

Learn Hypothetical Document Embeddings (HyDE) By Coding It From Scratch
Build a HyDE-based RAG pipeline in Python without using any fancy frameworks or databases.


HyDE, or Hypothetical Document Embeddings, is a technique that is used to improve the accuracy of RAG systems.
This technique was introduced in the 2022 paper titled ‘Precise Zero-Shot Dense Retrieval without Relevance Labels’.
Here is a lesson where we will learn how a conventional RAG pipeline works, discuss its shortcomings, and then implement HyDE to improve its accuracy, all from scratch.
Let’s begin!
But First, What Is RAG?
The knowledge of an LLM is limited to its training data.
RAG, or Retrieval-Augmented Generation, helps LLMs access up-to-date information by connecting them to external knowledge sources without further training.
Thanks to RAG, LLMs can dynamically generate responses based on external, verifiable data sources rather than the data they were previously trained on.
The terms in RAG mean the following:
Retrieval: the step where an LLM retrieves relevant information/ documents from a knowledge base/ specific private datasets.
Augmentation: the step where the retrieved information is added to the LLM’s input context to augment its available knowledge while answering a query.
Generation: the step where an LLM generates a response given a query and its augmented context.
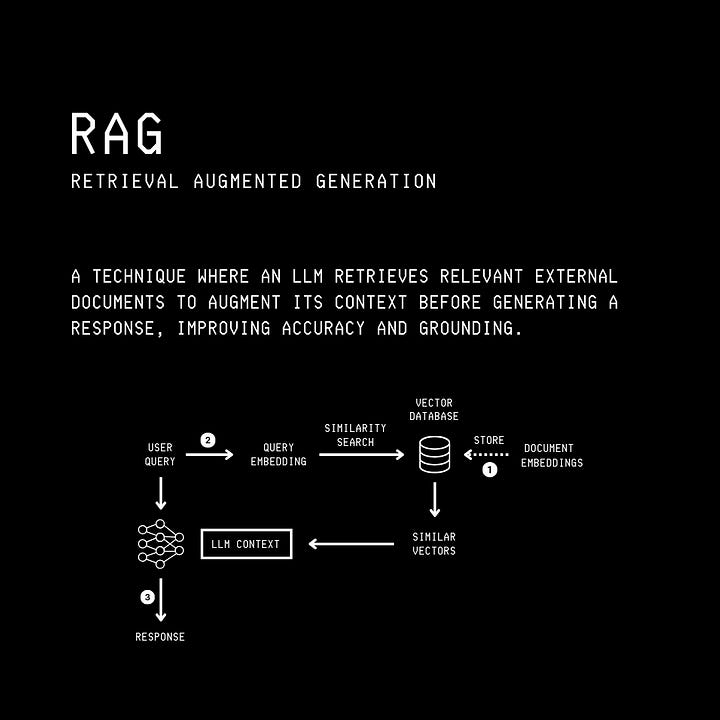
A conventional RAG pipeline has the following steps:
A user queries an LLM
The user query is converted into an Embedding (dense vector) using an Embedding model.
The query embedding is then used to search a Vector Database. This search returns the top-K most relevant documents from the database that could be used to answer the query.
The retrieved documents are combined with the original user query and passed to the LLM as context.
The LLM generates a response and returns it to the user.
What’s The Problem With Conventional RAG?
The effectiveness of RAG largely depends on the quality of retrieval. This is because if we could accurately retrieve the relevant documents needed to answer a query, generating the correct answer would be easy.
In the conventional RAG pipeline, we compare the query embedding with the documents’ embeddings in a vector database to retrieve similar documents.
Let’s understand this better by coding the retrieval aspect of a simple RAG system from the ground up.
For this example, we will use a simple Vector database that we built in a previous tutorial.
import numpy as np
class VectorDatabase:
def __init__(self):
# Store all vectors in an array
self.vectors = []
# Add vector to database
def add_vector(self, vec_id, vector, metadata=None):
record = {
“id”: vec_id,
“vector”: np.array(vector, dtype=np.float32),
“metadata”: metadata
}
self.vectors.append(record)
# Retreive all vectors from database
def get_all_vectors(self):
return self.vectors
# Calculate consine similarity between vectors
def _cosine_similarity(self, vec_a, vec_b):
# Calculate dot product
dot_product = np.dot(vec_a, vec_b)
# Calculate the magnitude of vector A
norm_a = np.linalg.norm(vec_a)
# Calculate the magnitude of vector B
norm_b = np.linalg.norm(vec_b)
cos_sim = dot_product / (norm_a * norm_b + 1e-8) # small epsilon to avoid division by zero
return cos_sim
# Search for similar vectors and return the top_k results
def search(self, query_vector, top_k = 3):
query_vector = np.array(query_vector, dtype = np.float32)
# Stores the top_k results
results = []
for record in self.vectors:
sim = self._cosine_similarity(query_vector, record[”vector”])
results.append({
“id”: record[”id”],
“similarity”: sim,
“metadata”: record[”metadata”]
})
results.sort(key=lambda x: x[”similarity”], reverse=True)
return results[:top_k]This is a simple in-memory database represented by the VectorDatabase class that stores vectors and their optional metadata in a list called vectors.
It has the following methods:
add_vector: To add a new vector to the databaseget_all_vectors: To get the entire list of stored vectorscosine_similarity: To find the cosine similarity between two vectorssearch: To perform a linear scan through the stored vectors in the database, compute cosine similarity between a query vector/ embedding and each stored vector, sort similarity results in descending order, and return the topkresults
In the retrieval phase, the vector database returns the top k similar document vectors for a given query. Let’s start building it.
First, populate our vector database with some medical fact-based documents.
!uv pip install sentence_transformerssentences = [
“Alzheimer’s disease research shows that early cognitive decline is linked to the accumulation of beta-amyloid plaques and tau tangles in the brain. These pathological changes disrupt neural communication long before symptoms become obvious. Large longitudinal studies continue to clarify which biomarkers best predict progression.”,
“In cancer biology, tumor cells often acquire mutations that enable uncontrolled growth and resistance to normal regulatory signals. Genomic sequencing allows researchers to identify these mutations across thousands of samples. Databases cataloging such genomic profiles help scientists compare patterns across cancer types.”,
“Respiratory infections such as influenza can cause significant inflammation of the upper and lower airways. This inflammation contributes to symptoms like fever, cough, and fatigue. Studies show that viral shedding typically peaks shortly before the onset of noticeable symptoms.”,
“Cardiovascular research has demonstrated that atherosclerosis develops gradually as cholesterol-rich plaques accumulate within arterial walls. These plaques may remain stable for years but can become dangerous if they rupture. Large epidemiological cohorts continue to refine understanding of risk factors.”,
“In type 2 diabetes, insulin resistance limits the ability of cells to take up glucose effectively. Over time, pancreatic beta cells may struggle to compensate, leading to chronically elevated blood sugar. Genetic, metabolic, and environmental factors all contribute to disease development.”,
“Chronic kidney disease is often detected through long-term trends in glomerular filtration rate and markers of kidney damage. Research indicates that early stages may progress slowly and remain asymptomatic. Population studies help identify patterns associated with faster progression.”,
“Parkinson’s disease is characterized by the gradual loss of dopamine-producing neurons in the substantia nigra. This loss leads to motor symptoms such as bradykinesia, rigidity, and tremor. Neuroimaging and molecular studies continue to investigate the underlying mechanisms of neuronal degeneration.”,
“Asthma involves chronic inflammation and hyperreactivity of the airways, which can narrow in response to environmental triggers. Genetic predisposition, allergen exposure, and airway remodeling all play roles in disease expression. Research efforts focus on understanding these contributing pathways.”,
“In inflammatory bowel disease, chronic inflammation affects the gastrointestinal tract through immune dysregulation. Ulcerative colitis and Crohn’s disease differ in their patterns of involvement and depth of inflammation. Ongoing research investigates interactions between the microbiome and the immune system.”,
“Migraine is a neurological condition involving recurrent episodes of moderate to severe head pain. Scientists believe that cortical spreading depression, neurovascular changes, and genetic susceptibility contribute to the disorder. Studies also examine sensory hypersensitivity as a core feature.”,
“Heart failure develops when the heart can no longer pump blood efficiently to meet the body’s needs. Structural changes such as ventricular remodeling often occur over extended periods. Imaging and biomarker data help researchers track disease progression across diverse patient groups.”,
“Osteoporosis results from reduced bone mineral density and deterioration of bone microarchitecture. This increases susceptibility to fractures, especially in older adults. Research highlights the roles of hormonal changes, calcium metabolism, and genetic factors in bone strength.”,
“In multiple sclerosis, immune cells mistakenly attack the myelin sheath that insulates nerve fibers in the central nervous system. This leads to disruptions in nerve signal conduction and varied neurological symptoms. Imaging techniques like MRI reveal characteristic lesions.”,
“Chronic obstructive pulmonary disease typically develops after long-term exposure to airway irritants, leading to persistent airflow limitation. Structural changes such as alveolar destruction and airway narrowing contribute to progressive breathing difficulty. Population studies track global disease burden.”,
“Sickle cell disease arises from a mutation in the beta-globin gene, causing hemoglobin to polymerize under low oxygen conditions. This results in rigid, sickle-shaped red blood cells that can block blood flow. Research focuses on understanding genetic modifiers and hemoglobin dynamics.”,
“Neurons in the brain communicate through electrical impulses and chemical neurotransmitters, and disruptions in these signaling pathways are a common feature of many neurological disorders such as Parkinson’s disease.”,
“NeuroVita Therapeutics is pioneering a monoclonal antibody designed to target alpha-synuclein aggregates, a hallmark of Parkinson’s disease. Their innovative approach aims to slow neurodegeneration and improve motor function in patients. Clinical trials are underway to evaluate safety and efficacy in early-stage Parkinson’s.”
]from sentence_transformers import SentenceTransformer
# Instantiate embedding model
model = SentenceTransformer(”all-MiniLM-L6-v2”)
# Instantiate database
db = VectorDatabase()
for idx, sentence in enumerate(sentences):
# Create sentence embedding
embedding = model.encode(sentence)
# Add sentence embedding to the database
db.add_vector(vec_id=f”sent_{idx}”, vector=embedding, metadata={”sentence”: sentence})Next, we write up a query that can be answered using the information in the documents, and create an embedding for it
# Query
query = “Which company is making new antibody to treat Parkinson’s disease
and what is it’s target?”
# Create query embedding
query_vec = model.encode(query)Finally, we search the vector database to find the top 3 similar documents to our query.
# Search the database for top 3 similar documents
results = db.search(query_vec, top_k = 3)
# Print the results
print(f”Query: \”{query}\”\n”)
for res in results:
print(f”Similar Sentence: {res[’metadata’][’sentence’]}”)
print(f”Cosine Similarity Score: {res[’similarity’]:.2f}\n”)Here is what we get.
Query: “Which company is making new antibody to treat Parkinson’s disease and what is it’s target?”
Similar Sentence: NeuroVita Therapeutics is pioneering a monoclonal antibody designed to target alpha-synuclein aggregates, a hallmark of Parkinson’s disease. Their innovative approach aims to slow neurodegeneration and improve motor function in patients. Clinical trials are underway to evaluate safety and efficacy in early-stage Parkinson’s.
Cosine Similarity Score: 0.67
Similar Sentence: Parkinson’s disease is characterized by the gradual loss of dopamine-producing neurons in the substantia nigra. This loss leads to motor symptoms such as bradykinesia, rigidity, and tremor. Neuroimaging and molecular studies continue to investigate the underlying mechanisms of neuronal degeneration.
Cosine Similarity Score: 0.45
Similar Sentence: Neurons in the brain communicate through electrical impulses and chemical neurotransmitters, and disruptions in these signaling pathways are a common feature of many neurological disorders such as Parkinson’s disease.
Cosine Similarity Score: 0.31The retrieval accuracy of this conventional RAG pipeline might be low because the query length and structure do not closely match those of the document vectors in the vector database.
The query is shorter than the documents in the vector database, and it reads more like a question than an answer. This means that the query and the documents will not align closely when represented in the multi-dimensional embedding space.
Let’s next discuss Hypothetical Document Embedding (HyDE), which addresses this problem.
What Is HyDE?
Hypothetical Document Embedding (HyDE) is a technique that improves the retrieval accuracy of an RAG pipeline.
It involves:
First, generating a hypothetical answer to a given query
The generated hypothetical answer is next used to find relevant documents in the vector database. This answer does not need to be completely correct, but given its structural and length similarities, it will still closely match the documents in the vector database.
The retrieved documents are finally used to answer the query accurately.
Let’s build it to see if this approach works better.
