, NoThinking generally outperforms Thinking, especially at low budgets, with the performance gap again increasing with higher k values.


Overall, it is seen that NoThinking is a highly efficient method that matches/ beats Thinking while using far fewer tokens, especially in low-resource/ budget settings.
‘NoThinking’ Is Highly Effective When Used With Parallel Inference-Time Scaling
We previously discussed how reasoning LLMs use inference-time compute for better reasoning.
This is a sequential approach where long chain-of-thought tokens are produced, verified, and backtracked in a single forward pass.
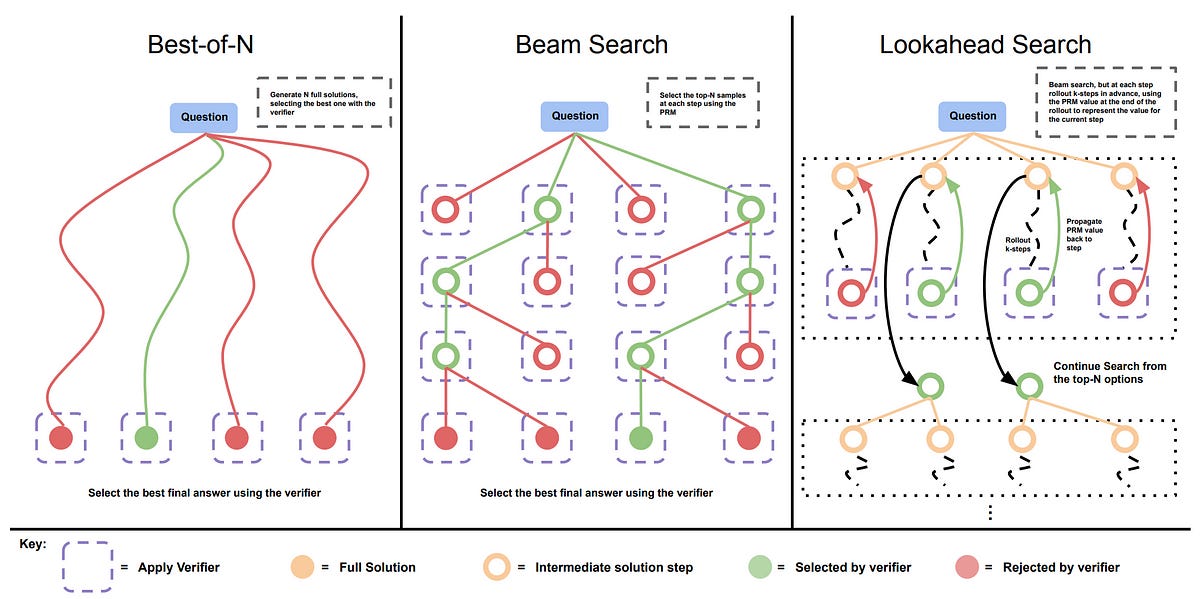
There’s a second category of inference-time scaling methods in which multiple outputs are generated in parallel, and the best is selected from them.

These methods greatly reduce latency for reasoning tasks, as multiple responses can be concurrently generated using a multi-GPU setup or through batching on a single GPU.
For N independent generations in parallel, they are aggregated to produce a single response, and this is called the Best-of-N selection strategy.
Many other strategies are possible, and interested readers are encouraged to check out Figure 2 of this paper.
Since it is seen that the performance of NoThinking improves with higher k, it can be combined well with parallel sampling and Best-of-N selection.
This is how the researchers do it.
For theorem-proving, they use a Lean compiler to check if the output is correct.

For other tasks, where no such verifier is available, two other strategies are used:
Confidence-based Selection: where the LLM computes a self-certainty score for each output using KL divergence between its predicted token distribution and a uniform distribution.
Then, Borda voting ranks and scores the outputs to pick the most likely correct answer.
For coding tasks where direct comparison and voting aren’t possible (due to code outputs being different in syntax but not meaning), the output with the highest confidence is picked.

Majority Voting based Selection: where the final answer is selected as the one that appears most frequently among the generated outputs. This is used for tasks with exact answers, such as math and science problems.
The experiments prove to be successful and show that NoThinking with parallel scaling significantly improves pass@1 accuracy across most benchmarks while greatly reducing latency (up to 9×) and token usage (up to 4×) compared to Thinking.
This is especially true for math and theorem-proving tasks.
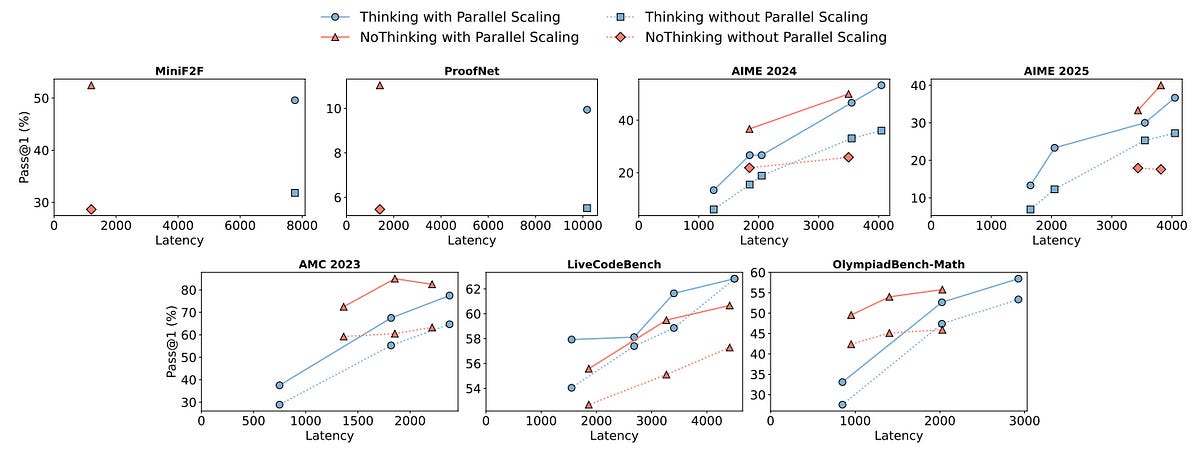
The results of this research are very surprising. It definitely opens up a new avenue for reasoning LLMs, which could be influenced by this approach to be faster and more efficient than ever.
What are your thoughts on this? Let me know in the comments below.
Further Reading
Source Of Images
All images, including the screenshots used in the article, are either created by the author or obtained from the original research paper unless stated otherwise.
