

Top Vision Models Cannot Really See Our World
A new vision benchmark exposes the poor vision capabilities of top Multimodal LLMs available today. What does this mean for the future of AI?


AI models have come a long way from barely being able to identify images of digits to now being able to interpret the objects that form the world around us.
Although these abilities seem remarkable, new research has shown that our best Multimodal LLMs catastrophically fail on simple vision-specific tasks that are easy for humans.
Their newly created benchmark, called the Turing Eye Test (TET), tests this and points out major visual defects in the vision capabilities of these models.
These defects persist even when the model is shown examples with solutions in its prompts (In-Context learning) or when its language backbone is fine-tuned on these examples.

Here is a story where we explore the true vision capabilities of Multimodal LLMs and learn how they are far from human perception.
Let’s begin!
My latest book, called “LLMs In 100 Images”, is now out!
It is a collection of 100 easy-to-follow visuals that describe the most important concepts you need to master LLMs today.
Grab your copy today at a special early bird discount using this link.

But First, What Are Multimodal LLMs?
Multimodal LLMs (MM-LLMs) are language models with augmented capabilities. They can not only understand text but also operate across multiple data modalities (video, audio, and images), either as their inputs or outputs.

One of the first successful architectures that laid the groundwork for Multimodal LLMs was CLIP, introduced by OpenAI.
CLIP, or Contrastive Language–Image Pre-training, is a model trained on millions of image-text caption pairs using Contrastive learning/ pre-training.
In this technique, the model learns to distinguish between similar (positive) and dissimilar (negative) pairs of data points.
With its training, CLIP learns to align visual and textual representations (embeddings) in a shared embedding space.
This enables it to link visual concepts in images with their respective names/ captions.
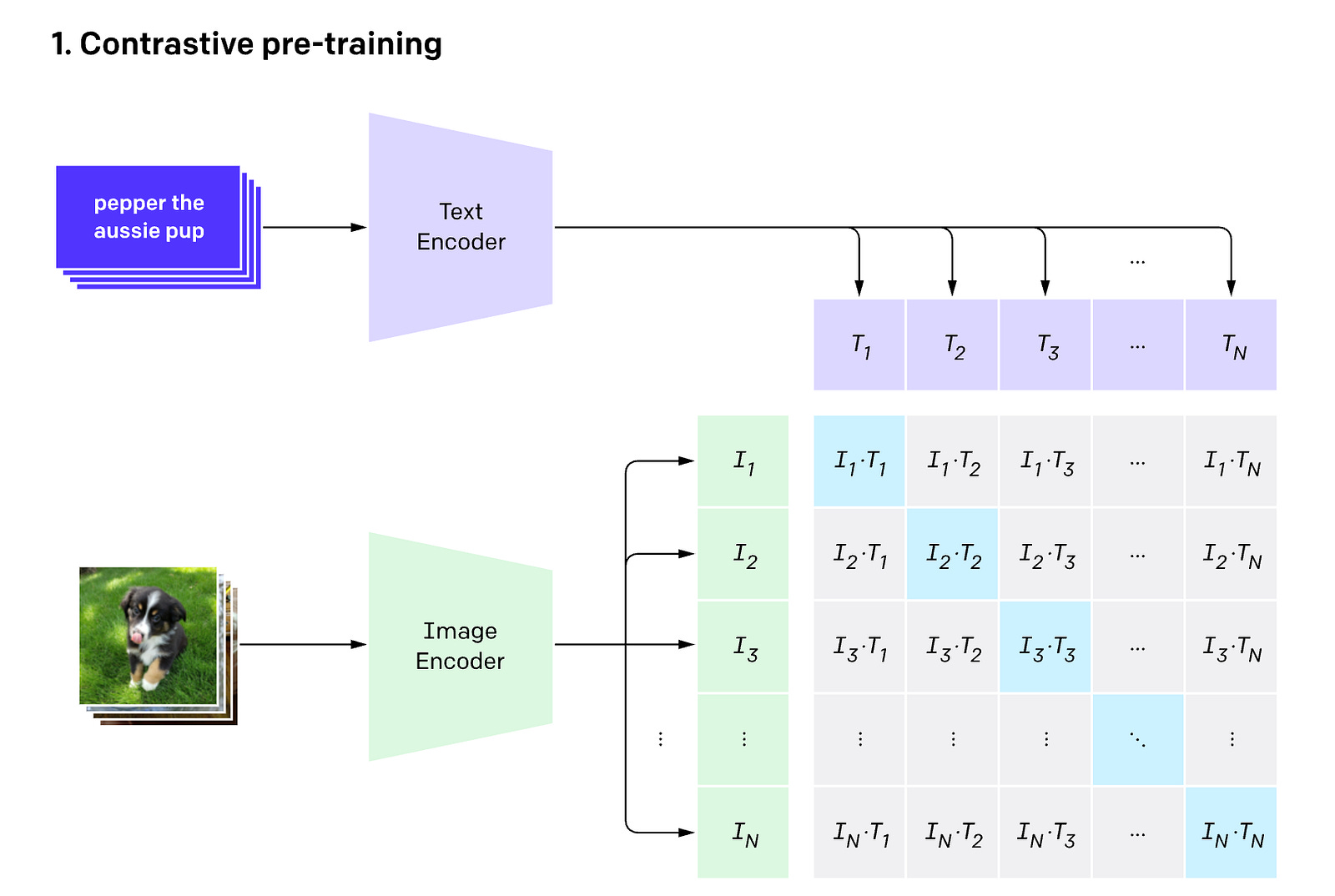
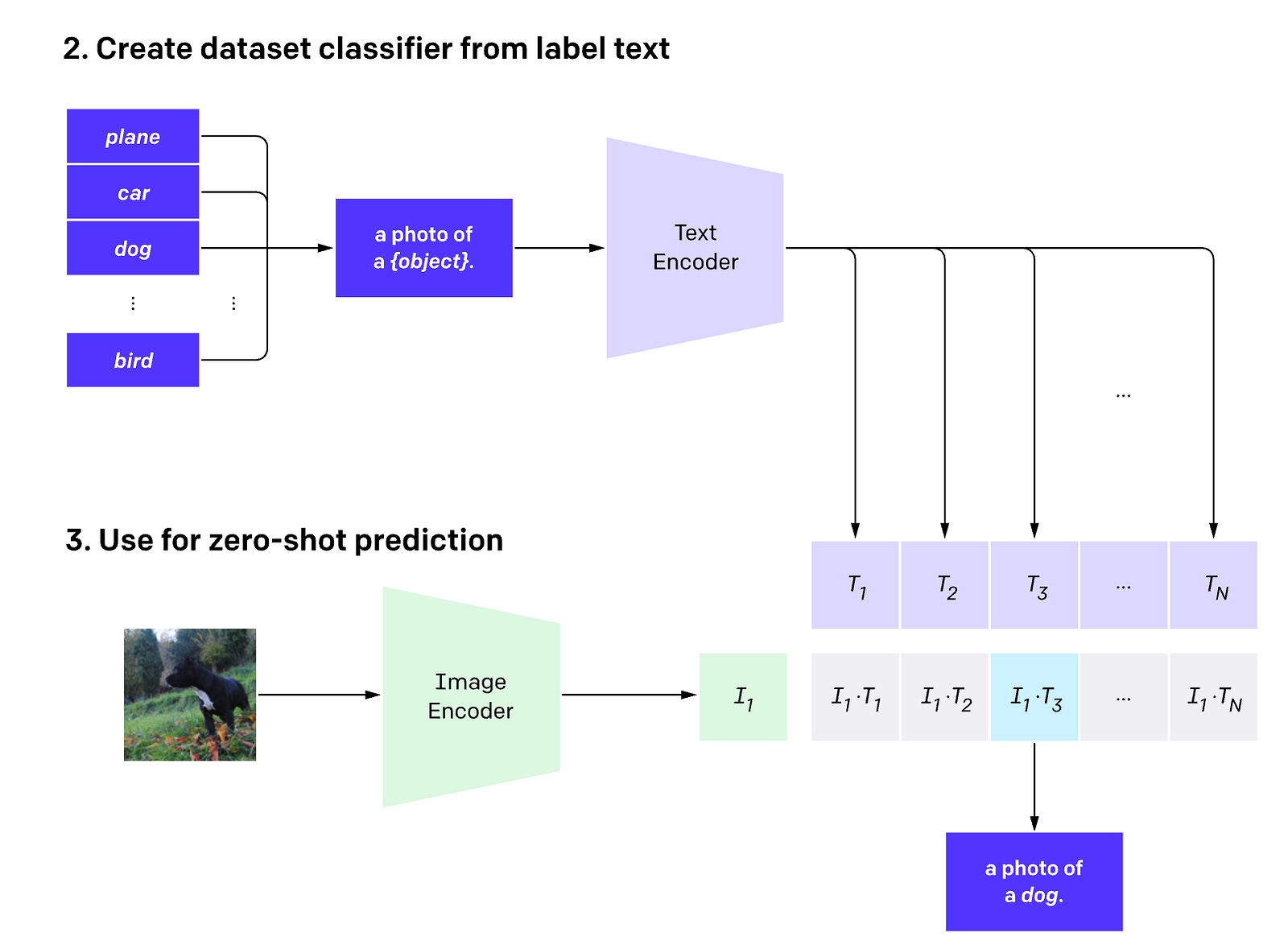
Following Contrastive pre-training, CLIP can be used for image classification tasks even in a zero-shot fashion, with new categories it has never seen before.
It does this by simply comparing a given image’s embedding to text embeddings of potential labels and finding the best match.
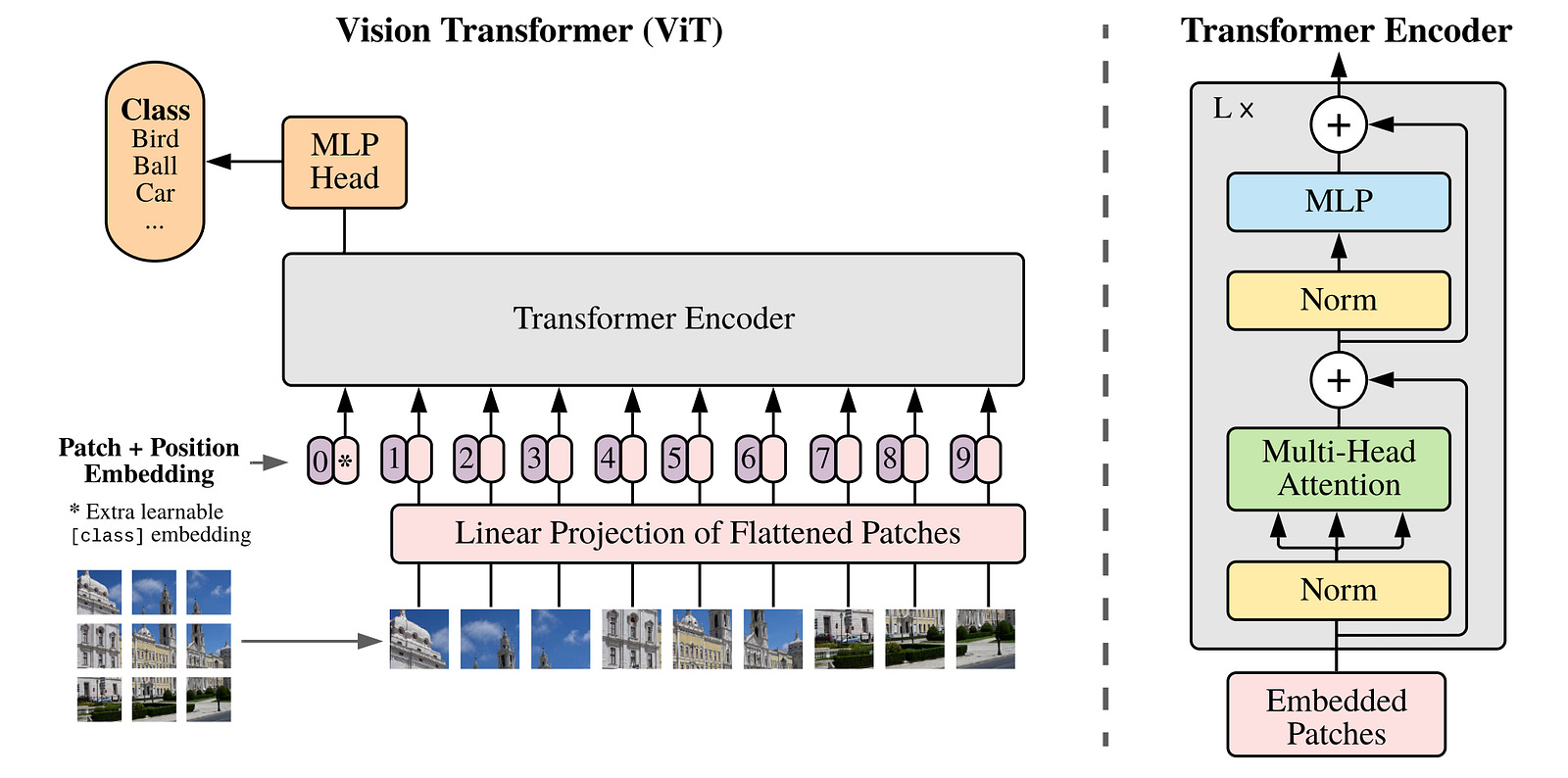
Alongside CLIP, a 2021 research paper introduced Vision Transformer (ViT), which applies the Transformer architecture directly to sequences of image patches, achieving impressive accuracy on image classification tasks.
These architectures further led to Multimodal LLMs of the present day, which are categorized into two major architectural paradigms:
Modular: These models connect encoders and generators of different modalities into an LLM using lightweight projection modules.
Examples of this approach popularly include Qwen2.5-VL, Kimi-VL, and BLIP-2.
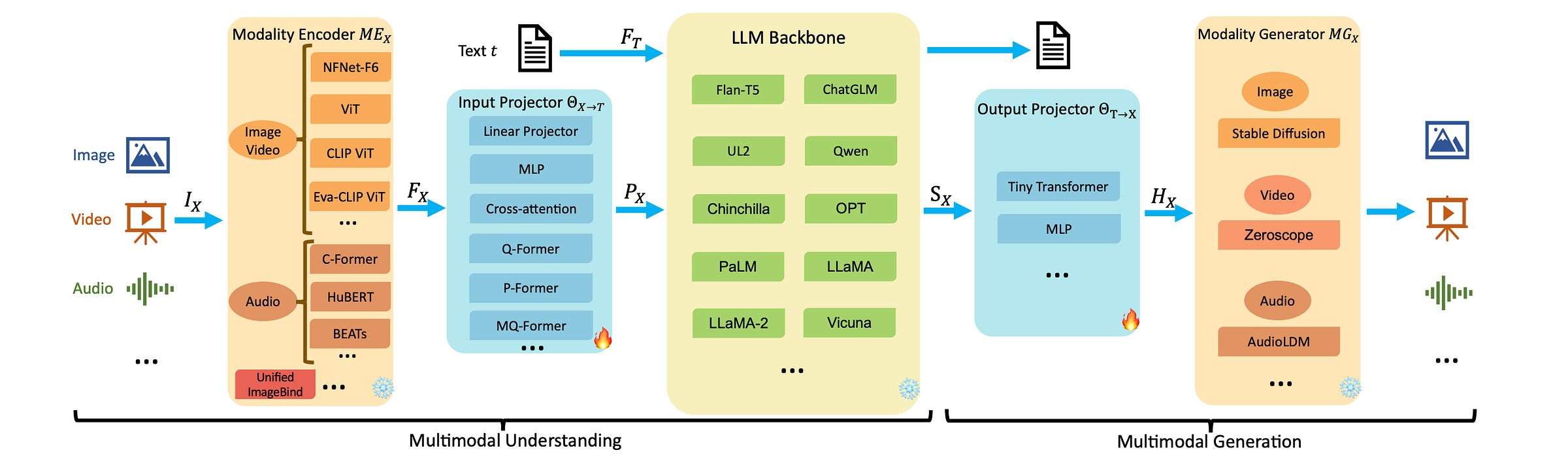
2. Unified: These models are trained using textual tokens along with tokens from all other modalities within a shared architecture.
This eliminates the need for separate encoders for different modalities.
Examples of this approach include Janus-Pro, Bagel, and Transfusion.
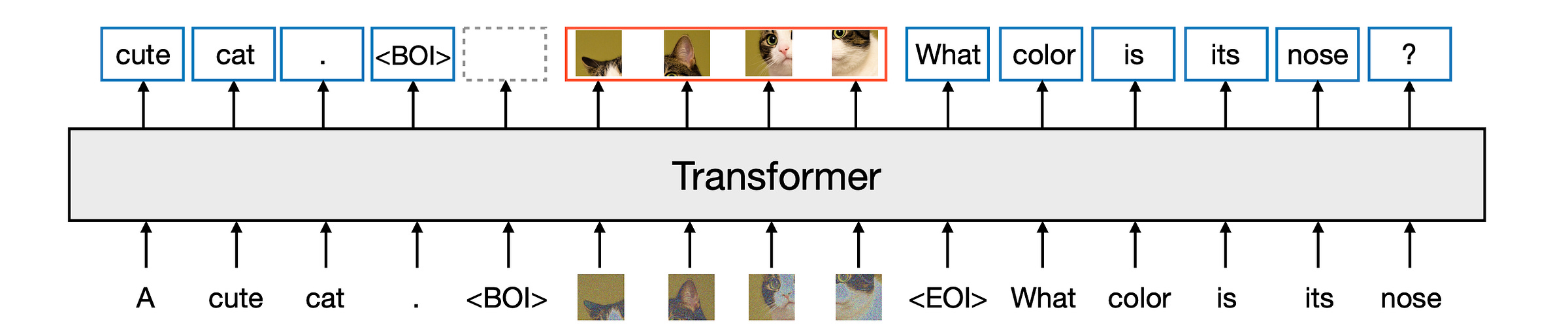
Stress Testing Multimodal LLMs
State-of-the-art Multimodal LLMs have remarkable performance on many Multimodal reasoning benchmarks such as Math Vision, MathVista, and MMMU.
However, there’s a possibility that these Multimodal benchmarks test the language backbone (for knowledge and reasoning) of these MM-LLMs rather than how well they visually perceive things.
To test their visual ability specifically, researchers created a specialized benchmark called the Turing Eye Test (TET).
This benchmark consists of four specialized datasets with images that are easy to interpret for humans:
HiddenText: A collection of 150 images, with each containing text that is embedded as shapes that become readable only when zoomed out. This dataset tests a model's global visual recognition capabilities.

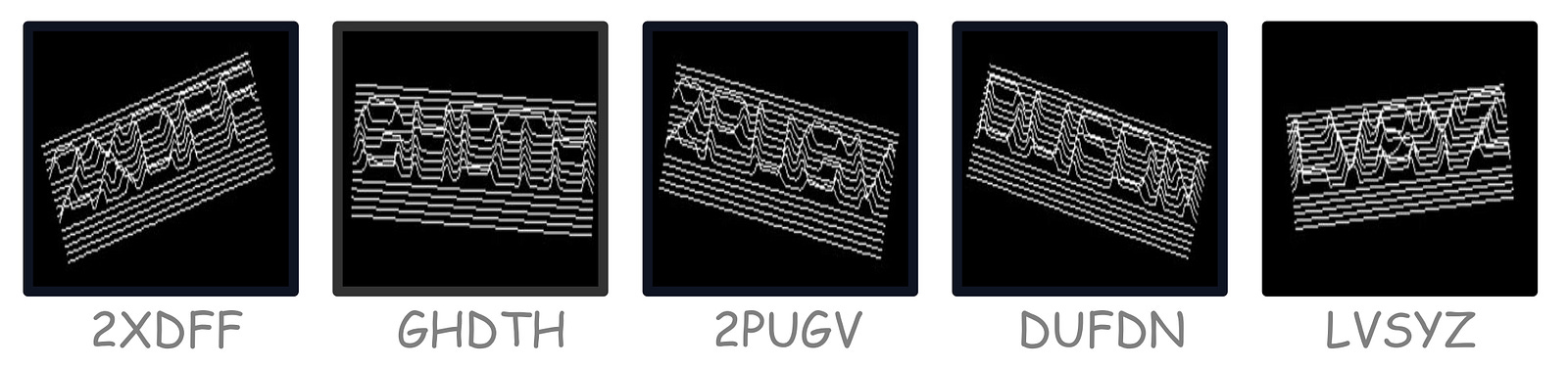
3DCaptcha: A collection of 150 captchas with characters that are distorted in 3D curved forms. This dataset tests a model’s ability to perceive spatially distorted alpha-numerical characters.
ColorBlind: A collection of 150 images that are inspired by Ishihara tests for color blindness. These images hide characters among similarly colored dots and test a model’s pattern perception in noisy, color-confusing environments.

ChineseLigatures: A collection of 40 words/ phrases formed by combining multiple real Chinese characters. This dataset tests a model’s ability to recognize and understand complex characters.

This benchmark is then shown to 15 MM-LLMs (both open-source and closed-source models), and the following metrics are used to evaluate them.
Pass@1 or single-shot accuracy: The chance that a model gives the correct answer on the first try.
Pass@K: The chance that a model gives at least one correct answer if it tries ‘K’ times.

Get Ready For Some Disappointing Results
State-of-the-art MM-LLMs fail drastically when tested on the benchmark, with most achieving zero success rates in the Pass@1 evaluation.
While some models show slightly better performance at Pass@32 (i.e., if the model tries 32 times, it gets the answer right at least once), the improvement of a few percent is practically negligible.
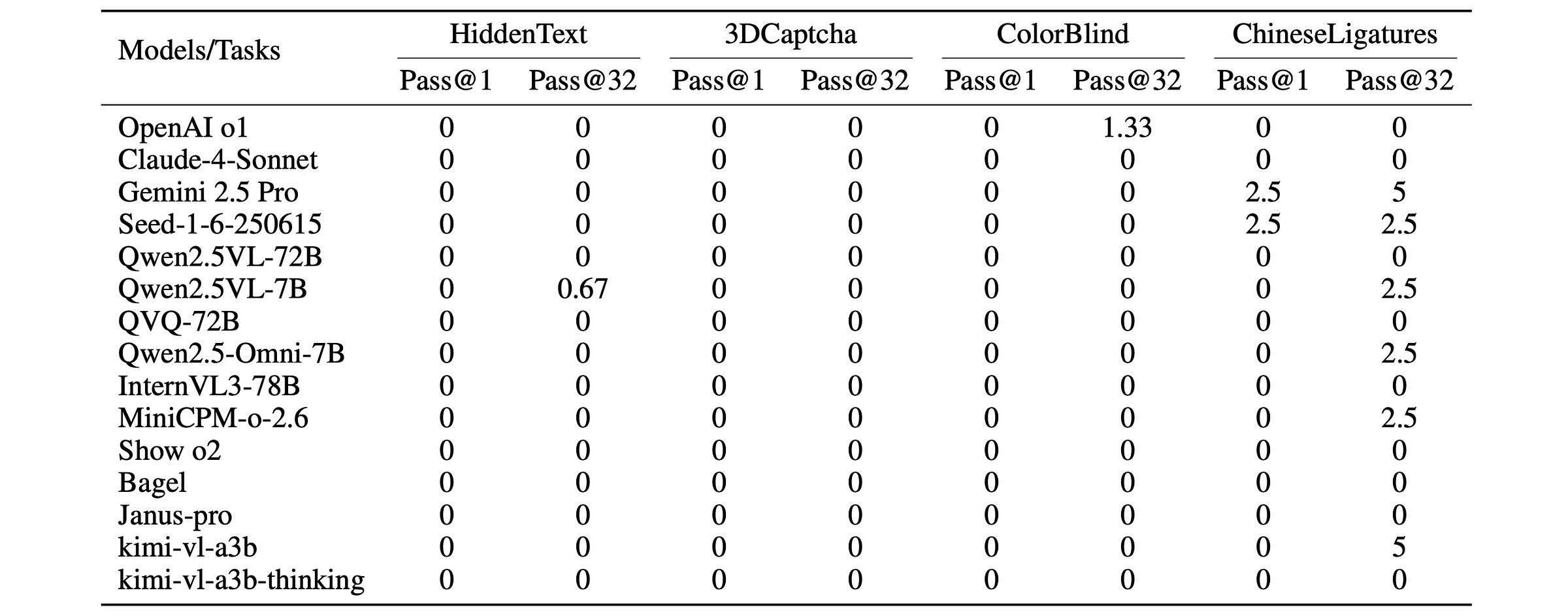
The performance remains almost unchanged even as the number of attempts increases (larger ‘K’), across all models and tasks.
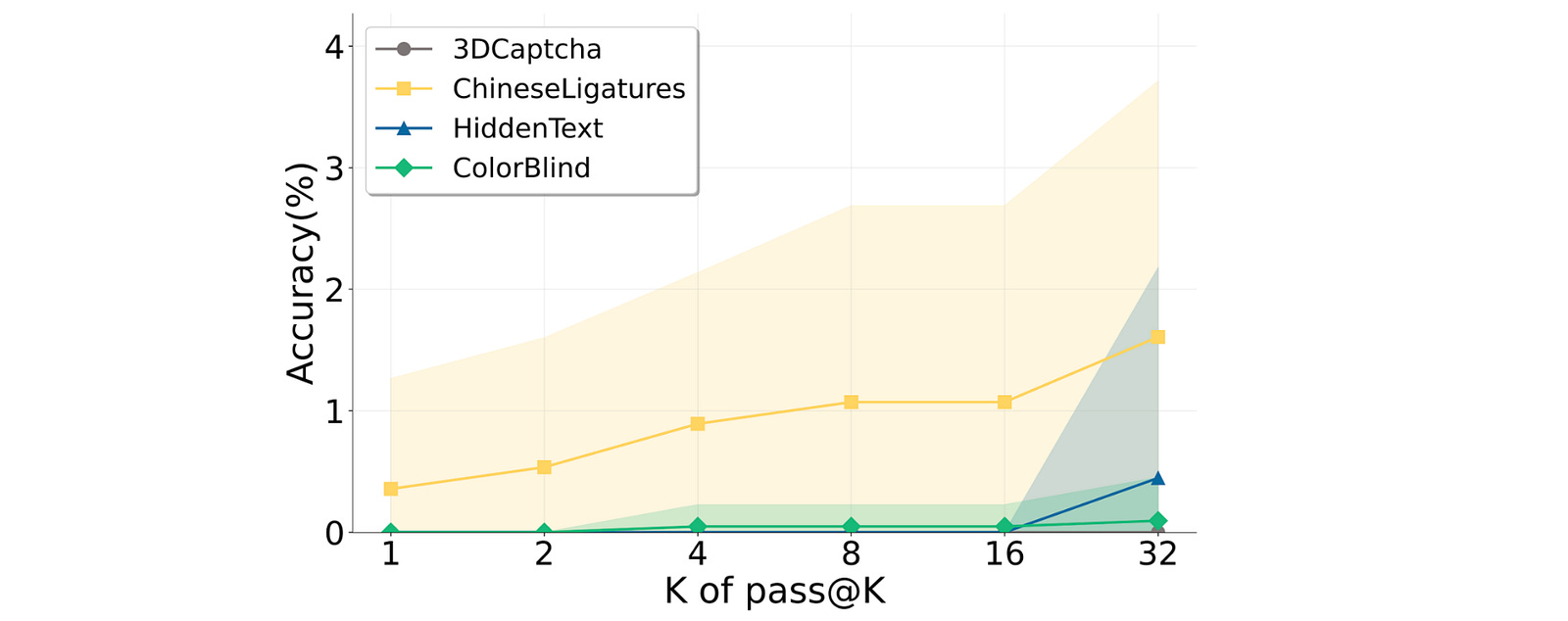
Given that these results are so generalizable across all open and closed-source model architectures, it points towards a fundamental flaw in how current MM-LLMs perceive visuals rather than in their reasoning abilities or answer sampling.

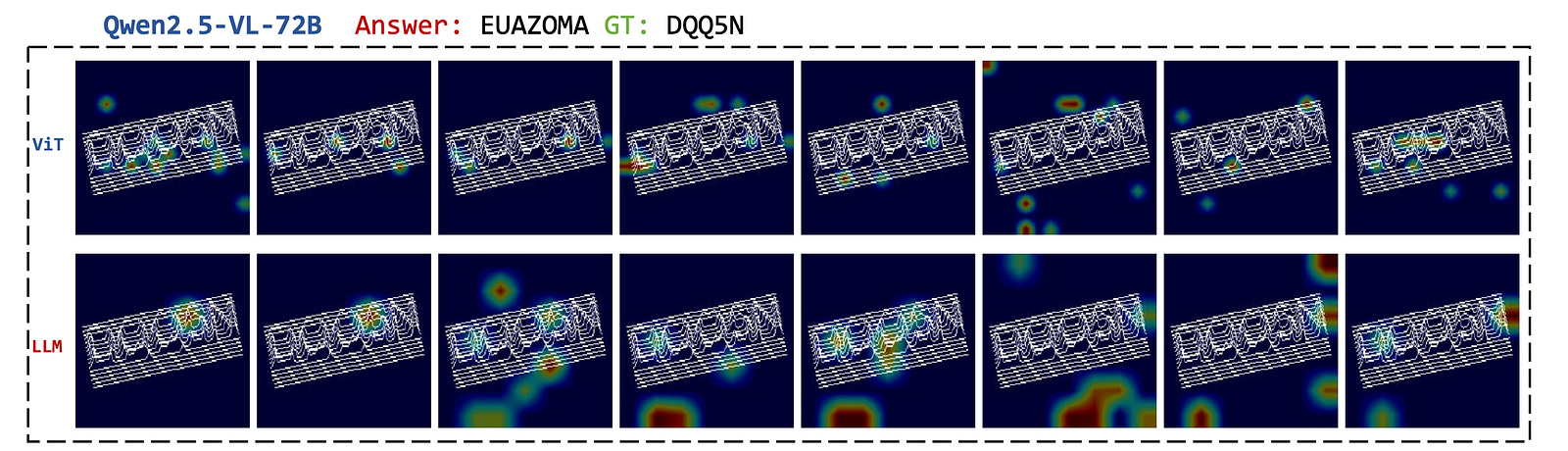
Grad-CAM Reveals Some Serious Flaws In The Models
Grad-CAM is a method used to visualise the heatmaps that highlight the regions in its inputs that were most important for a neural network in making a prediction.
Grad-CAM was initially designed for CNNs used for image classification tasks, but it has been further extended to large vision-language models and similar Multimodal architectures in previous research.
When this method is applied to Qwen2.5-VL, it is seen that the Vision encoder of the model, which is meant to extract meaningful visual features from images, focuses on irrelevant areas or only parts of the correct characters.
This is one of the reasons why the model lacks a global understanding of the images that it is given as input.
Even scaling model parameters does not help here, as both the Qwen2.5-VL 7B and 72B models face similar issues.

Does In-Context Learning Help These Models?
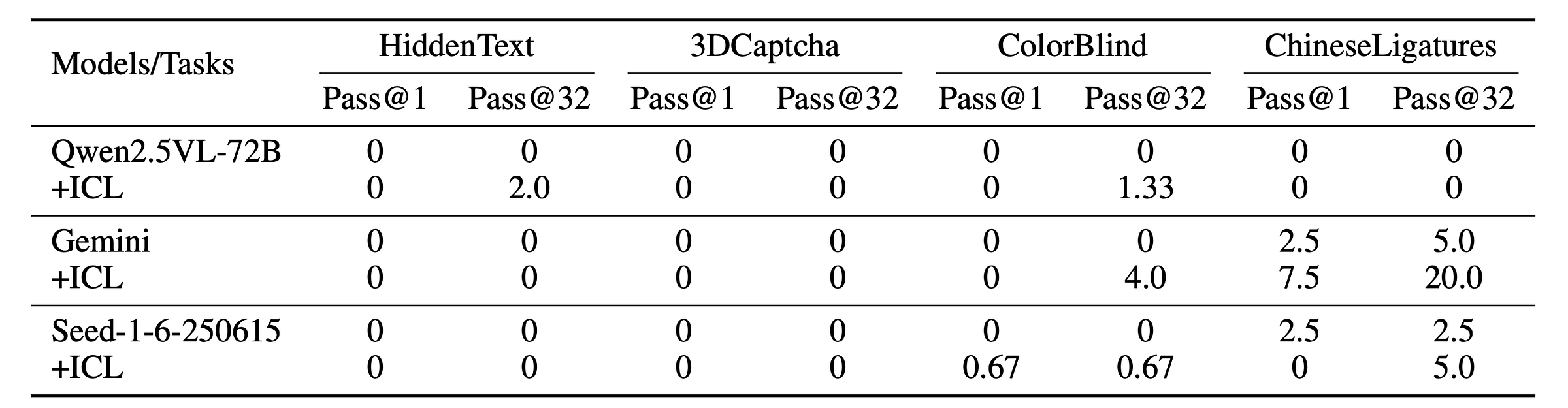
To test whether In-context learning helps the models perform better, for each test image, researchers give a model three image-answer pairs from a dataset as examples in its prompt.
Unfortunately, this leads to no improvement in performance, even for strong models like Gemini and Qwen2.5-VL.
Can Fine-Tuning Save The Models?
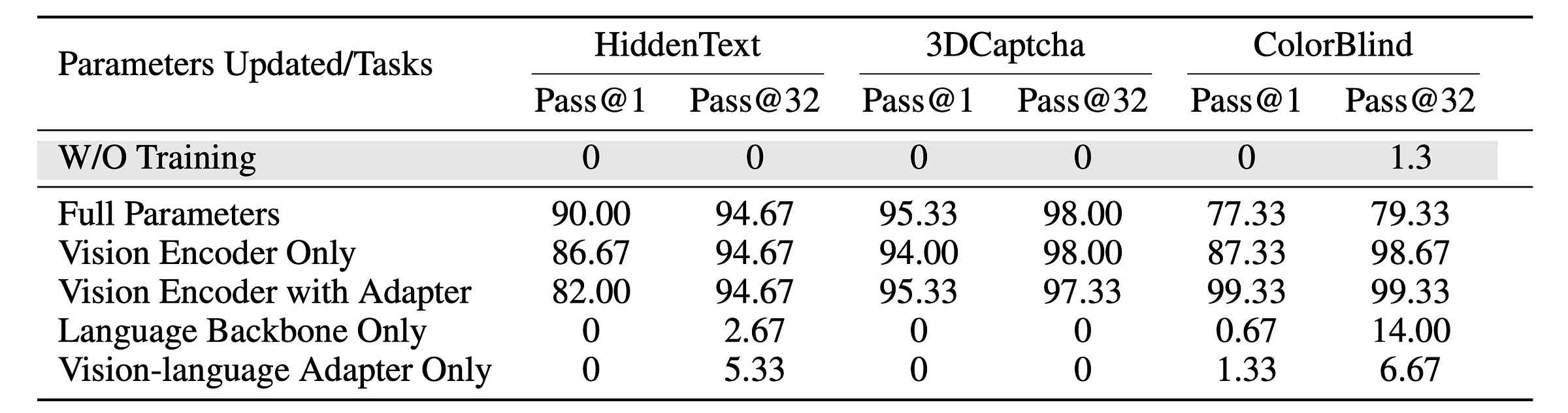
To test whether Supervised fine-tuning (SFT) of different parameters of a model with task-specific datasets might help it to perform better, researchers test five fine-tuning strategies, with each updating different parts of the model.
The results show that updating the vision encoder leads to significant performance improvements for a model, but updating just the language backbone has little to no impact.
This tells that the tasks from the TET benchmark require better visual perception capabilities rather than language knowledge or reasoning improvements.
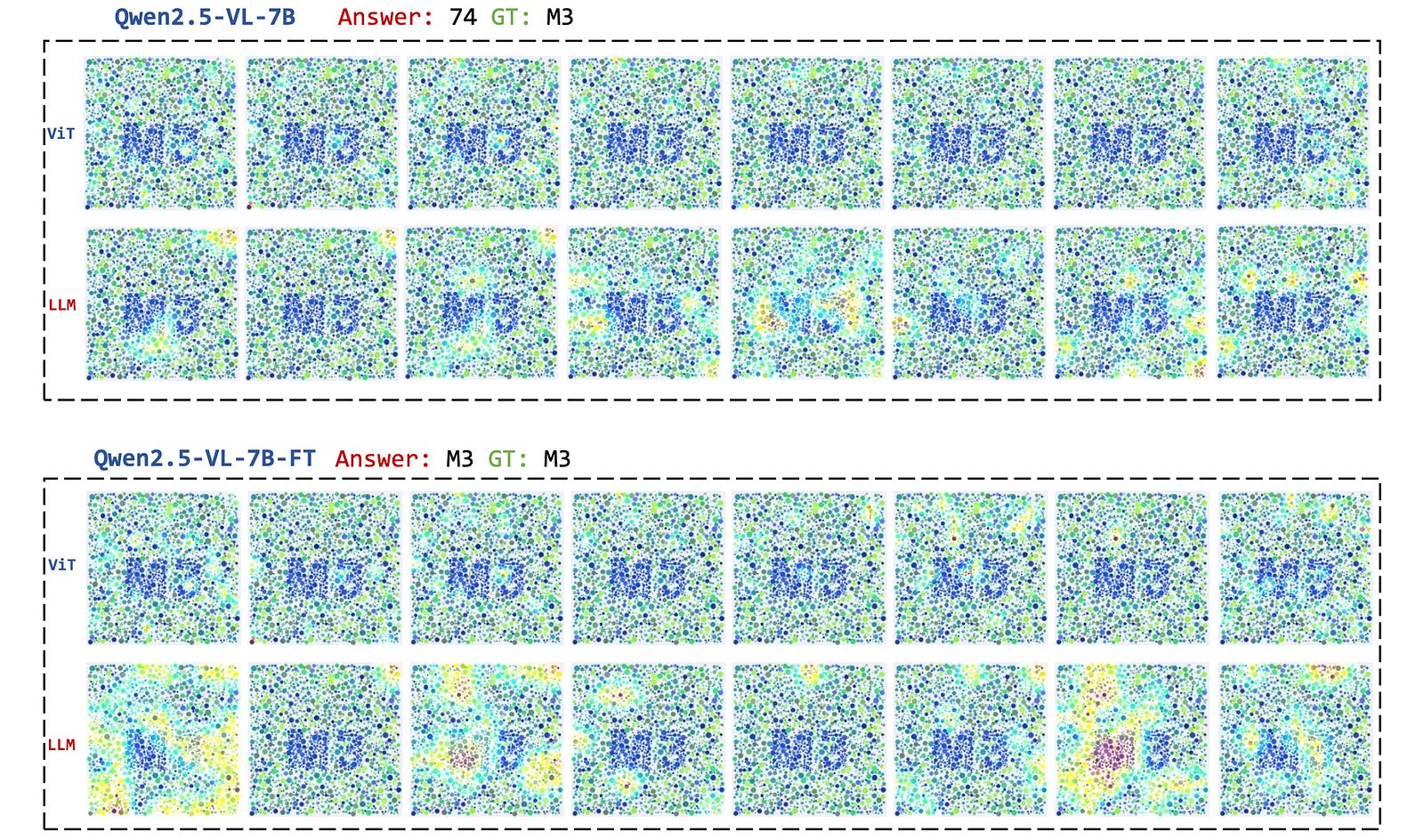
Humans can easily solve trivial tasks like the ones tested in this research, but all current state-of-the-art MM-LLMs have almost zero accuracy on them.
This is a huge wake-up call that these models require a massive architecture shift to really perceive our world and understand how it works.
Till then, it’s all just Pixels and Patterns, but no Poetry.
Further Reading
Source Of Images
All images used in the article are created by the author or obtained from the original research paper unless stated otherwise.
